dataset
outline
opportunities and challenges
temporal structure: 需要对动作进行分解:decomposition
常用的 Deep networks
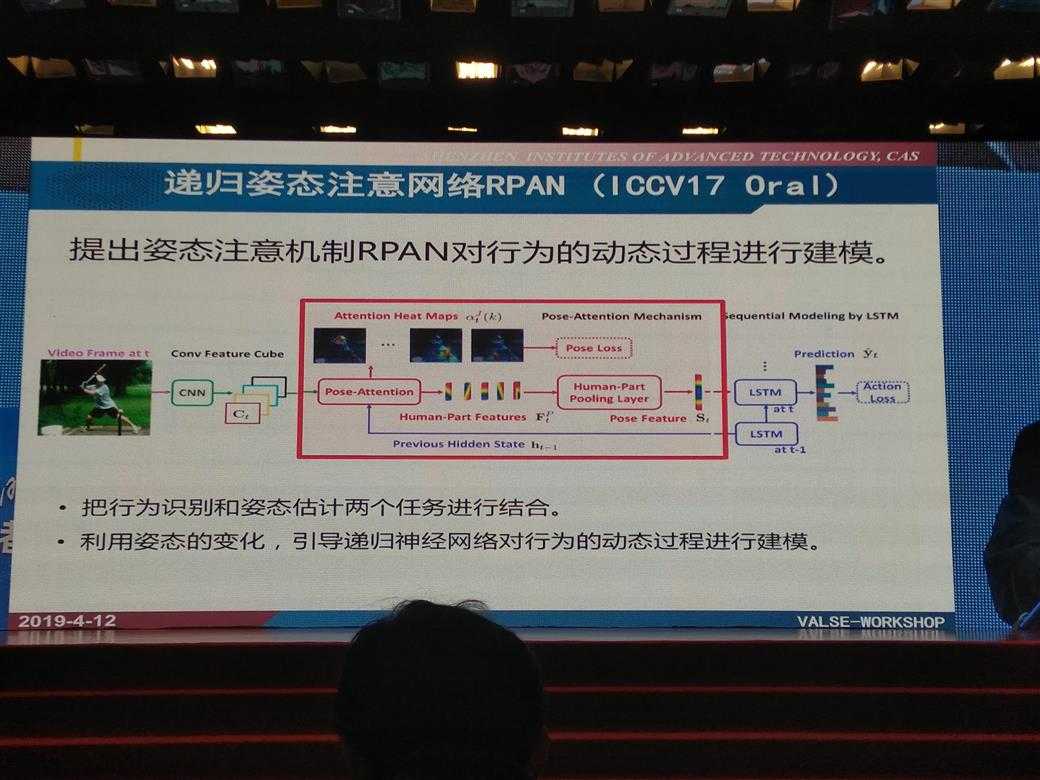
liming wang 自己的3篇工作
