Machine_Learning MIT
??????上一篇note是Shah教授的Lead_in,而这一篇note就将进入Lecture1的highlight——Regression和和Classification。注意本篇内容虽不涉及Neural Network神经网络,但也体现了一些类似的思想看NN内容的同学请移步Lecture3的相关note。
??????而在接下的部分中,我们将讨论ML的Supervised Learning。而ML一般由Supervised Learning、Unsupervised Learning、Reinforcement Learning三部分组成。

??????回归是进行建模的重要方法。它的基本目标就是通过输入原有的属性,进行模型构建,然后通过于原有输出对比,来修正模型。通过多次的修成,就能得出具有一定预测能力的model。
关于这个部分,下文将按照如下结构进行阐述:

??????Shah教授在Lecture中介绍了这样一个例子:
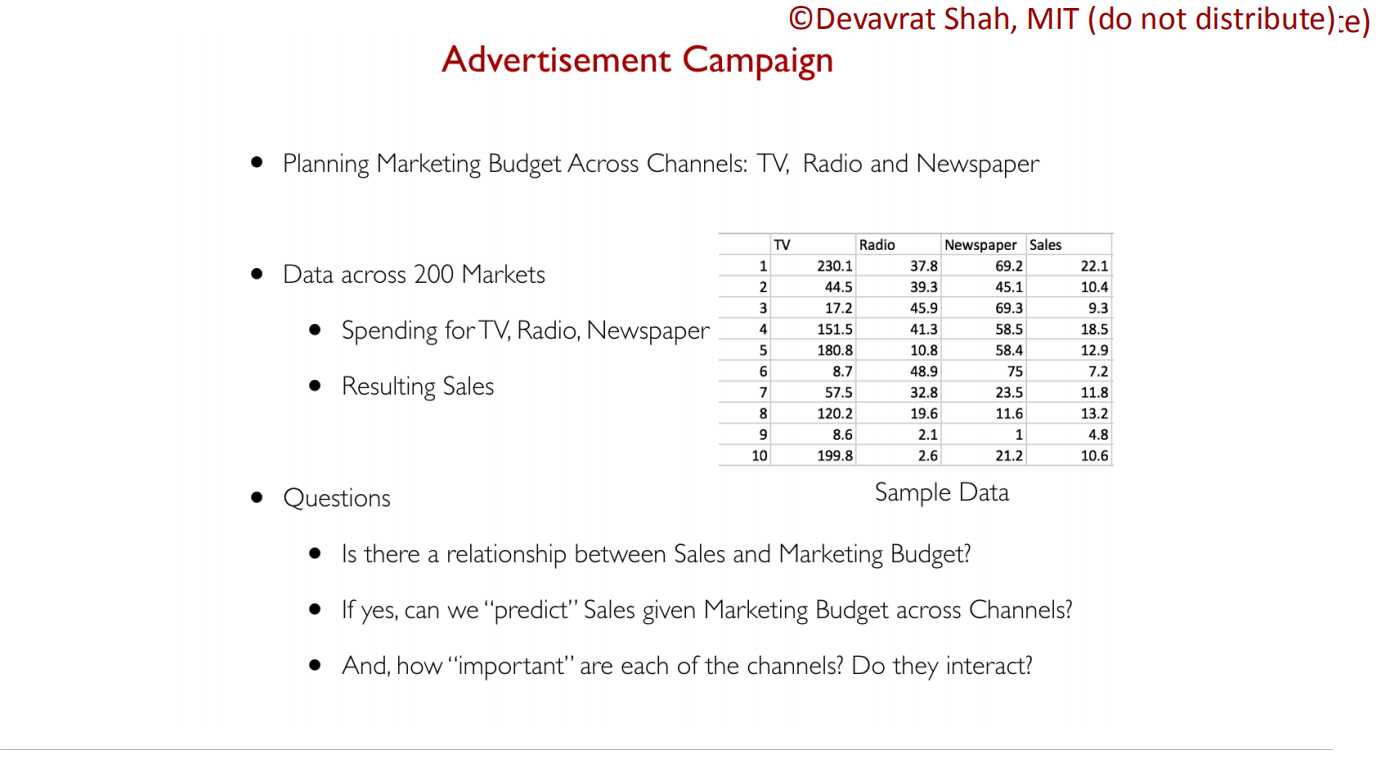
??????也就是需要我们构建一个销量与不同广告平台(TV、Radio、Newspaper)的数学模型。
??????从dataset可以看出,所有广告平台都会影响销量,而且每种影响的性质和程度都不一样。
??????为了研究这个模型,我们就需要先使用简单的线性回归进行研究。

