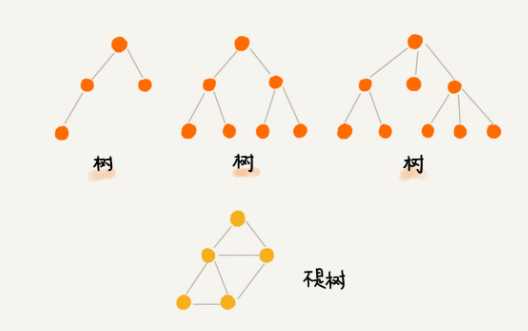
树是一种非线性表结构。直观看下树的结构
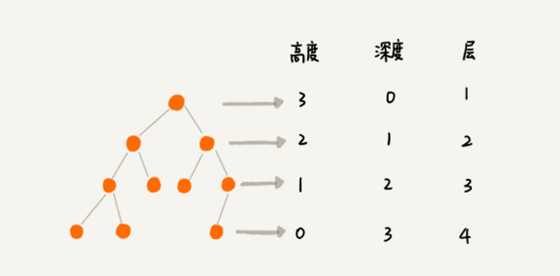
我们看下树的几个重要的概念:高度、深度、层,它们是这样定义的

树的结构多种多样,但我们最常用的还是二叉树。二叉树,顾名思义,就是每个节点最多有两个"叉",也就是两个子节点,分别是左子节点和右子节点。
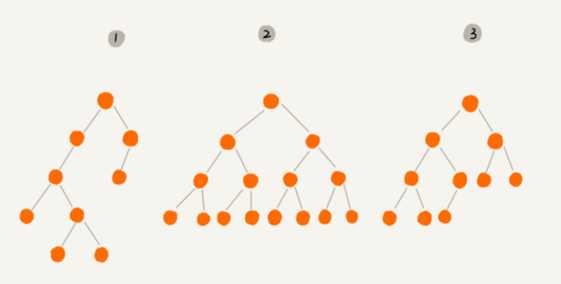
这个图里,有两个比较特殊的二叉树,分别是编号 2 和编号 3 。
编号2这种 叶子节点全都在最底层,除了叶子节点之外,每个节点都有左右两个子节点 的二叉树叫 满二叉树;
编号3这种 叶子节点都在最底下两层,最后一层的叶子节点都靠左排列,并且除了最后一层, 其它层的节点个数都要达到最大 的二叉树叫 完全二叉树;
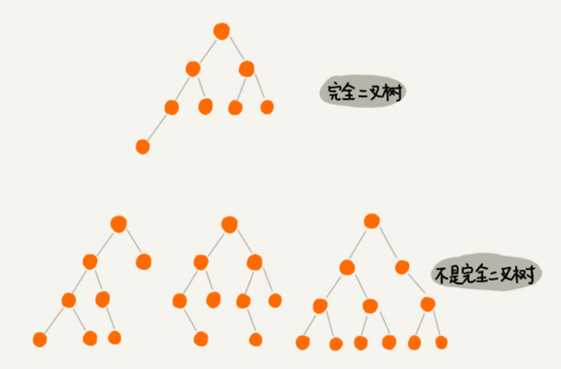
满二叉树很好理解,也很好识别,但完全二叉树就不容易分清了,如下
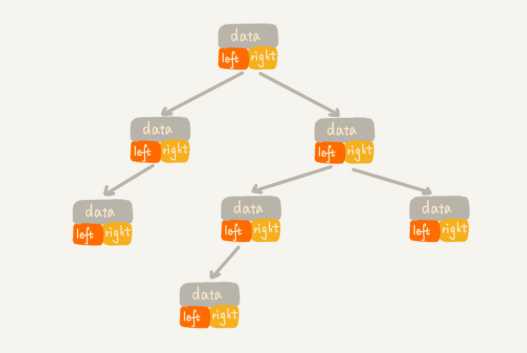
二叉树有两种存储方法:基于指针或引用的二叉链式存储法,基于数组的顺序存储法
链式存储法:每个节点都有三个字段,数据和指向左右子节点的指针,只要拎住根节点,就可以通过左右子节点的指针,把整棵树都串起来。这种存储方式比较常用,大部分二叉树
代码都是通过这种结构来实现的
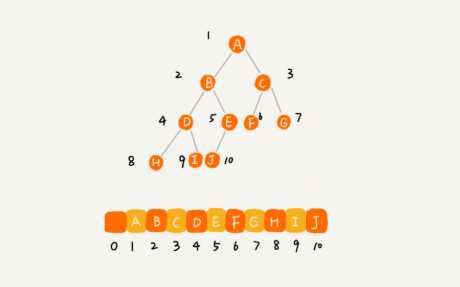
顺序存储法:我们把根节点存储在下标 i=1 的位置,其左子节点存储在 2*i 的位置,其右子节点存储在 2*i+1 的位置,依此类推。通过这种方式,只要知道了根节点存储的位置(一般情况下,为了方便计算子节点,根节点会存储在下标为 1 的位置),就可以通过下标计算,把整棵树都串起来。
完全二叉树使用基于数组的顺序存储法仅会浪费一个下标为 0 的存储位置,但非完全二叉树使用基于数组的顺序存储法就会浪费比较多的数组存储空间。
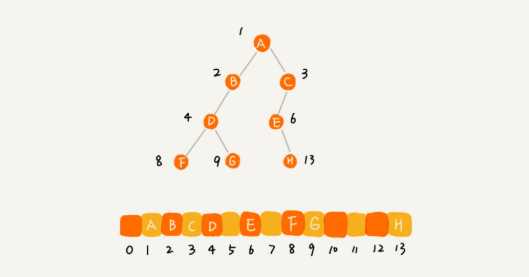
所以,完全二叉树用数组存储是最节省内存的一种方式,因为数组的存储方式并不需要像链式存储法那样,要存储额外的左右子节点的指针。这也就是完全二叉树会单独拎出来的原因,也是完全二叉树要求最后一层的子节点都靠左的原因
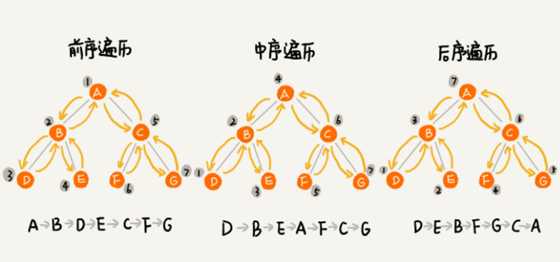
二叉树经典的遍历方法有三种:前序遍历、中序遍历、后续遍历。其中,前、中、后序,表示的是节点和它的左右子树节点遍历打印的先后顺序
前序遍历:对于数中的任意节点来说,先打印这个节点,然后再打印它的左子树,最后打印它的右子树
中序遍历:对于数中的任意节点来说,先打印它的左子树,然后再打印这个节点,最后打印它的右子树
后序遍历:对于数中的任意节点来说,先打印它的左子树,然后再打印它的右子树,最后打印这个节点
原文:https://www.cnblogs.com/jiangwangxiang/p/11073094.html