之前看到一些很好的zhihu link: 动作识别-1, 动作识别-2, 时序行为检测-1, 时序行为检测-2, 时序行为检测-3, 时序行为检测-4,
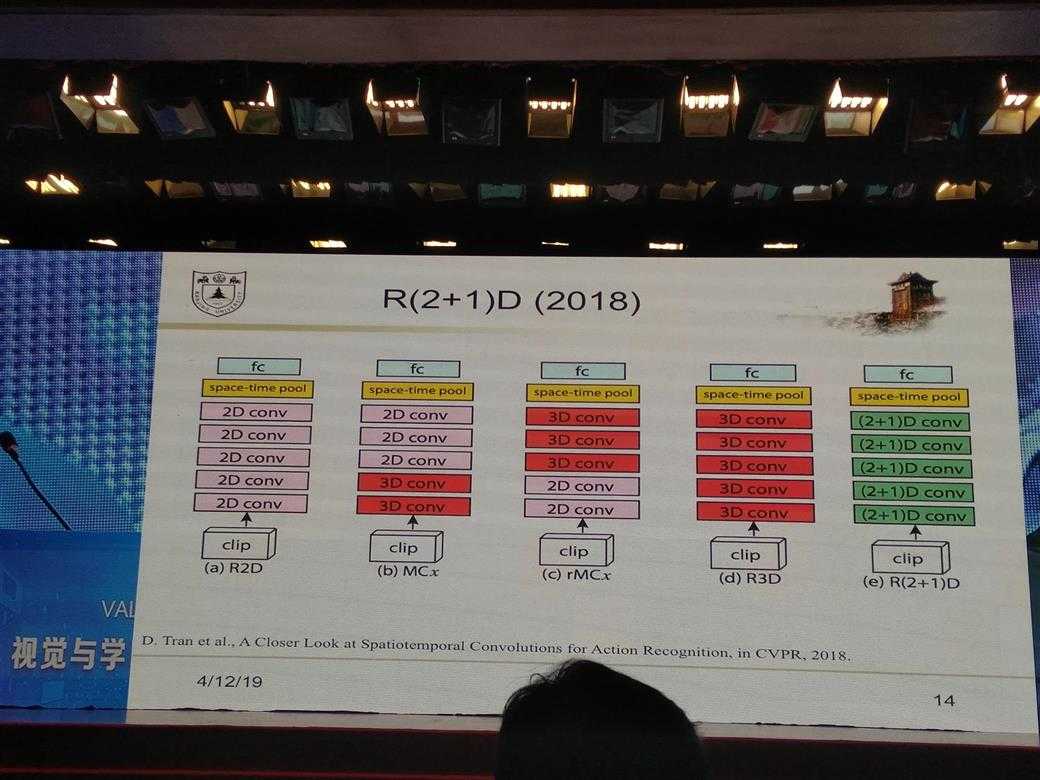
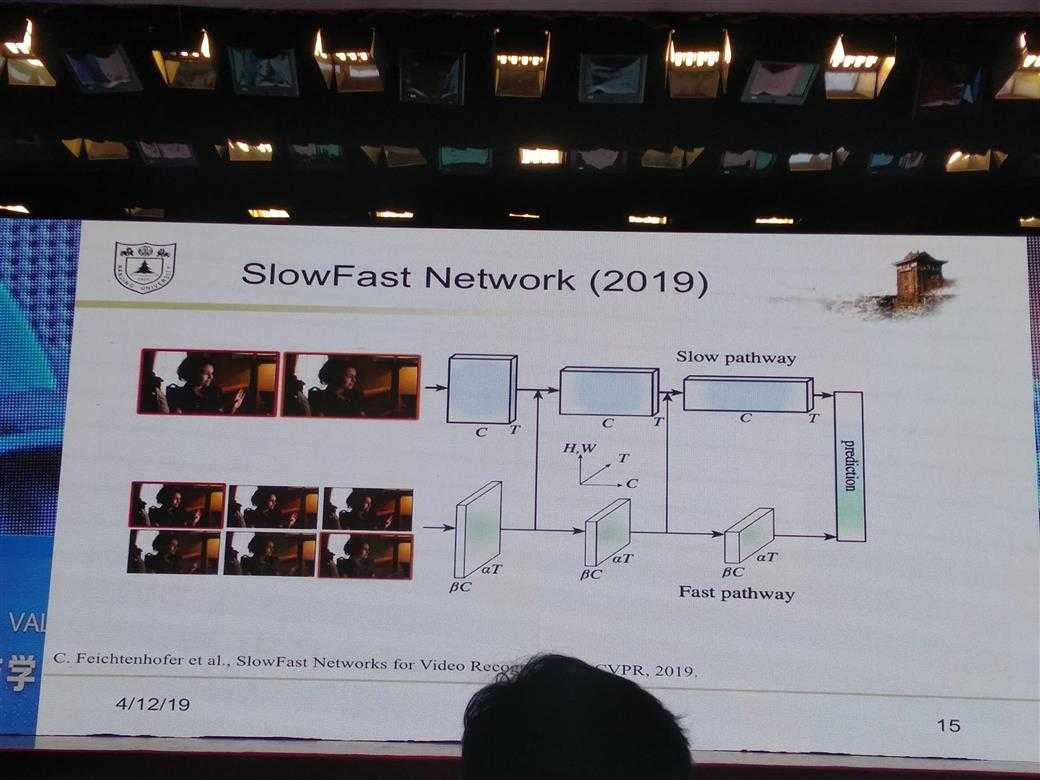
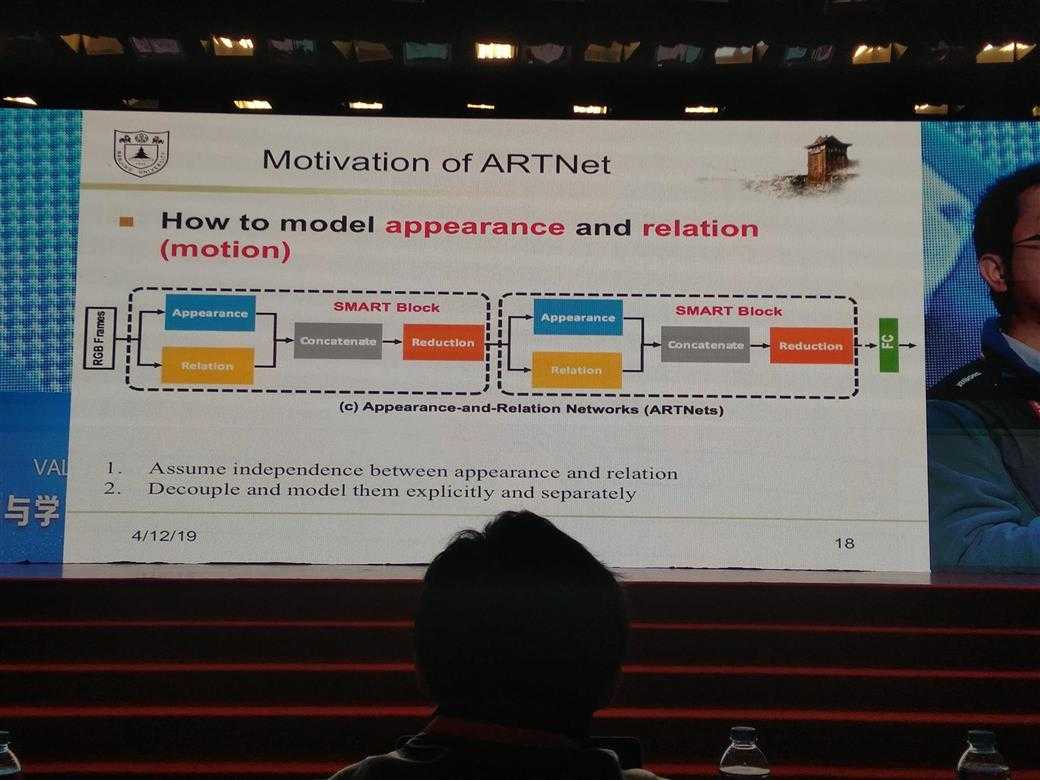
