这个破东西,折腾了快1个小时,网上的教材太乱了。
我解决的主要是windows的问题
先下载exe。(一看到这个,我就有种预感,不妙)
https://digi.bib.uni-mannheim.de/tesseract/
选好自己的机型,
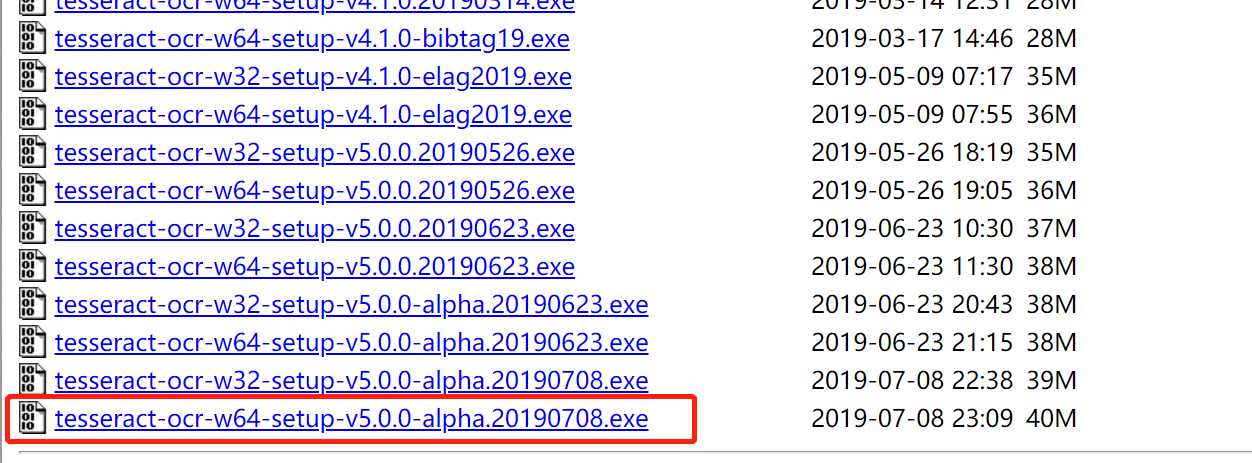
最新版的,可能会采坑啊
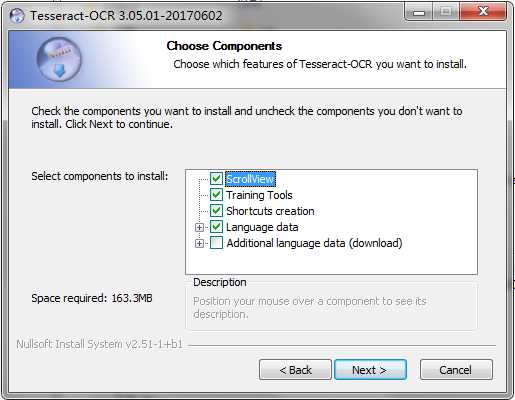
安装时可以添加支持的语言包,如下界面最后一个选项点开选择,我们可以选择简体中文 Chiness(Simplified)。多选几个吧
然后下一步。
完成后,添加环境变量
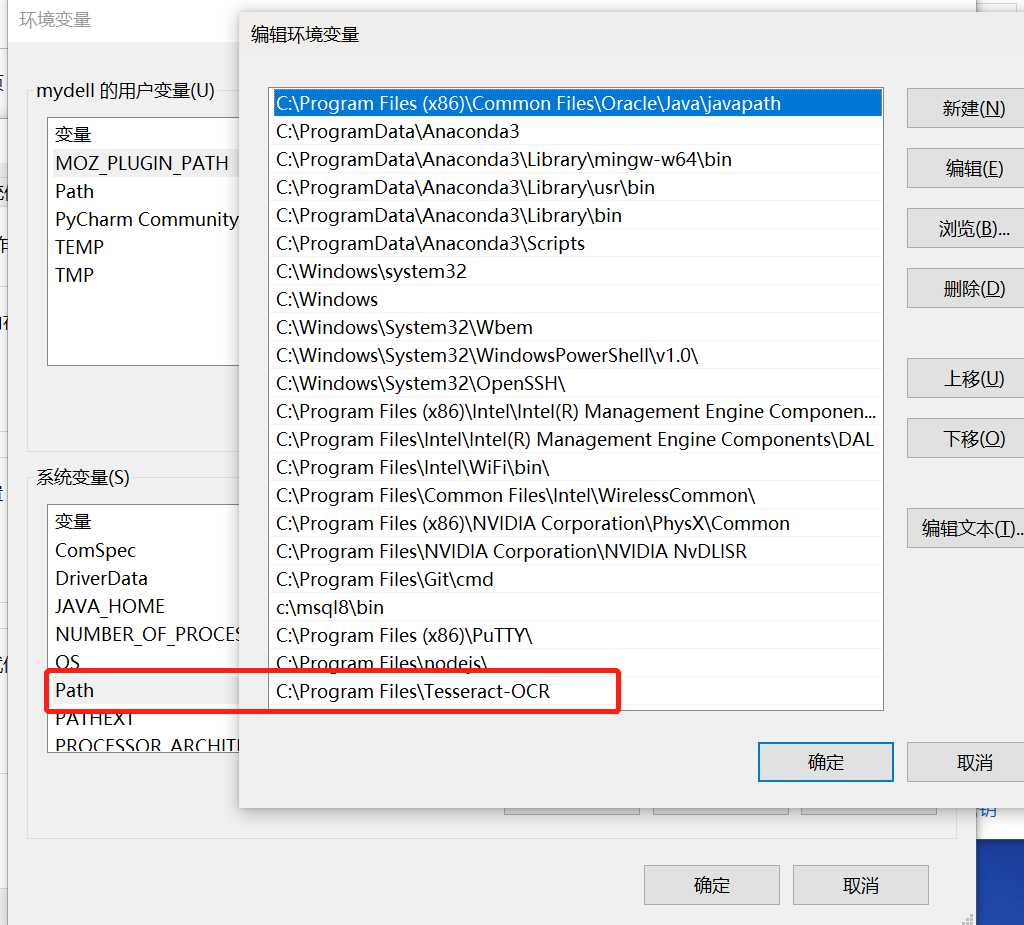
第一个环境变量
再配第二环境变量
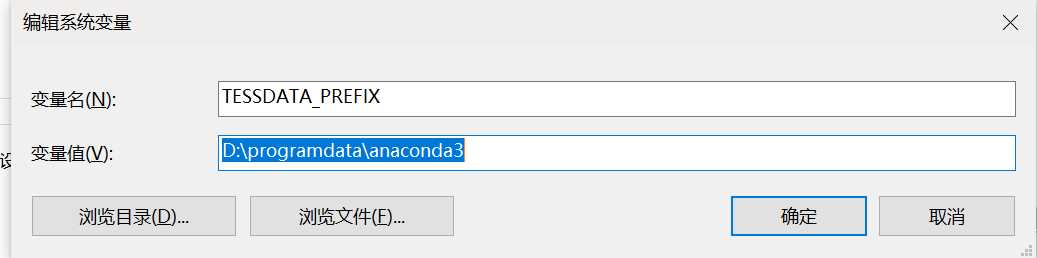
我的机器运行提示要在这里找tessdata
Failed to init API, possibly an invalid tessdata path
就从安装目录下,直接把tessdata 文件夹里的内容都复制到
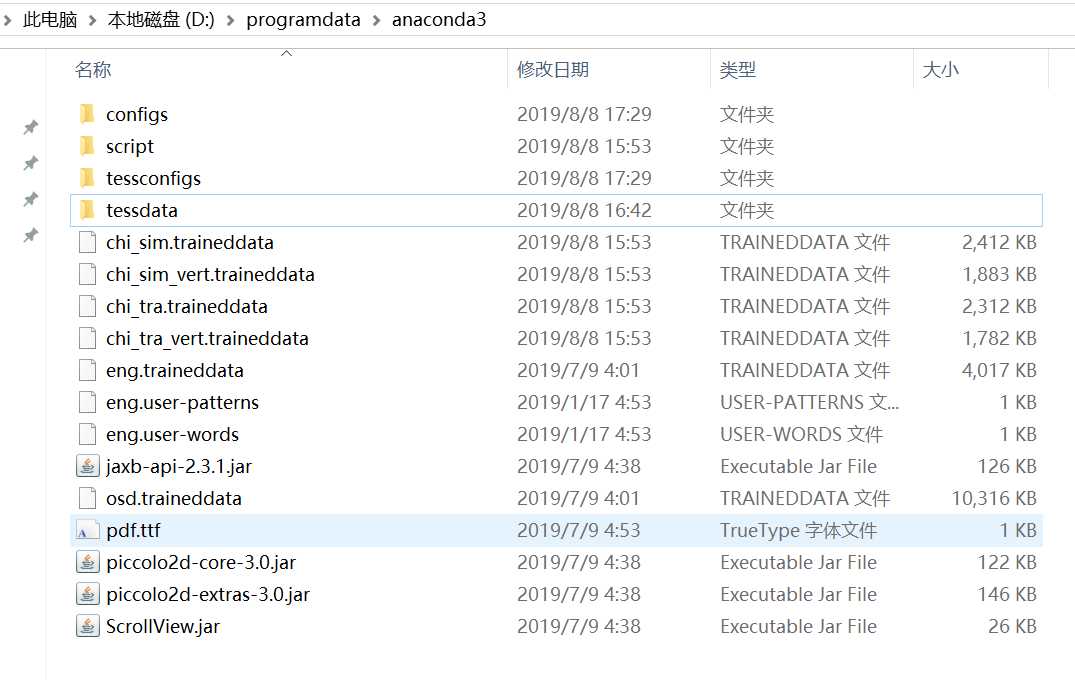
不要问为什么, 这个缺德软件 就这样
下一步安装
pip install tesserocr pillow
如果提示c++什么的,不要安装,使用
如果通过 pip 安装失败,可以尝试 Anaconda 下的 conda 来安装:
conda install -c simonflueckiger tesserocr pillow
亲测有效。
还有一种办法,我没试过,应该也可以
我的解决办法是:在这里下载对于的.whl文件
下载地址:https://github.com/simonflueckiger/tesserocr-windows_build/releases
我下载的版本为:tesserocr-2.2.2-cp36-cp36m-win_amd64.whl (注意版本号啊)
将文件复制到c盘中进行安装

最后一步
pip install pytesseract
最后上代码
import pytesseract from PIL import Image image = Image.open(r‘d:\image.png‘) result =pytesseract.image_to_string (image,lang=‘eng‘) print(result)
亲测有效啊!!
python ocr中文识别库 tesseract安装及问题处理
原文:https://www.cnblogs.com/duoba/p/11322692.html