数组(Array)是一种线性表数据结构。它用一组连续的内存空间,来存储一组具有相同类型的数据。
我们拿一个长度为10的int类型的数组 int[]a=new int[10] 来举例。
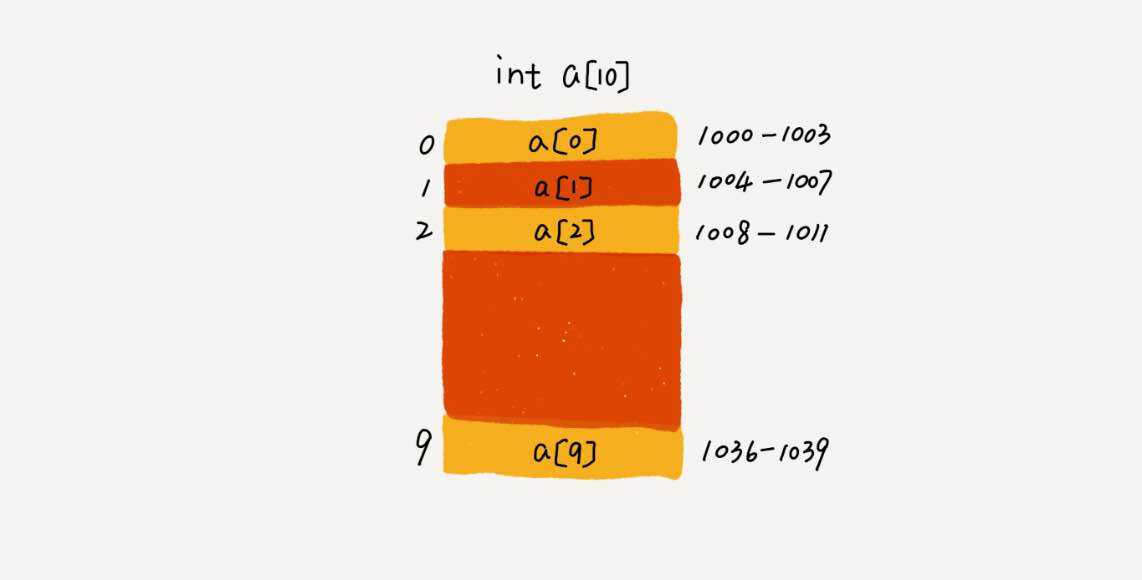
在我画的这个图中,计算机给数组a[10],分配了一块连续内存空间1000~1039,其中内存块的首地址为base_address = 1000
计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
ss = base_address + i * data_type_size
其中data_type_size表示数组中每个元素的大小。(int类型的大小为4个字节)
跟插入数据类似,如果我们要删除第k个位置的数据,为了内存的连续性,也需要搬移数据,不然中间就会出现空洞,内存就不连续了。
实际上,在某些特殊场景下,我们并不一定非得追求数组中数据的连续性。如果我们将多次删除操作集中在一起执行,删除的效率是不是会提高很多。
例如,数组a[10]中存储了8个元素:a,b,c,d,e,f,g,h。现在,我们要依次删除a,b,c三个元素。为了避免d,e,f,g,h这几个数据会被搬移3次,我们可以先记录下已经删除的数据。每次的删除操作并不是真正搬移数据,只是记录数据已经被删除了。当数组没有更多的空间存储数据时,这样就大大减少了删除操作导致的数据搬移。
如果你了解JVM,你会发现,这不就是JVM标记清除垃圾回收算法的核心思想吗?没错,数据结构和算法的魅力就在于此,很多时候我们并不是要去死记硬背某个数据结构或者算法,而是要学习他背后的思想和处理技巧,这些东西才是最有价值的。
首先分析一下这段C语言代码的运行结果:
int main(int argc, char* argv[]){ int i = 0; int arr[3] = {0}; for(; i<=3; i++){ arr[i] = 0; printf("hello world\n"); } return 0; }
你发现问题了吗?这段代码的运行结果并非打印三行“hello world”,而是会无限打印“hello world”。
因为,数组大小为3,a[0],a[1],a[2],而我们的代码因为书写错误,导致for循环的结束条件错写为了i<=3而非i<3,所以当i=3时,数组a[3]访问越界。
我们知道,在C语言中,只要不是访问受限的内存,所有的内存都是可以自由访问的。根据我们前面讲的数组寻址公式,a[3]也会被定位到某块不属于数组的内存地址上,而这个地址正好是存储变量i的内存地址,那么a[3]=0就相当于i=0,所以就会导致代码无限循环。
数组越界在C语言中是一种未决行为,并没有规定数组访问越界时编译器应该如何处理。因为,访问数组的本质就是访问一段连续内存,只要数组通过偏移量计算得到的内存地址可用,那么程序就可能不会报任何错误。
这种情况下,一般都会出现莫名其妙的逻辑错误,就像我们刚刚举的例子,debug的难度非常大。而且,很多计算机病毒也正是利用了代码中的数组越界可以访问非法地址的漏洞,来攻击系统,所以写代码的时候一定要警惕数组越界。
对于业务开发,直接使用容器就足够了,省时省力。毕竟损耗一丢丢性能,完全不会影响到系统整体的性能。但如果你是做一些非常底层的开发,比如开发网络框架,性能的优化需要做到极致,这个时候数组就会优于容器,成为首选。
原文:https://www.cnblogs.com/mylearning-log/p/10913489.html