由于线性回归比较简单(记得是好像是高中的知识了),我这里就简要说明一下(Shah教授直接跳过了上面那一页)
??????我们先定义线性方程真实输出量y,又定义输入特征向量x,那么,我们的goal就是要找到一个映射f,使f能表示x到y的映射。由于我们并不也并不可能知道所有数据,我们获得的映射f是一种估计,这就需要我们f的error尽量小。所以我们定义error方程为y与模型输出f(x)的差值,又为了消除正负影响,又加上平方,最后是通过极小化error来修正model。
??????通过上面的方法,我们就能初步建立起一个简单的线性回归模型。
??????假设我们获得的模型如下:
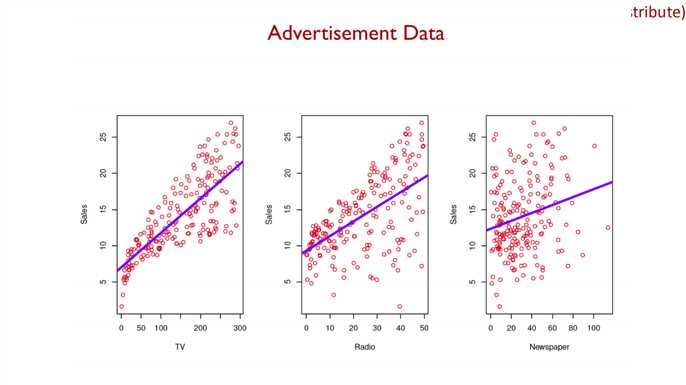

??????从上面的结果可以看出,Newspaper基本没有作用,甚至会有消极作用;TV和Radio都有积极作用,且Radio作用更加明显。
??????表明上我们获得了一些结果,单这一结果是非常粗糙的,我们更没有进一步严谨的讨论:TV和Radio平台的广告是否会相互影响呢?是否会有相互促进作用呢?
??????在对结构进行进一步讨论前,我们先对我们的模型进行量化评估。


??????有一件麻烦事情的就是过拟合,也就是model训练得过于拟合训练数据(也就是上文的x),导致预测未知情况的泛化能力较差。
??????综合以上情况,我们将采取一种新的训练方式——Cross-validation(交叉验证法)。也就是将训练数据拆分成n组,每次训练都只选取其中n-1(或更少)的数据组作为训练集即x,进行训练;而将剩下的数据组当做测试集即y进行模型修正。当然这里的error会做一定的修改。当n = 2时,error会由2部分组成:第一部分是在训练集训练时,由测试集评估出的error1,;第二部分是将由测试集进行训练,然后由训练集评估出error2,最终的error会是所有error_n的平均值。类似的,当n = n1时,error会由n1部分组成(这里仅成立于训练集为n-1组,测试集为1组)。
??????针对上面的方法,这里有必要做一点说明,我们使用交叉验证拆分出训练集和测试集,这并不意味着测试集就会只用于测试,如果那样做的话,我们宝贵的数据就丢失了,但为了防止每次训练时过多数据参训练与而导致过拟合,我们只好让一部分数据暂时休眠(dropout),而在下次训练时,额外加上测试集;而当所有组都参与训练后,再更新error。这样可以保证error函数不会将数据引导向过拟合方向。(这样的方法同样适用于neural network的训练)
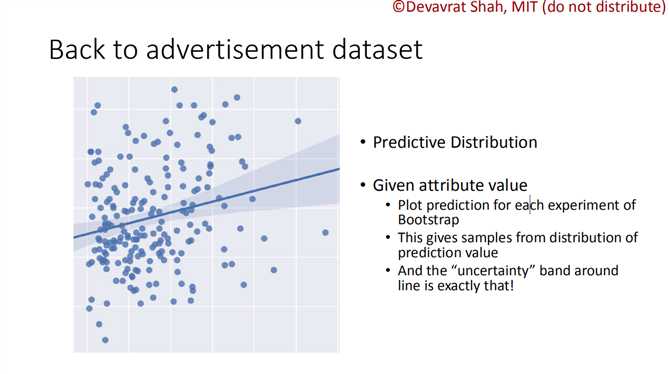
??????从上图可知,我们初步得到的模型的各个参数值。但是我们难以从这冰冷的数字中感性地认识我们model的好坏(相较于参数w,r的真实值)。这就是Uncertainty Quantification(不确定量化)问题。由于缺少对比,我么不知道r=0.897的优劣程度,我们也不知道w = -0.001的影响程度到底有多小。