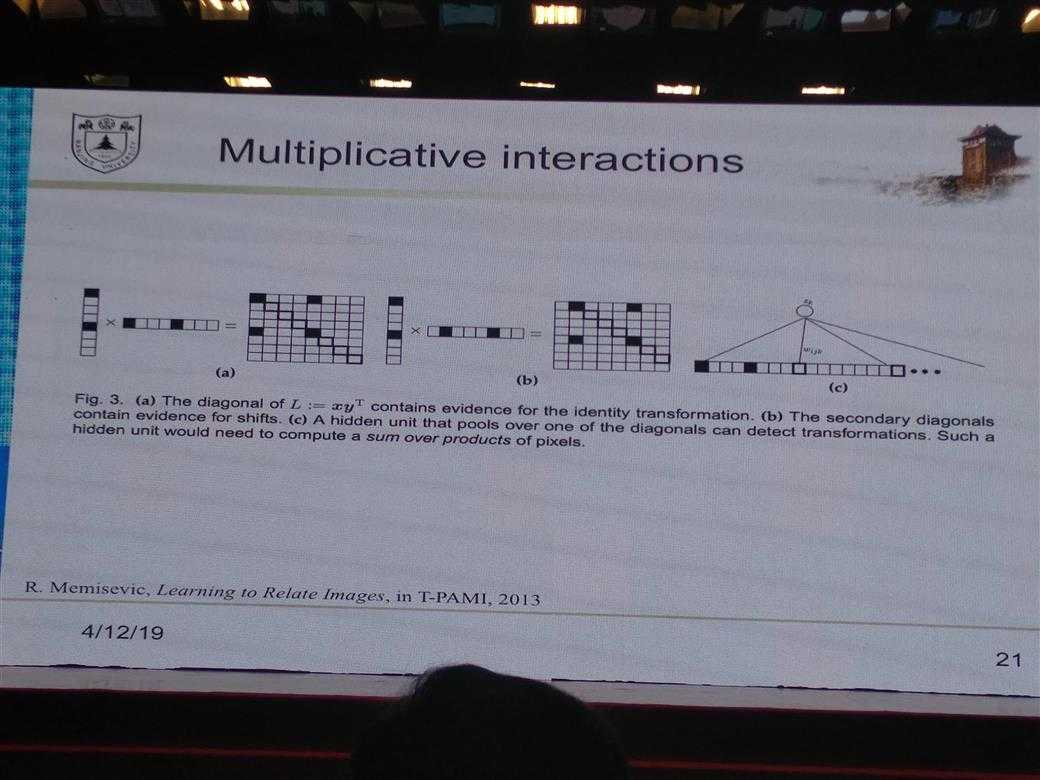
所有的PPT图片






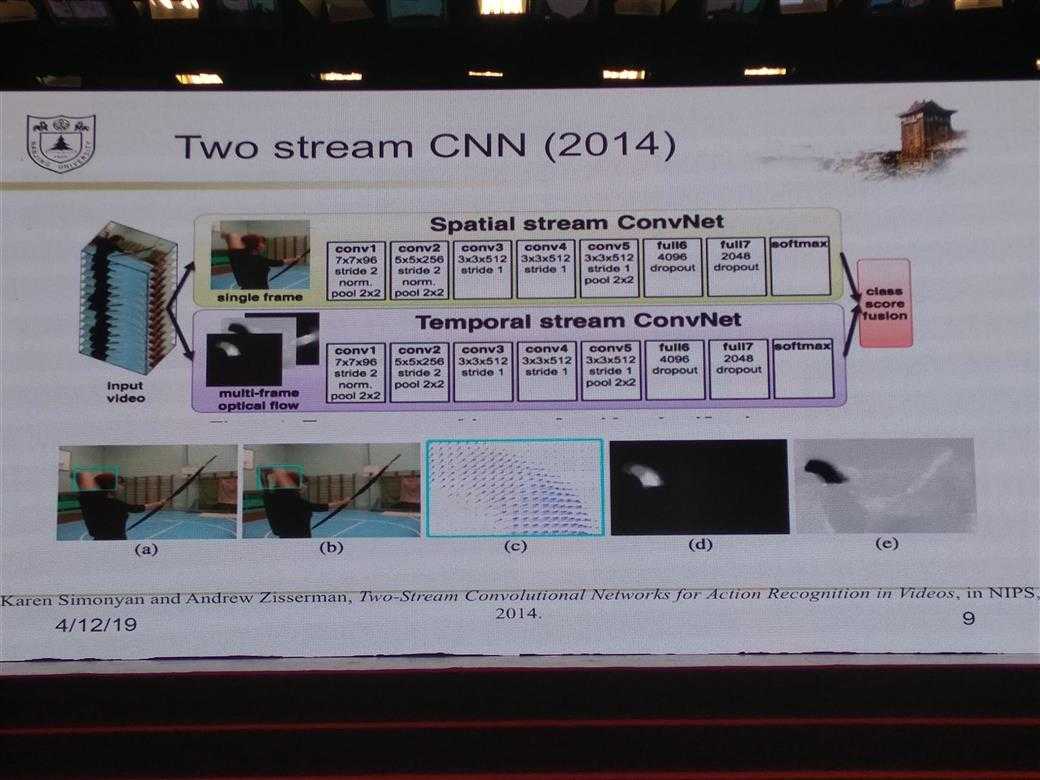
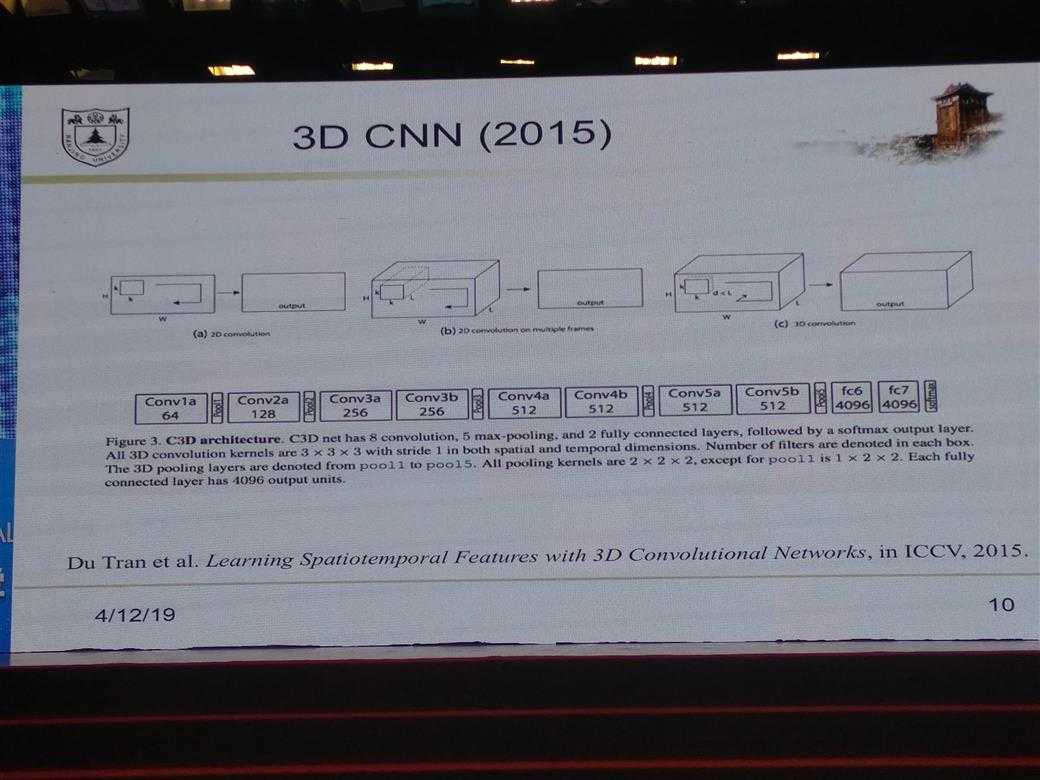
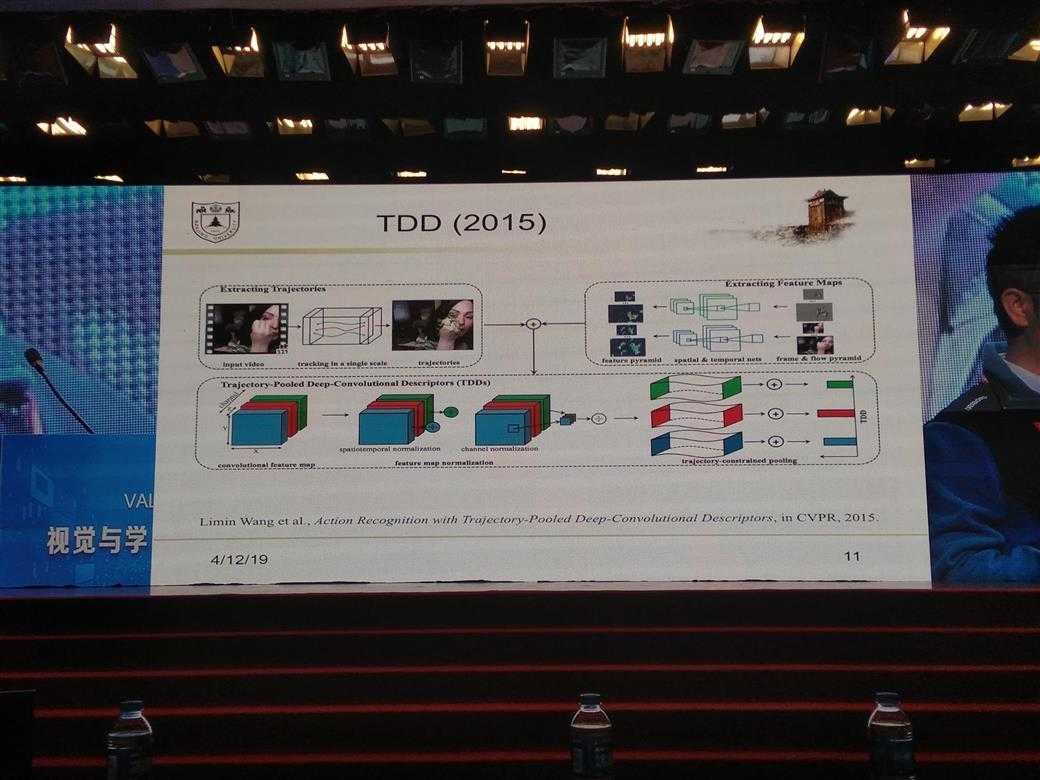

