题目:Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving(自动驾驶)
作者:Yan Wang, Wei-Lun Chao, Divyansh Garg, Bharath Hariharan, Mark Campbell, Kilian Q. Weinberger
论文链接:https://arxiv.org/abs/1812.07179
项目链接:https://mileyan.github.io/pseudo_lidar/
代码链接:https://github.com/mileyan/pseudo_lidar
1)核心观点:基于视觉得深度检测效果不好,很大程度上是因为数据的表达形式,也就是格式选择不对。(这篇的角度很新颖很奇特,因为还是网上没什么参考资料,就又自己强行翻译理解了)
2)使用雷达$相机做3D车辆检测的优缺点与区别:
雷达:
相机图像:
基于图像和基于雷达的3D检测,在思路上的主要区别(存在个人理解,存疑):
3)本文算法:
思路:
流程图:
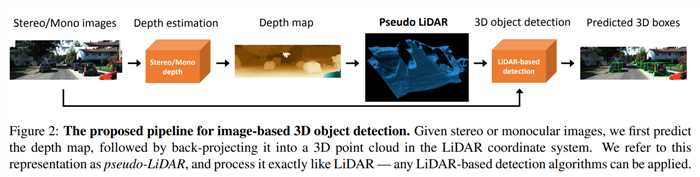
深度估计:本文算法与深度估计部分无关,这里可用单目深度估计或者双目深度估计,本文采用双目深度。
双目深度估计输入一对左右图像Il,Ir,输出与任意一图像大小相同的视差图Y(disparity map)。本文假设左图为参考图像,并在Y矩阵中存每个像素相对于右图的水平视差。由下式得到深度图:(其中fU为左图的水平方向的焦距)
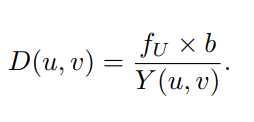
生成Pseudo-LiDAR数据:
在左图的相机坐标系中为每个像素(u,v)反投影的到3D坐标(x,y,z):((cU,cV)是相对与相机中心的像素位置,fV是垂直焦距)。将所有的像素点都反投影到3D坐标,得到3D点云{(x(n),y(n),z(n))}Nn=1(N为像素数目)。
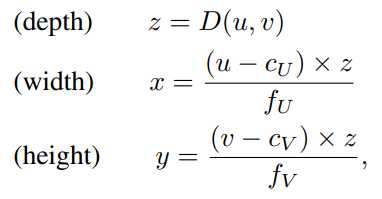
LiDAR vs. pseudo-LiDAR:因为后续是要和雷达信号做对比,这里对伪雷达信号做了些额外的处理:

3D目标检测:
有了伪雷达数据就可以用任何一种基于雷达的3D检测算法检测啦。本文采用单目图像+LiDAR的方式,采用两种方式处理pseudo-LiDAR数据,baseline选用了AVOD和frustum PointNet:(这两个baseline我都不了解,文中的简单解释也不太能理解来,这里不多说了吧)
数据表示形式至关重要:
尽管pseudo-LiDAR和深度图中是相同的信息转化而来,但是本文主张数据的存储格式直接影响了基于卷积神经网络的3D目标检测的性能。
卷积神经网络的核心模块是2D卷积,卷积神经网络在处理深度图像的时候是进行一系列的2D卷积操作,虽然卷积核的参数是可以学习的,但是核心假设有两个:
这些假设确实需要,但并不完善,现有的2D检测器在遇到这些假设不成立时常常会崩溃。
相反,点云上的3D卷积或者BEV视角上的2D卷积在物理上自然靠近(尽管BEV会将不同高度的像素堆叠到一起,但是这些像素通常你都属于同一物体,不影响)。这样,远处物体和近处物体可以用完全相同的方式处理,这些操作本质上更具有物理意义,自然地可以得到更精确的结果。
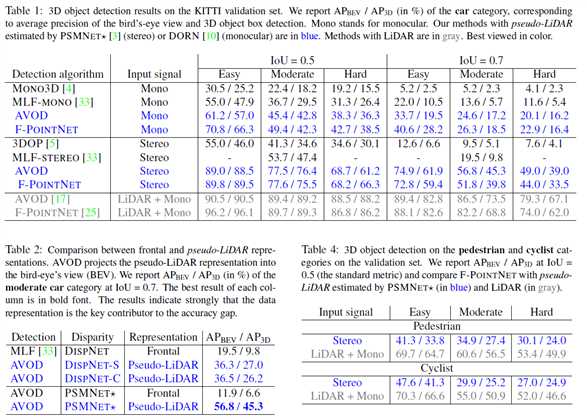
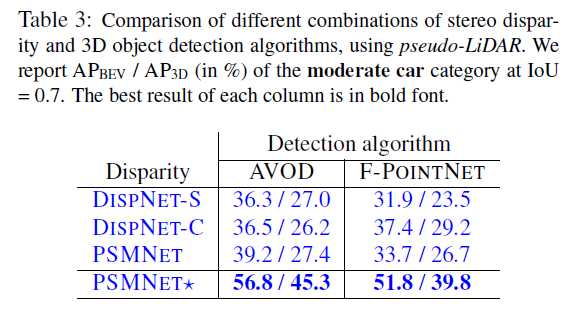
4)结果
实现细节多又繁琐,不多说了吧,这里给出实验结果好了,看起来性能还是不错的。
3D目标检测之图像深度转为伪雷达信号:Pseudo-LiDAR from Visual Depth Estimation --by leona
原文:https://www.cnblogs.com/bupt213/p/11423247.html