聚类也成为集群分析,是把相似的对象通过静态分类的方式分成不同组或更多的子集,属于非监督学习。
与分类问题不同的是,聚类问题的数据事先是没有标签的。
数据点之间的距离度量:
经典算法:K-means等
应用:
层次型聚类:
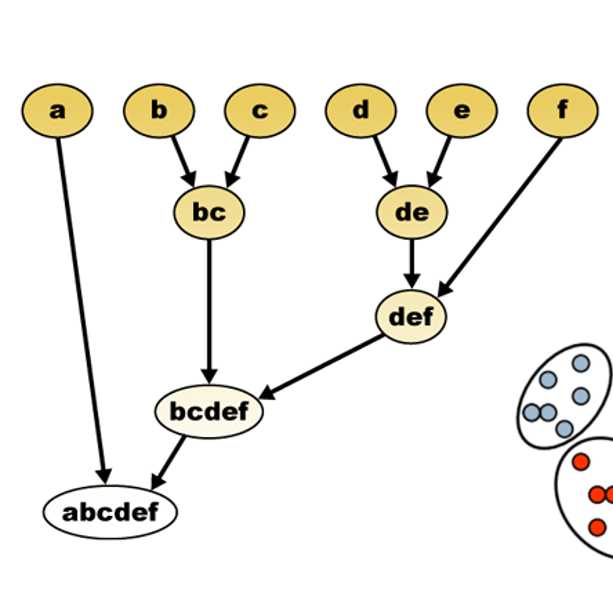
在不同层面,grouping结果不同。
emmmmmmmm,数据挖掘有个广为人知的但是不知真伪的例子:啤酒与尿布。讲的是沃尔玛经过对顾客的购买行为数据进行分析后,得出男人在买尿布的时候一般会买一些啤酒。这其实就是一关联规则的体现。
下面再举个栗子:

通过对购买行为的分析,我们得到了买牛奶和面包时,一般会买黄油的结论。
回归接触比较多,这里就不展开bb了,注意回归也不能要求overfitting。
此外还有数据可视化,数据预处理等一些方面,数据预处理是数据挖掘中最麻烦,最耗时的一步,而可视化可用的工具(软件)有很多,数据的可视化可以帮助我们合理地选择算法,提高效率。
原文:https://www.cnblogs.com/jameschou/p/11013525.html