??????Uncertainty Quantification问题还体现在可信度问题。我们训练出了一个模型,但是我们到底能相信这个模型几成呢?或者说它90%置信空间在哪里呢?
??????为了解决上面的问题,我们尝试Bootstrap(引导)方法

??????Bootstrap方法就是为了解决这种不确定量化问题。而这种方法的核心就是利用分组,使少量的数据能“进行多次实验”,即是使用相同的数据创建多个样本——Create multiple samples out of the same dataset!!
??????下面是Bootstrapd的常见方法


??????首先,我们拥有n个data point,我们将创建k个(参数采样)实验,每次实验都随机选择data point做训练集。当然,对于大数据集,我们可以每次随机选用选择部分(例如80%)的数据。
??????之后,我们分被进行实验,由于训练集的不同,会获得不同的参数(w值),这些w值都是采样值,由此我们可以得到参数(w值)的分布。
??????最后,由分布获得参数的standard deviation(标准差)。可以通过标准差估计参数真实值的大致分布。
??????对于这个例子,我们很方便地得到如下结果:

??????从上面的结果可以看出,Newspaper的标准差较小,所以其影响确实低于前两者。而可以看出Radio的影响最大。
??????至此,这个简单模型初步研究完成,并得出初步结论:Radio是影响sales的最重要因素,其次为TV,而最后的Newspaper影响微弱。
??????上文中,我们简单地将Newspaper、Radio、TV分开,这就默认了这三个变量相互独立。然而事实显然不是这样的,当你在多平台进行广告宣传,效果可能会好于单平台宣传。而data set中的数据也正是多平台的效果。所以,上面的简单模型需要做一定的修改(非线性修正)
??????通常这种做法有很多,例如将data取log,以将其中的非线性关系线性化。
??????这里,Shah教授给了个新颖的方式:

??????我们可以将TV * Radio作为变量输入模型,这样就包含了这两个的interact。而模型反馈的r值也高达0.967!
??????至此,Linear模型分析到此,这个模型简单易上手,但是若要获得变量之间的interact或是其他内在联系,此模型能发挥的能力就非常有限。
模型结论(当然结论仅适用于给定的data-set)


??????Classification类似于Regression,他们仅有的区别就是,Classification的输出变量是类别(class),即离散变量
??????下面是这部分Lecture的Agenda。



