世界上最遥远的距离,就是你看得见元素,却找不到它。
本篇介绍xpath用法,id、class、name、tagname等等其他常规用法不介绍了。但是有个忠告就是,遵循元素定位大法,尽量少用xpath做定位,除非万不得已,不然你会懂得花儿为什么这样红的, -,-
1、基本语法
可以参考官网上面
表达式 |
描述 |
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配的选择的当前节点选择文档中 的节点,不考虑位置 |
| . | 当前节点 |
| .. | 当前节点的父节点 |
| @ |
选取属性 |
一些特殊用法
| 表达式 | 描述 |
| * | 匹配任何元素节点 |
| @* |
匹配任何属性节点 |
2、xpath定位,以百度为例
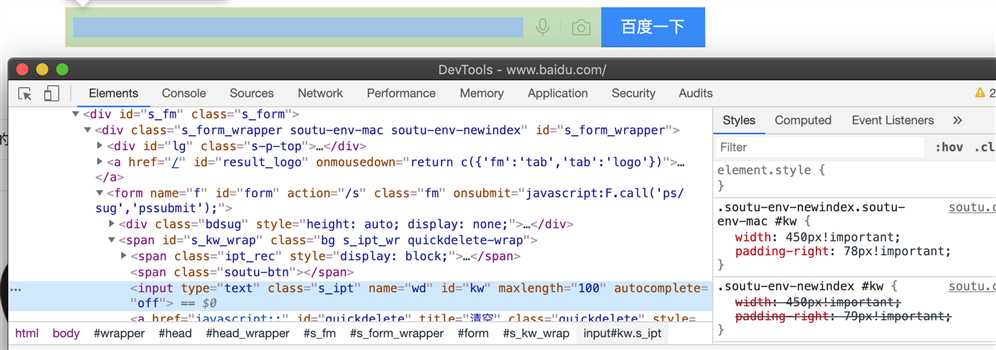
---通过属性定位,//标签[@属性=值]
xpath = ‘//input[@id="kw"]‘,同理,name即为‘//input[@name="wd"]‘,class,包括type等等都可以使用这种方法
from selenium import webdriver driver = webdriver.Chrome() driver.get(‘https://www.baidu.com/‘) xpath = ‘//input[@id="kw"]‘
## input代表在input标签下,@表示寻找id的属性,kw为id的value
driver.find_element_by_xpath(xpath).send_keys(‘test‘)
---通过@text()定位
xpath = ‘//标签名[@text()="string"]‘
这里没有找到好的栗子
一般用法
xpath = ‘//*[@text()="text"]‘
xpath = ‘//*[contains(@text(),"text")]‘
---模糊定位,利用contains()方法定位
contains定位是个很强大的定位方式,至于为什么狂夸这个方法,等你用appium的时候就知道了,后面介绍。下面针对本篇举几个栗子
xpath = "//标签名[contains(@属性, ‘属性值‘)]"
from selenium import webdriver import time driver = webdriver.Chrome() driver.get(‘https://www.baidu.com/‘) ## 通过id模糊定位,*代表从匹配任何元素节点,当然也可以使用其他的属性定位,例如@class,@name xpath = ‘//*[contains(@id,"kw")]‘ driver.find_element_by_xpath(xpath).send_keys(‘kw‘)
---层级定位,也就是如果某一元素没有任何属性可以定位到它,那么就可以去向上找它的爸爸,根据层级关系定位到它,如果它的爸爸也是啥都没有,就去找它的爷爷,还是拿百度来举例,注意时不常的瞅一眼百度的元素图 - - !
xpath = ‘//祖宗标签 /爷爷标签 /爸爸标签/自己的标签‘
from selenium import webdriver import time driver = webdriver.Chrome() driver.get(‘https://www.baidu.com/‘) ## 通过层级关系定位 xpath = ‘//form[@id="form"]/span/input‘ driver.find_element_by_xpath(xpath).send_keys(‘kw‘)
---逻辑运算定位,也就是第一种的方式,加上and ,or等等,我是基本没见过,所以这里也就不记录了,有兴趣可以自己百度一下。
至于xpath最简单的,也可以直接f12,右键复制一下xpath,不过那样子你可能会复制出来一大坨的东西,太长的东西不好看呐。还是一句话,多练习,孰能生巧,你会成功的。到时候不要忘了灵感老师。 - -!
原文:https://www.cnblogs.com/dflblog/p/11426062.html