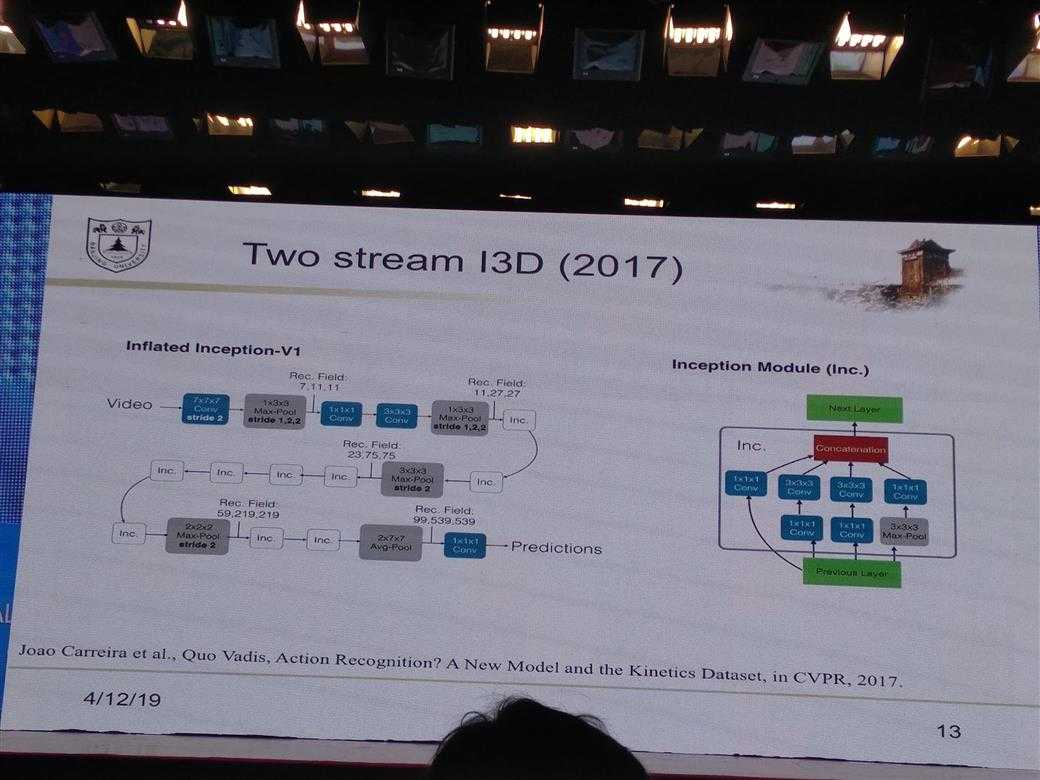



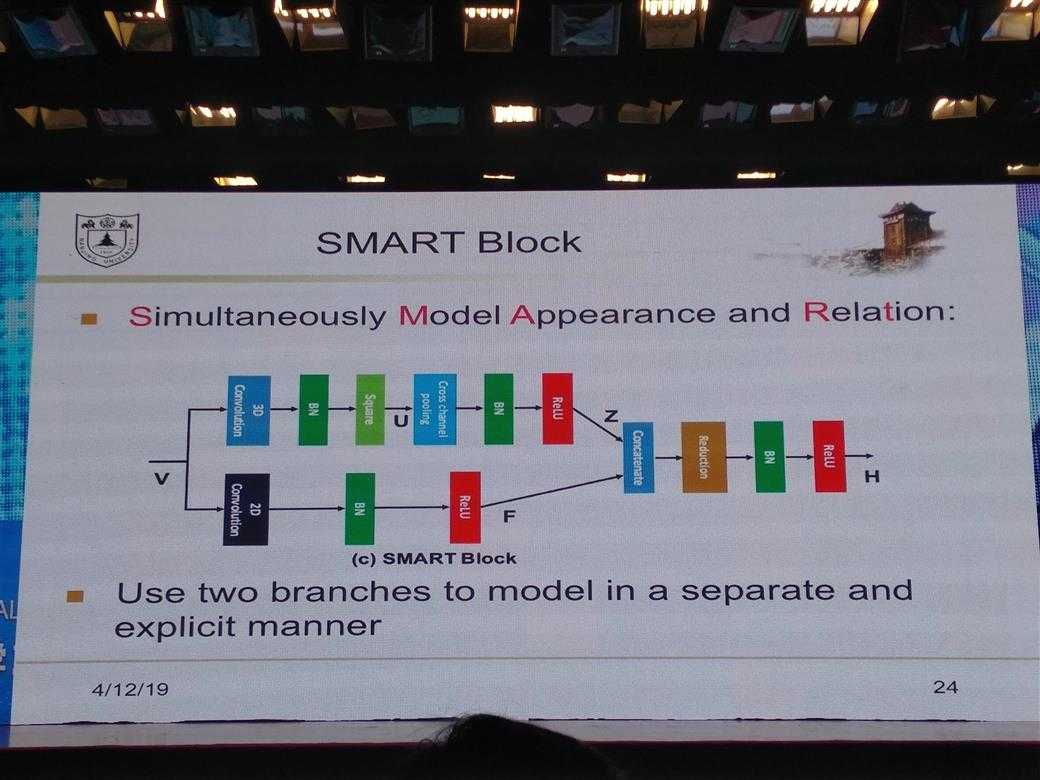


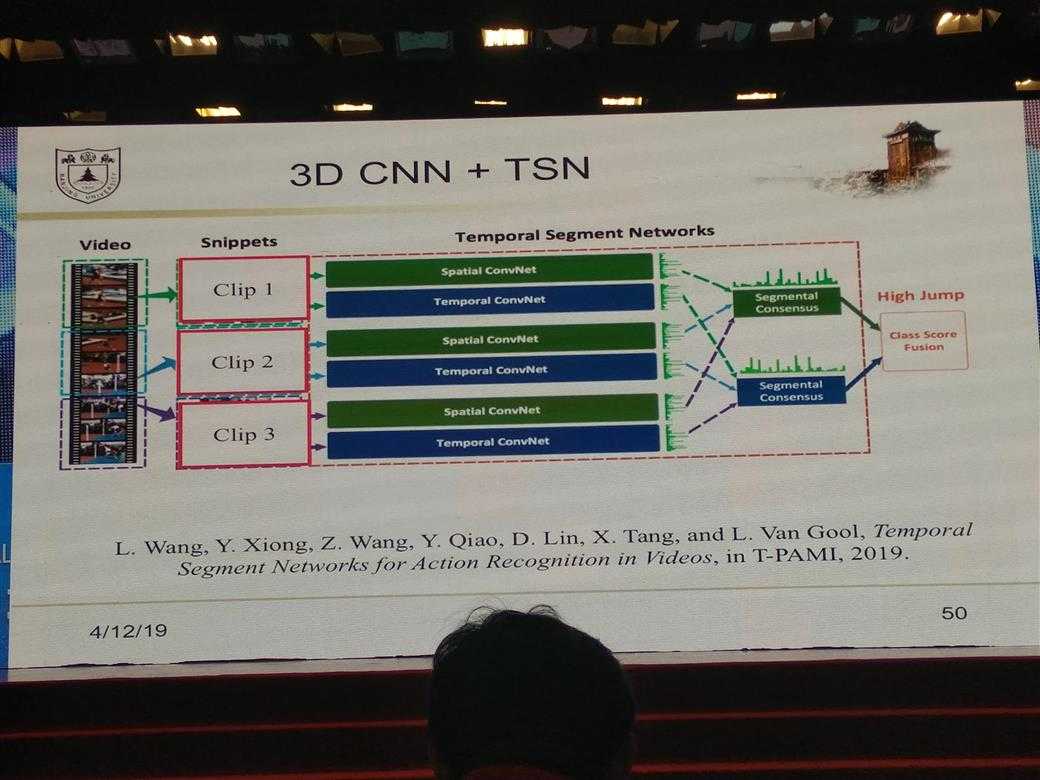
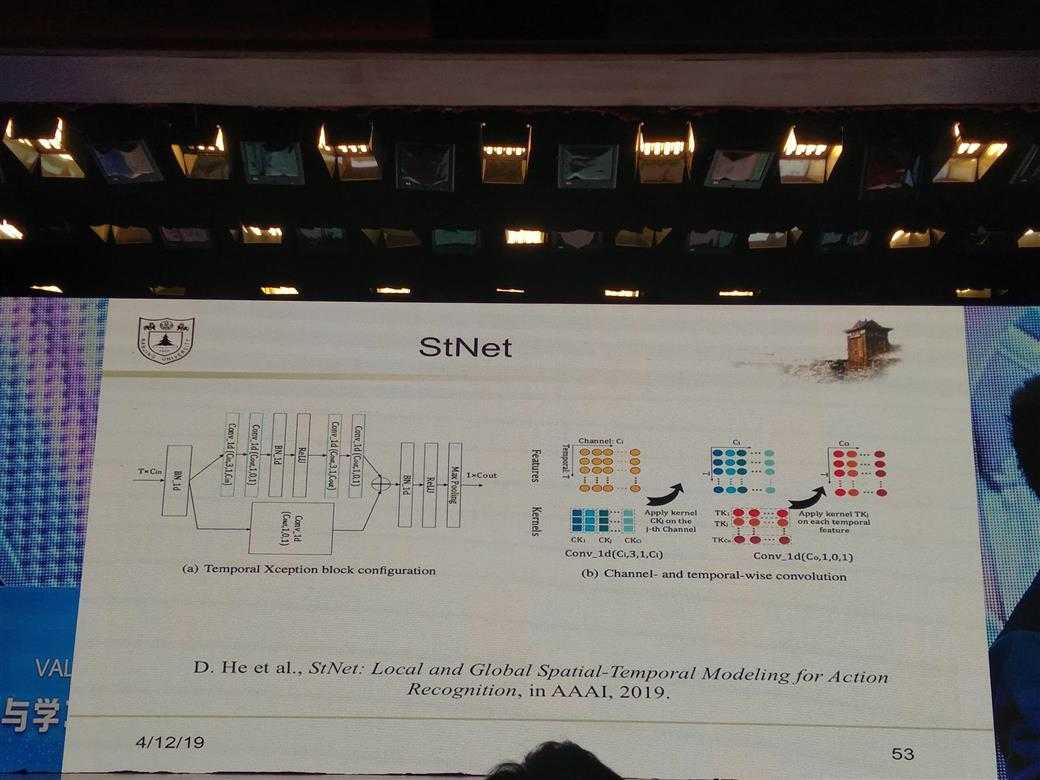