??????Classification有个经典的例子,那就是MINIST,也就是手写字母识别。

??????第二个例子就是垃圾邮件过滤器,如何识别垃圾邮件(短信),当然这也同样涉及了自然语言处理。
??????第三个例子就是甄别恶意网络连接。

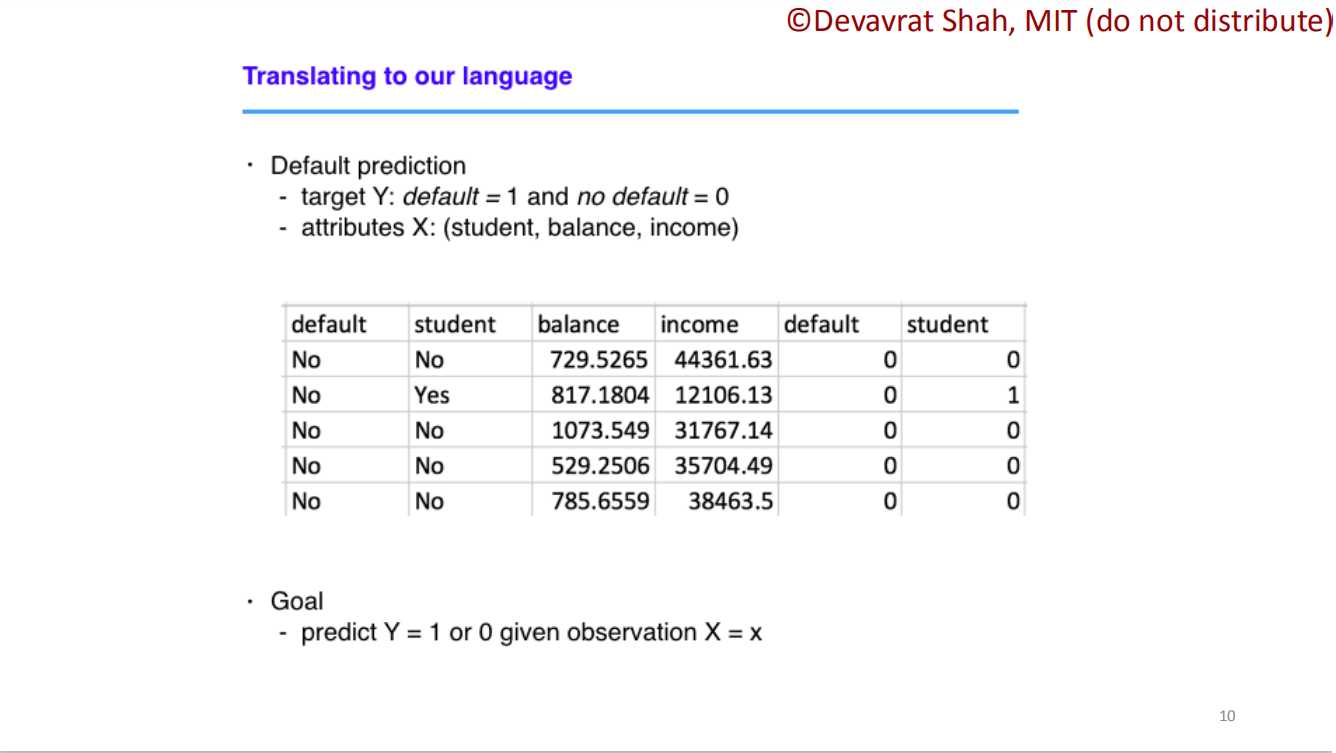
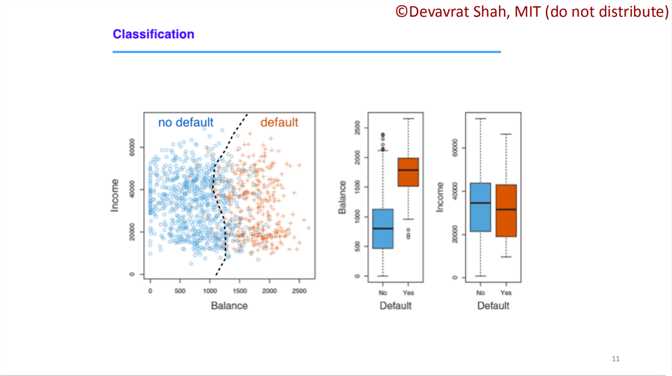
??????第四个例子就是预测信用违约。这里Shah教授给出了简单的建模过程。首先给出了样本数据,之后进行模型训练,注意,这里的的模型不再是线性,要使用下面介绍的逻辑回归进行曲线拟合,最后得到一个分界线。

??????在下面的逻辑回归中,我们将重点介绍理想分类器——Bayes(贝叶斯分类器)。同时也将简要解释为什么线性模型在分类问题表现不佳

??????这里我们先讨论二元分类(即仅有0和1),在Bayes分类器中,我们将按照事物为正反例的概率进行分类。(正例概率$P(Y = 1|X = x)$,反例概率$P(Y = 0|X = x)$)。这里做个说明,一般情况下,正例概率大于反例概率时会分为为“1”,反之亦然;但在特殊情况下,这一规则会做一定的调整。


