1.用自己的话阐明Hadoop平台上HDFS和MapReduce的功能、工作原理和工作过程。
2.HDFS上运行MapReduce
1)准备文本文件,放在本地/home/hadoop/wc
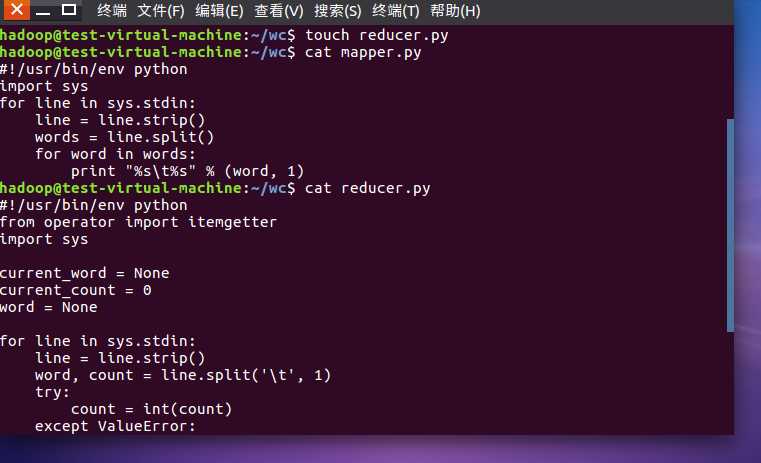
2)编写map函数和reduce函数,在本地运行测试通过
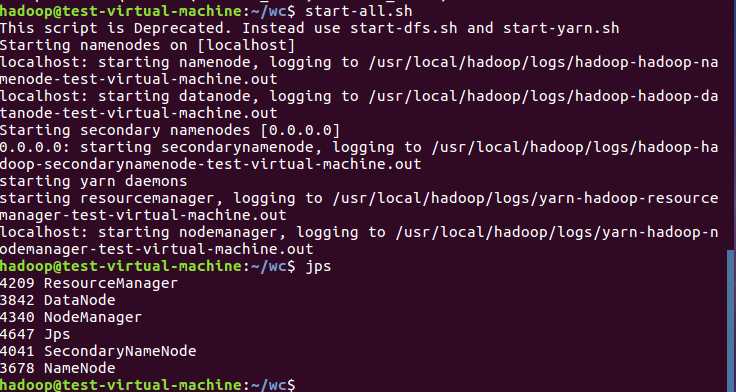
3)启动Hadoop:HDFS, JobTracker, TaskTracker
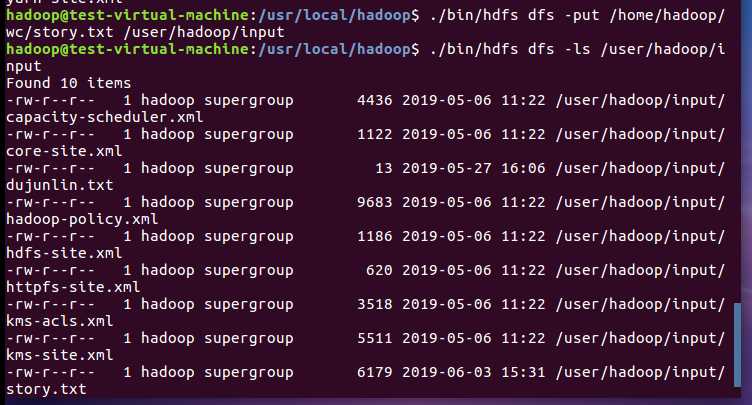
4)把文本文件上传到hdfs文件系统上 user/hadoop/input
