序言
本届百公里徒步本来是定在4月20、21两天举行的,后遇天气原因就往后推延了,也正因此原因,在20日有其他事情本来不能参加本届活动的情况下又有幸参加了。
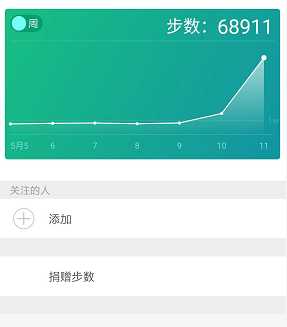
这是我第一次参加磨房百公里活动,在活动前,没有这么远距离的徒步经历,不清楚自己能走多远,和同伴分析了路线,结合自己平日的步行速度,定了在东部华侨城下撤的目标,大概50KM,下午5、6点左右就能到达,如此,下撤后也方便各自回去。
当天活动,太阳很大,天气很热,从梧桐山到二签小三洲这段又有很多上坡,记得有一个长坡,休息了两次才爬上去,走得还是比较辛苦的。最后在下午6点半左右到达了云海谷体育公园下撤点。

正文
周五(2019年5月24日)晚八点,磨房深圳百公里公众号推来消息:官方相册已上线。心里美滋滋的(PS:这下可看到我帅气身影了,哈哈^_^),下班回来立马进入公众号开始[寻图之旅],进入后提示可以上传本人靓照进行AI人脸识别匹配(哇,这么贴心,高科技都用上了)。于是乎,按着指引进行了一番操作......

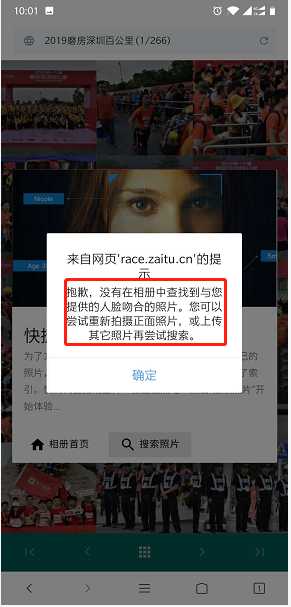
没有?还是没有匹配到?不会这么不着摄影师待见吧~
那我还怎么发朋友圈呀?[**一脸快哭的表情]
想办法......
难道要这么一页页一张张翻下去看吗?[奔溃~]

266页,6K+张照片,得要找到什么时候呀?
然而,有办法吗?有办法吗?
悲催的我就这样很无助的一页一页像鉴黄师认真负责的鉴定没一张照片,看不清的还要点进去看大图......
【现在是晚上11:30,小度提醒您,该睡觉了】
看了下进度,才五十多页,啥感觉不想提了(鉴黄师:看到身体就想吐),洗洗睡吧~
次日,又是大好天气,去超市里采购了排骨、鲤鱼等菜食回来给周末的自己来顿美食。美滋滋的享用完午餐后,看档综艺节目《向往的生活》休闲一下。
看着这休闲自在的田园生活,又勾起了我对美照注意力:要不把全部图片下载到本地看吧,直接大图,应该会更快。
说干就干,然后用Python写了一段简单的脚本把官方提供的所有照片都下载到本地了:

看了两集《向往的生活》,图片也全部下载完成了,一眼可以瞄12张大图,确实比之前方便多了。当然后,下载到本地后还得靠肉眼搜索~
结果
真没有,是真的连个背影都没有[抓狂]??
摄影师呀,你咋地了......
以下附本次爬取照片源码:
import requests from requests.exceptions import ReadTimeout,HTTPError,RequestException import re from bs4 import BeautifulSoup import os import urllib.request import urllib.parse import string import time #爬取图片URL信息数据 def CrawImgInfo(req_url): resultdata=[] headers={"content-type":"text/html; charset=utf-8"} try: res=requests.get(req_url,headers=headers) if res.status_code==200: html=BeautifulSoup(res.text,"html.parser") #选取所有照片HTML imgItems=html.select(".mdui-container-fluid div.mdui-row-gapless div.mdui-col-xs-4") for item in imgItems: #获取大图信息页面URL imginfo_url=item.select("a")[0].attrs["href"] resultdata.append(imginfo_url) else: print("fail") except ReadTimeout: print("timeout") except HTTPError: print("HttpError") except RequestException: print("httpError") return resultdata #获取图片的URL def CrawImgUrl(req_url): imgurl="" headers={"content-type":"text/html; charset=utf-8"} try: res=requests.get(req_url,headers=headers) if res.status_code==200: html=BeautifulSoup(res.text,"html.parser") #获取大图的URL imgurl=html.select(".mdui-container-fluid div.mdui-row-gapless a")[0].attrs["href"] else: print("fail") except ReadTimeout: print("timeout") except HTTPError: print("HttpError") except RequestException: print("httpError") return imgurl #写入数据,保存到本地 def SaveImg(filepath,imgurl): #URL含中文,需要编码 imgurl_encode=urllib.parse.quote(imgurl,safe=string.printable) try: resp=urllib.request.urlopen(imgurl_encode) imgname=imgurl.split("/")[-1] if resp.code==200: img=resp.read() imgfilename=filepath+imgname with open(imgfilename,"wb") as f: f.write(img) except urllib.error.HTTPError as e: print("The server conldn\‘t fulfill the request.") except urllib.error.URLError as e: print(‘We failed to reach a server.‘) def GetData(): rootUrl="网站地址" pageUrl="翻页地址" #实际总页数加1 pageCount=267 savePath="本地存储地址" imgCount=0 for pageIndex in range(1,pageCount): req_url=pageUrl+str(pageIndex) curpage_imginfos=CrawImgInfo(req_url) if len(curpage_imginfos)>0: for item in curpage_imginfos: imgUrl=CrawImgUrl(rootUrl+item) if len(imgUrl)>0: SaveImg(savePath,imgUrl) imgCount=imgCount+1 print("图片:%s 下载完成!(下载总数:%s|%s/%s)" %(imgUrl,imgCount,pageIndex,pageCount-1)) #暂停指定秒数,对服务器要温柔一些 time.sleep(1) if __name__ == ‘__main__‘: GetData()
原文:https://www.cnblogs.com/martinfeng/p/10925698.html