??????从上面的结果可以看出,如果我们贸然用概率期望套用线性模型,得到的结果会不尽人意——总是分类到“0”!
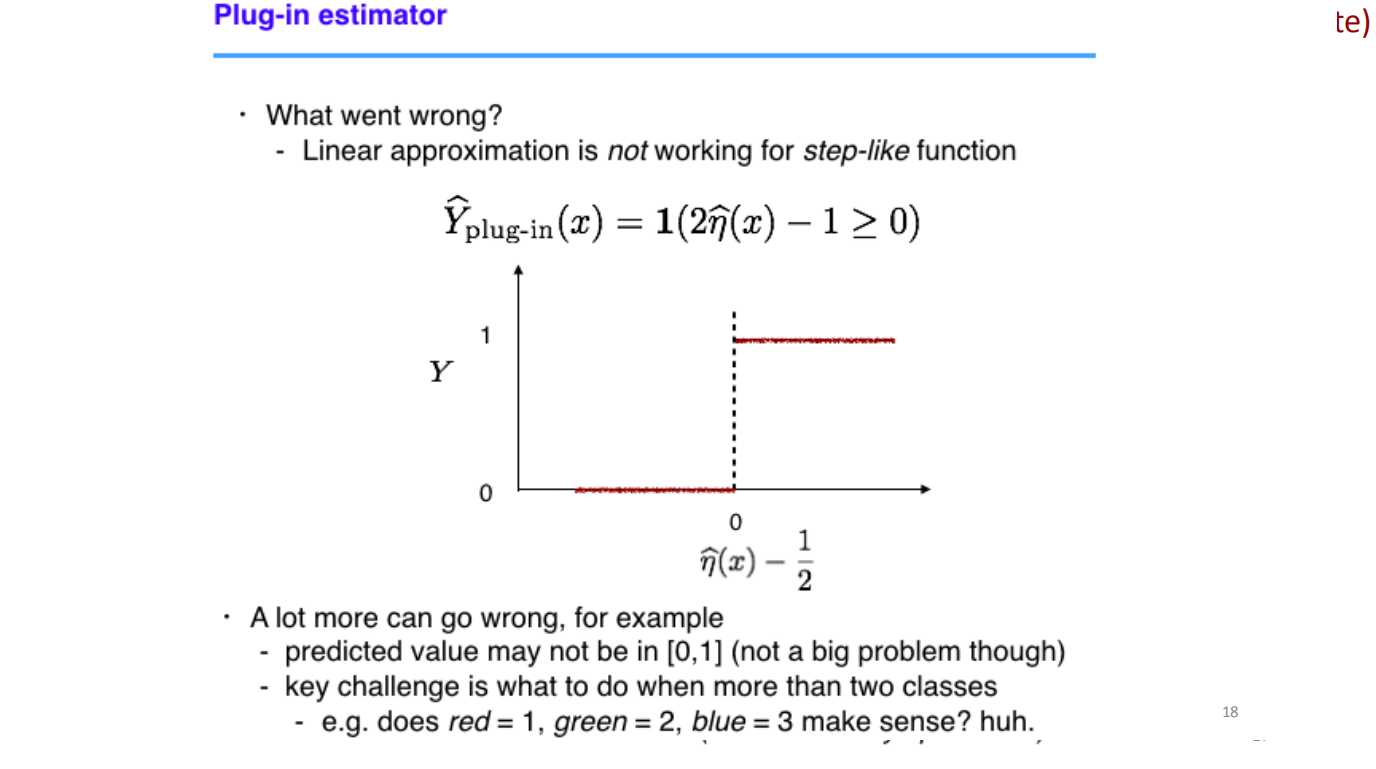
??????从上面我们可以看出,线性分类处理类阶跃函数的模型时会非常“吃力”,原因就在于这类函数微分的特殊性。导致w值会异常偏大(或偏小),从而导致样本值对预测值影响较小。于此同时,在本例之外,线性模型还可能会收到离群值(偏离集群的值,多半是误差极大的点)的影响。不经如此,线性模型对多分类问题会显得更加吃力,每增加一维,模型的泛化能力会受到更多挑战。
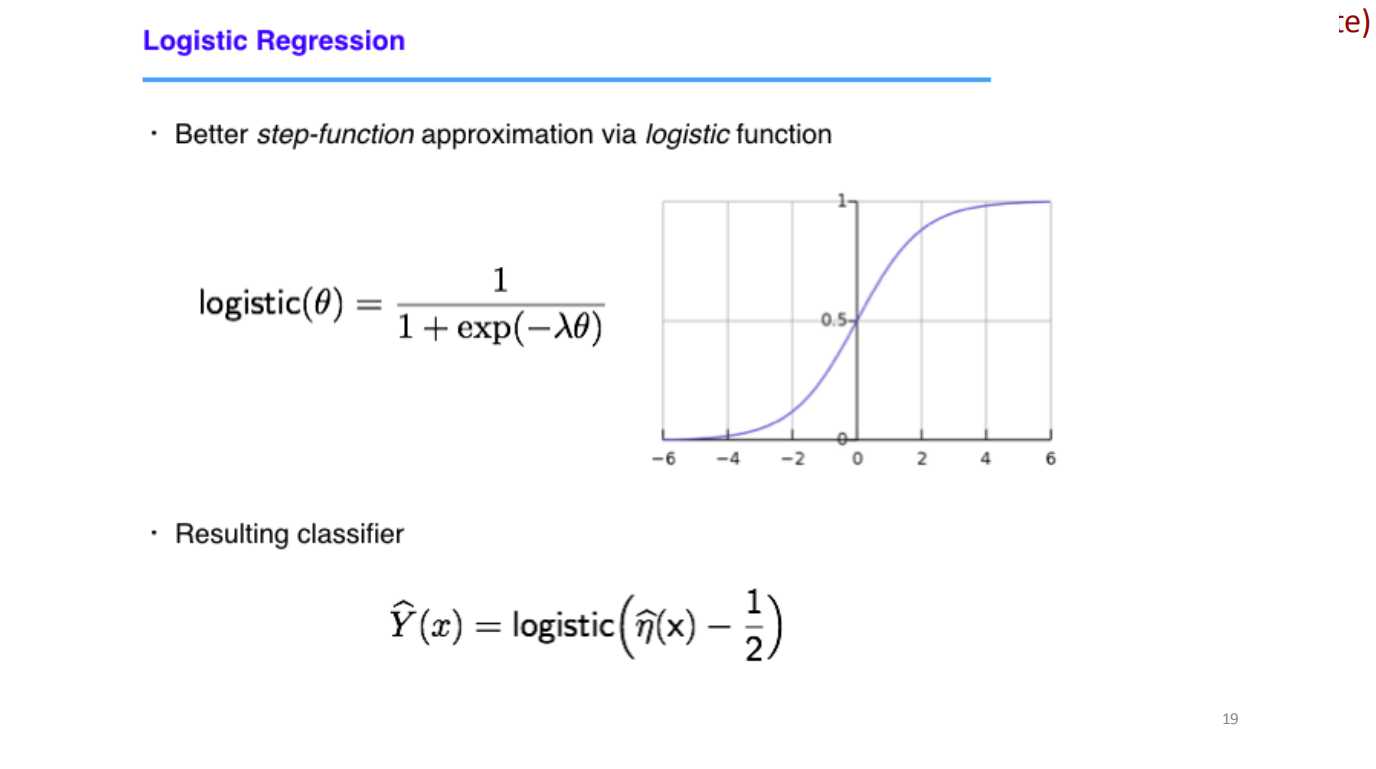
??????为了解决这个问题,我们将使用一个非线性模型——sigmoid函数,关于这个函数的详细介绍,可以参考这篇文章。





