首先这是一个模块 re 使用之前需要导入 import re
里面包括很多的定义函数,功能很强大,主要用于字符串的搜索,查找,匹配
什么是正则表达式(what):
正则表达式(regular expression)定义:
正则表达式是一个特殊的字符序列,它能帮助你方便的检查一个字符串是否与某种模式匹配,
描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等
怎么创建正则表达式(how):
起初真是被这么陌生高大上名字给弄晕了,其实:
构造正则表达式的方法和创建数学表达式的方法一样。也就是用多种元字符与运算符可以将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个的字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。就是因为各种字符不同的结合方式,可以来告诉计算机怎么查找,匹配string是我们所需要的字符串
正则表达式是由普通字符(例如字符 a 到 z)以及特殊字符(称为"元字符")组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
这些字符主要包括四个部分:
普通字符:
普通字符包括没有显式指定为元字符的所有可打印和不可打印字符。这包括所有大写和小写字母、所有数字、所有标点符号和一些其他符号。
非打印字符:
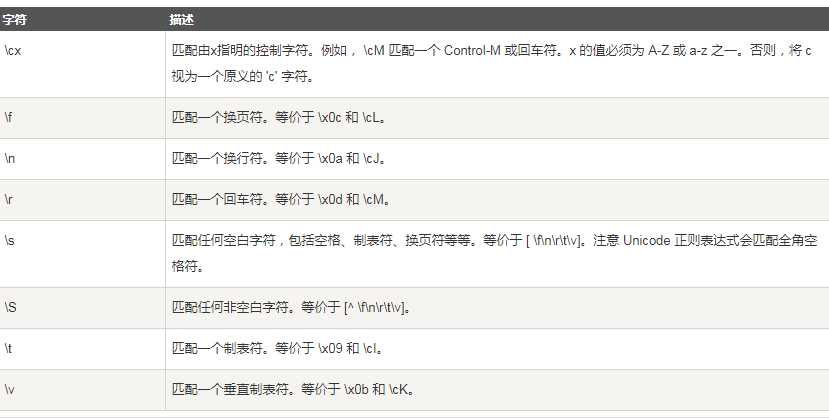
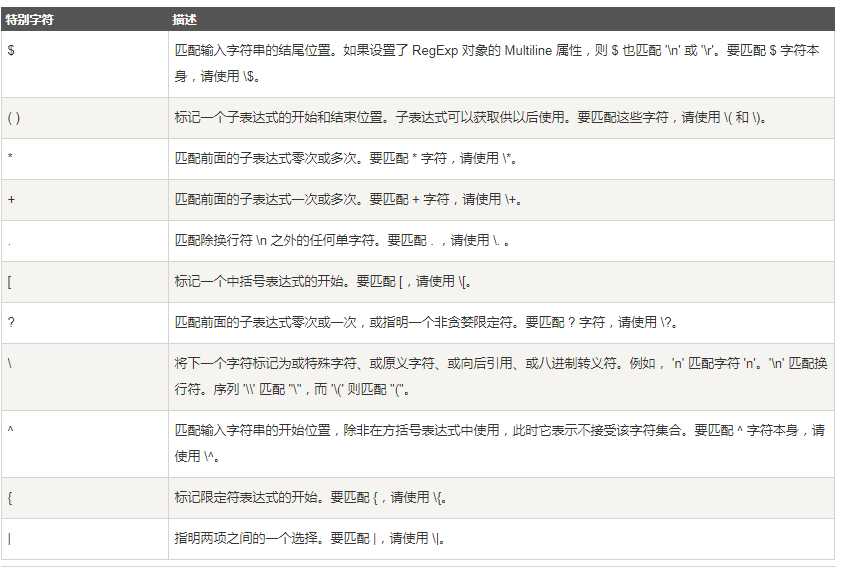
特殊字符:
所谓特殊字符,就是一些有特殊含义的字符,如上面说的 runoo*b 中的 *,简单的说就是表示任何字符串的意思。如果要查找字符串中的 * 符号,则需要对 * 进行转义,即在其前加一个 \: runo\*ob 匹配 runo*ob。
许多元字符要求在试图匹配它们时特别对待。若要匹配这些特殊字符,必须首先使字符"转义",即,将反斜杠字符\ 放在它们前面。下表列出了正则表达式中的特殊字符:
限定符:
限定符用来指定正则表达式的一个给定组件必须要出现多少次才能满足匹配。有 * 或 + 或 ? 或 {n} 或 {n,} 或 {n,m} 共6种。

这些不用全部现在全部记忆下来,很难记住,尝试大胆使用,按照自己的要求,尝试组合字符构建正则表达式,不断改变正则表达式,达到自己切分目的后,理解比较各种切分字符组合含义,再记忆,有些看起来功能相同,能处理达到自己要求,实际隐藏的作用也就没必要探究了。
各种函数:
re.match(patten,string,flags)(pattern=正则表达式,string=需要处理的字符串,flags=标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。)
尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
我们可以使用group()或groups()匹配对象函数来获取匹配后的结果。
。。。
刚才知道有一个可以取代正则表达式的库。。小白卒
原文:https://www.cnblogs.com/kkouba/p/11218609.html