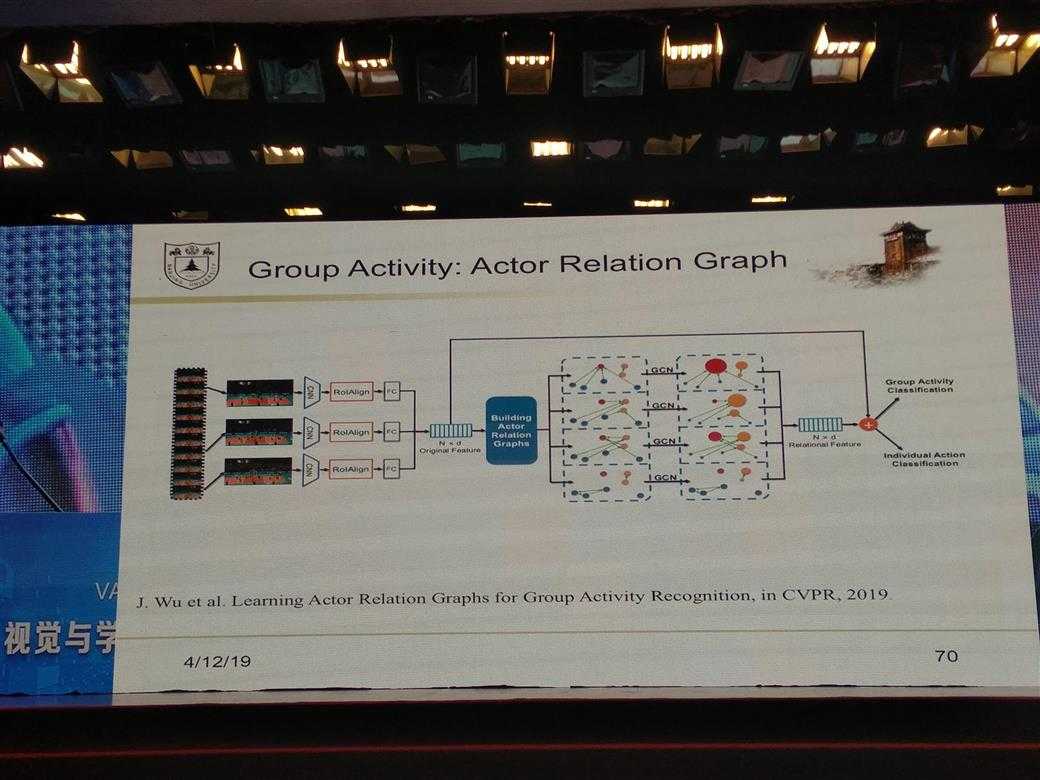

DL的一些经验性Trick介绍

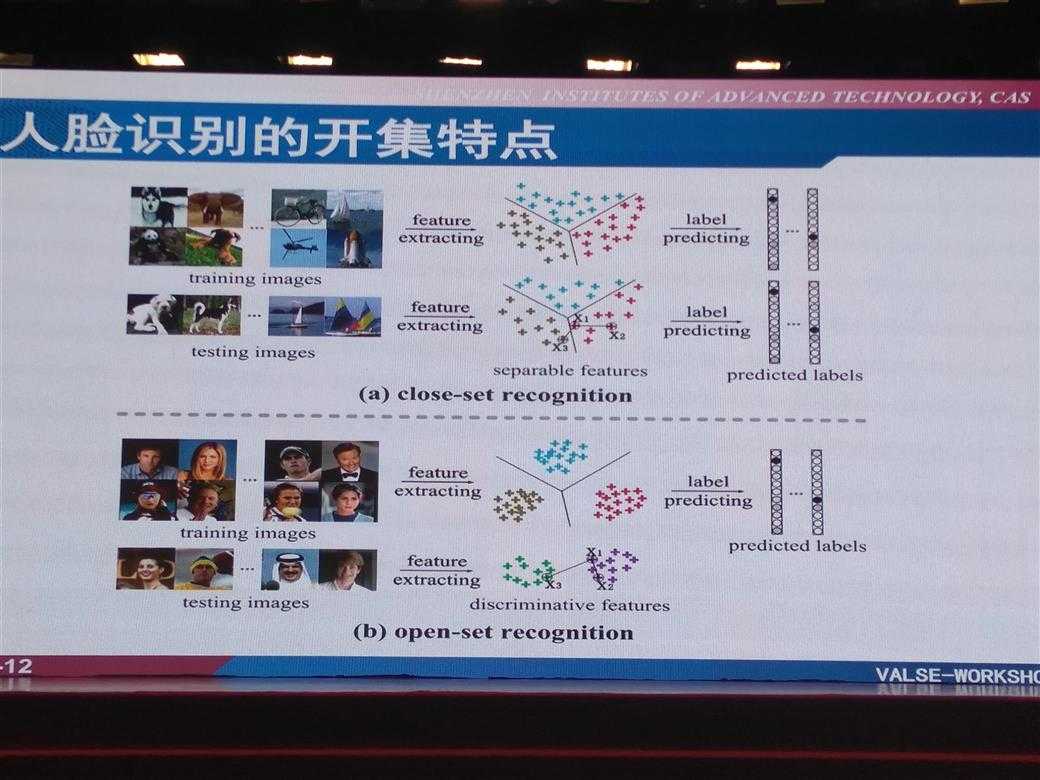
人脸识别的开集特点 (Open-set 和 novelty detection有点类似,参考TODO)
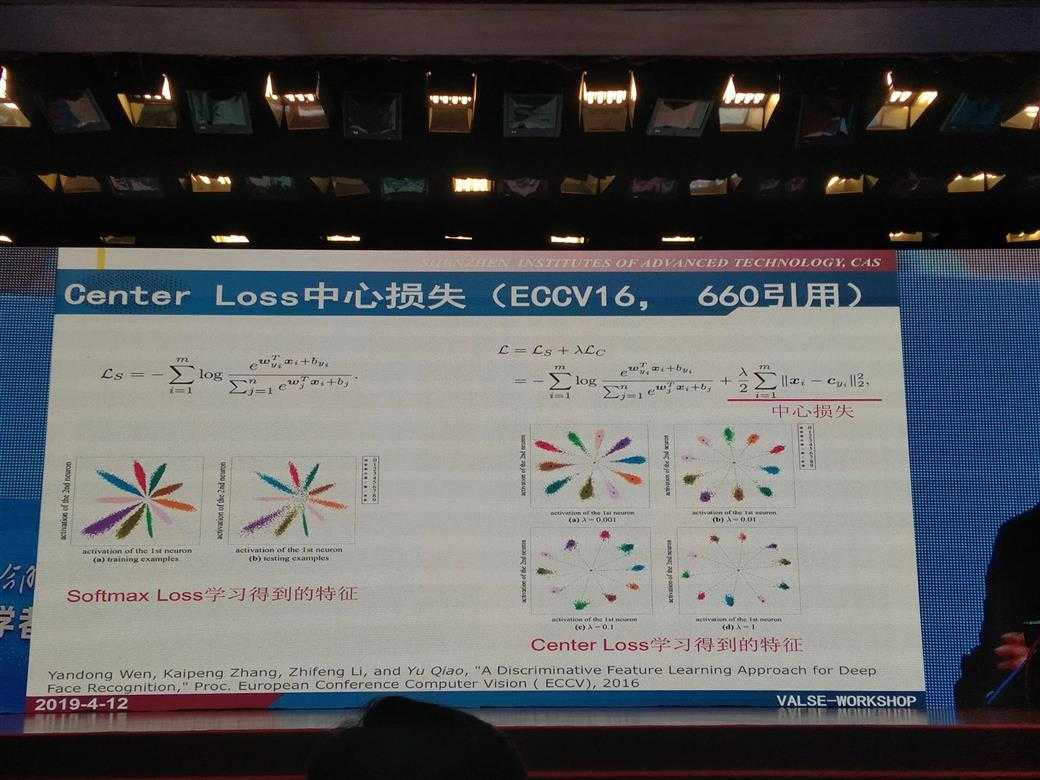