??????我们引入了概率作为分类的依据,我们就想通过概率论的知识解决问题。在第一张slides中,我们使用对数方法,巧妙将正概率转化为线性(这里的log方便后面sigmoid函数的转化)。而在第二张slides中,我们将所有样本预测正确的概率累乘,这样可以使用极大似然估计,逼近线性参数。当然,我们难以通过求导来直接解决极值问题,我们就使用梯度下降的方式逼近极值。
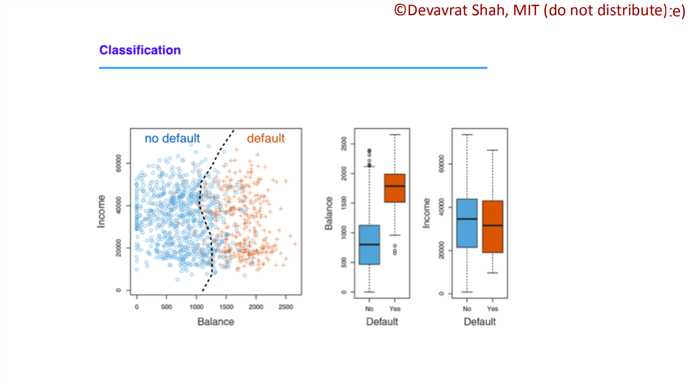
??????我们将数据代入分类模型之中,得到了上图的结果(上文的第四个例子)。在slides中还有线性模型和sigmoid的对比,虽然直接结果不太明显(错误率3.33% vs. 2.73%),但仍能看出部分提升。
??????目前为止,我们只针对“正反”两面进行分类,然而实际情况下会有多种属性(输入维度),和多种特征(输出维度)。这时候,我们仅需将输入和输出换成矩阵形式就好。

??????类似地,在线性模型中,我们说到了过拟合问题,同样我们在训练逻辑回归模型也需要处理这一问题。不过,由于我们这里样本量较小,因此采用正则化的方式扩充样本量(Regularization)。正则化主要是在梯度更新的时候加入惩罚项,一般有两种方法:一是$w$的累加,通常做特征选择;二是$W^2$的累加,通常做放过拟合。具体参见这篇文章。