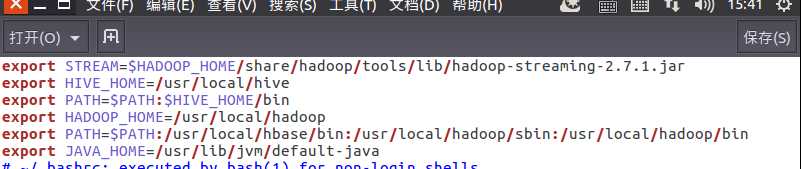
5)streaming的jar文件的路径写入环境变量,让环境变量生效

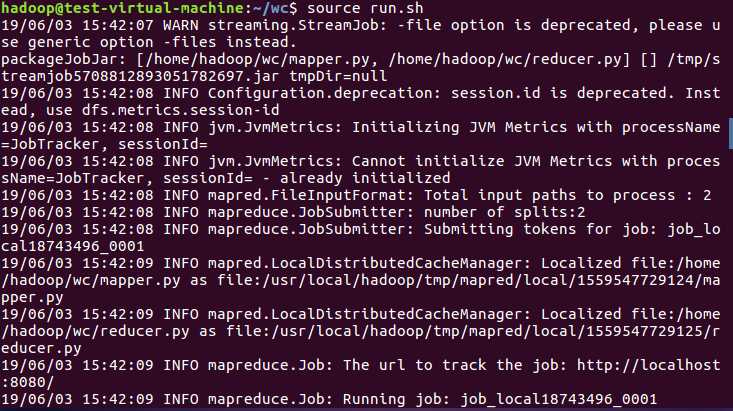
6)建立一个shell脚本文件:streaming接口运行的脚本,名称为run.sh


7)source run.sh来执行mapreduce
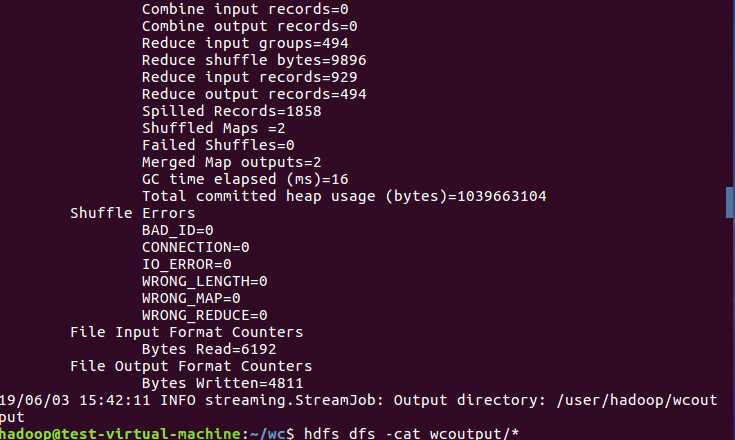
8)查看运行结果
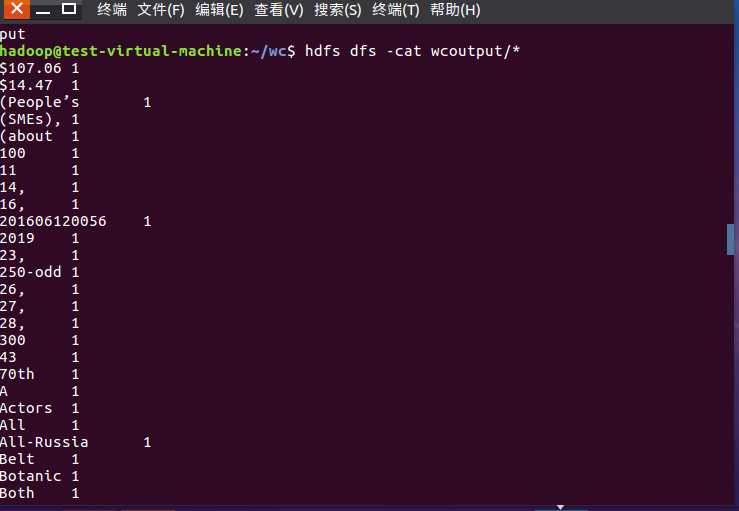
原文:https://www.cnblogs.com/dujunlin/p/10967806.html