正则就是用来筛选字符串中的特定的内容
正则表达式与re模块的关系:
1.正则表达式是一门独立的技术,任何语言都可以使用
2.python中药想使用正则表达式需要通过调用re模块
正则应用场景:
1.爬虫
2.数据分析
正则字符:
| 元字符 | 匹配内容 |
| . | 除 换行符 以外的任意字符 |
| \n | 换行符 |
| \w | 字母 或 数字 或 下划线 |
| \s | 任意的空白字符 |
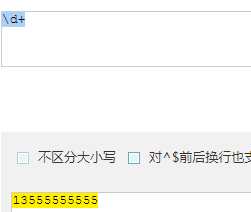
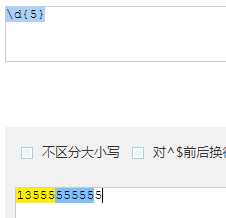
| \d | 数字 |
| \W | 非 字母 或 数字 或下划线 |
| \S | 非 空白字符 |
| \D | 非 数字 |
| \t | 制表符 |
| ^ | 字符串的开始 |
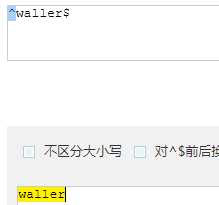
| $ | 字符串的结尾 |
| \b | 单词的结尾 |
| a|b | 字符 a 或 b |
| () | 匹配括号内的表达式,也表示一个组 |
| [...] | 匹配字符组中的字符 |
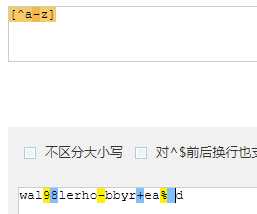
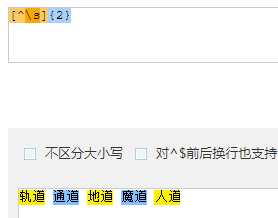
| [^...] | 匹配出了字符中的所有字符 |
| 量词 | 说明 |
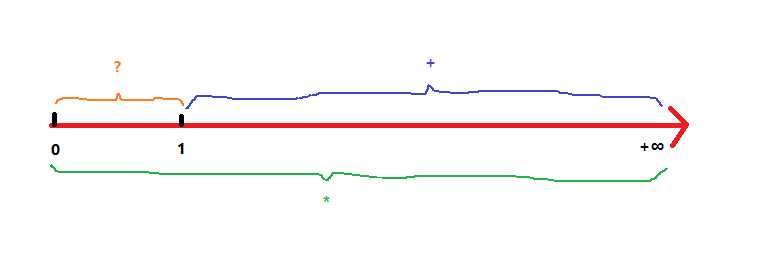
| * | 重复 零次 或 多次 |
| + | 重复 一次 或 多次 |
| ? | 重复 零次 或 一次 |
| {n} | 重复 n 次 |
| {n,} | 重复 n 次 或 多次 |
| {n,m} | 重复 n 到 m 次 |
在同一位置可能出现各种字符 组成了一个字符组,在正则表达式中用[ ]表示,一个字符组内每次只能匹配一个字符,[ ]内的字符是或的关系
ps: 字符组内范围必须从小到大必须按ASCII码表排序
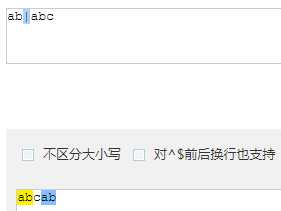
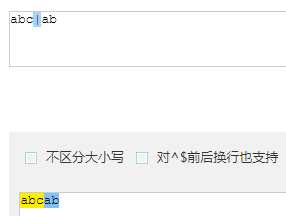
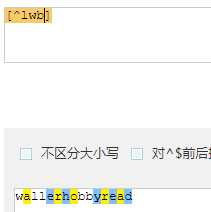
 匹配到 1 条结果
匹配到 1 条结果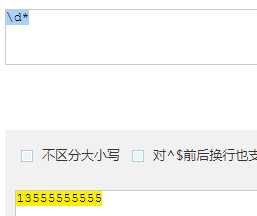 匹配到 2 条结果
匹配到 2 条结果
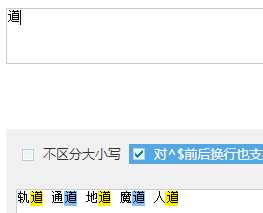
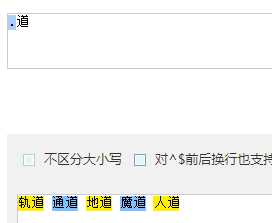
| 海. | 取 海和.组成的词 | 海燕海娇海东 | 匹配所有"海."的字符 |
| ^海. | 只取以 海和.为开头 | 海燕 | 只从开头匹配"海." |
| 海.$ | 只取以 海和.为结尾 | 海东 | 只匹配结尾的"海.$" |
| 正则 | 待匹配字符 | 匹配 结果 |
说明 |
| 李.? | 李杰和李莲英和李二棍子 |
李杰 |
?表示重复零次或一次,即只匹配"李"后面一个任意字符 |
| 李.* | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
*表示重复零次或多次,即匹配"李"后面0或多个任意字符 |
| 李.+ | 李杰和李莲英和李二棍子 | 李杰和李莲英和李二棍子 |
+表示重复一次或多次,即只匹配"李"后面1个或多个任意字符 |
| 李.{1,2} | 李杰和李莲英和李二棍子 |
李杰和 |
{1,2}匹配1到2次任意字符
|
原文:https://www.cnblogs.com/waller/p/11203007.html