??????以下部分讨论两类error,positive error和negative error。

??????从图中我们可以看出,positive error是真实值为1,但预测值为0;相反,negative error是真实值为0,但预测值为1。
虽然我们在算总error时,是将两类error相加。但在处理某些实际问题(癌症检测、条形码匹配)等问题上,我们会侧重于不同的erro(条形码检测可以重复多次,故希望单次误测匹配的情况减少。)

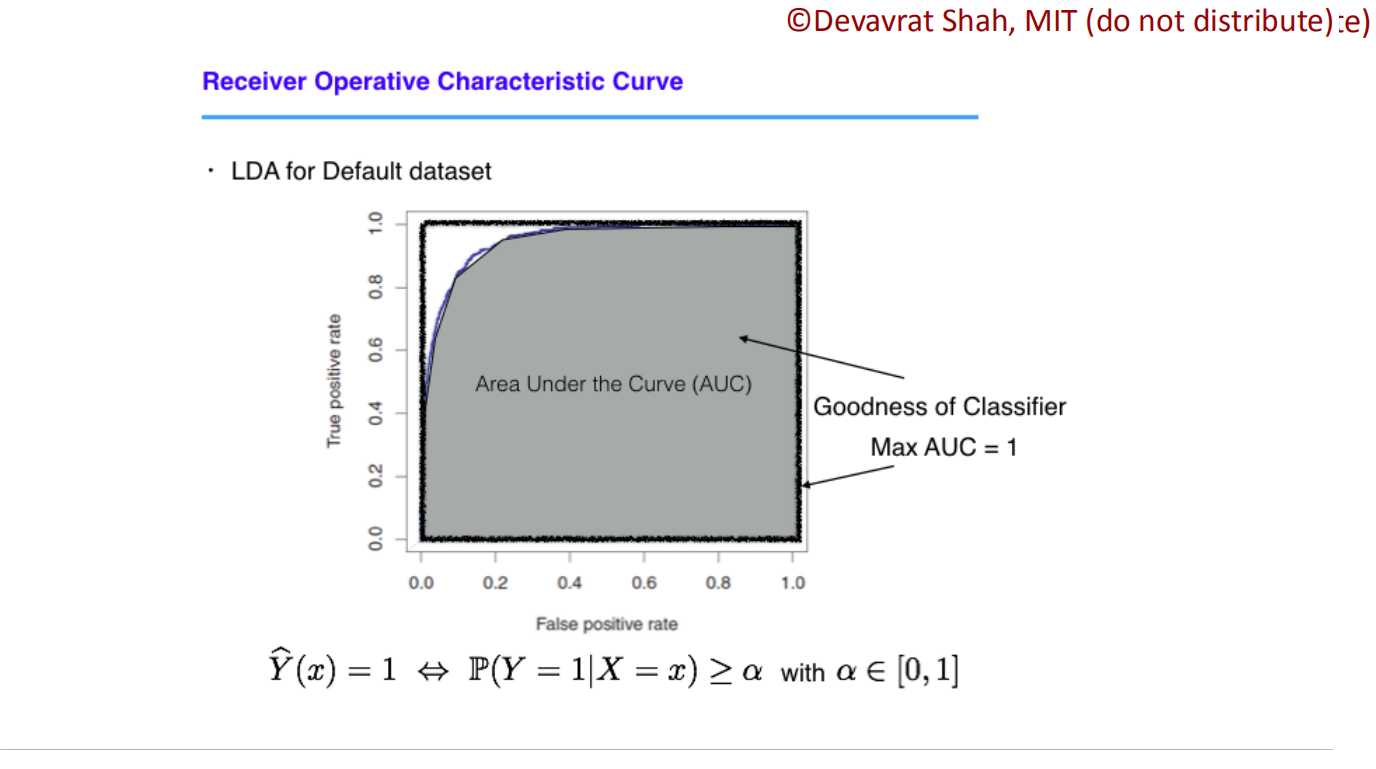
??????这时候就需要调节我们判定的阈值了,即正例概率和反例概率的阈值。我们可以通过绘制地ROC曲线进行观测,并选取合适的erro值。
Machine Learning-note(1.2)--Prediction/Supervised Learning
原文:https://www.cnblogs.com/mingsam/p/11390641.html