Center Loss (ECCV2016)
center loss意思即为:为每一个类别提供一个类别中心,最小化min-batch中每个样本与对应类别中心的距离,这样就可以达到缩小类内距离的目的。
center loss的原理主要是在softmax loss的基础上,通过对训练集的每个类别在特征空间分别维护一个类中心,在训练过程,增加样本经过网络映射后在特征空间与类中心的距离约束,从而兼顾了类内聚合与类间分离。
Center Loss的改进 (IJCV2019): 用投影方向代替类中心
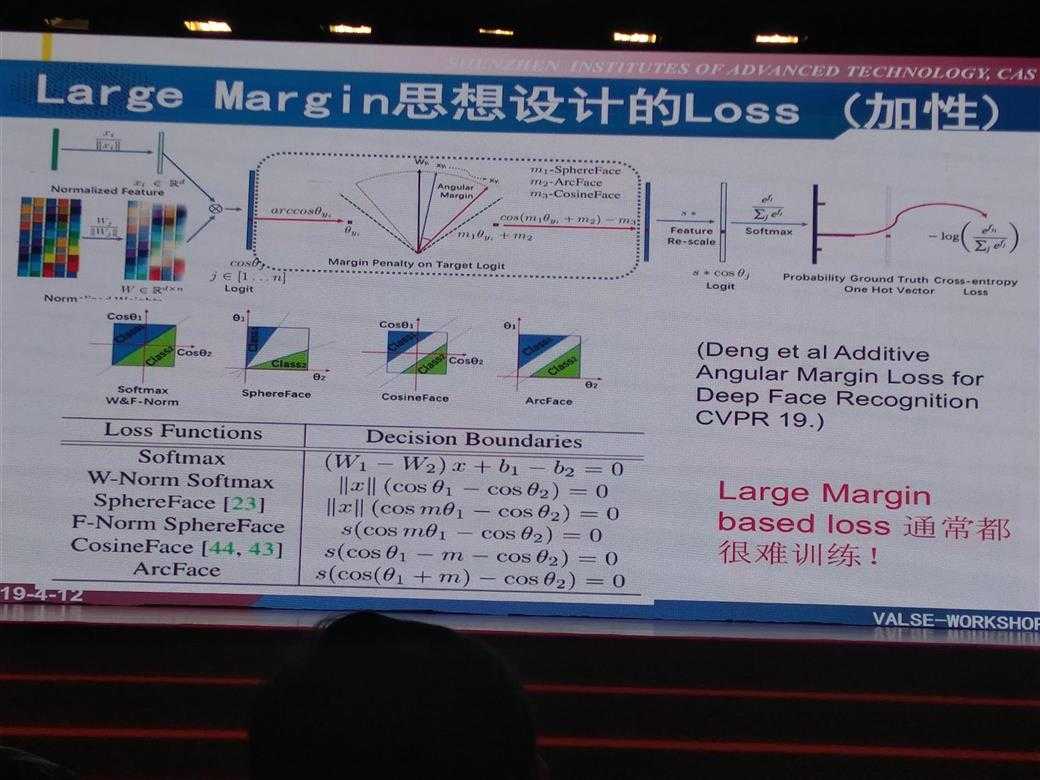
Large Margin思想设计的Loss:
Range Loss :有效应对类间样本数不均衡造成的长尾问题
video action recognition
一篇文章
一些图





applicaltion
Tasks of Emotions in videos
Challenges
Knowledge Transfer
Emotion-oriented summarization
Face emotion
一些图:



outline
introduction
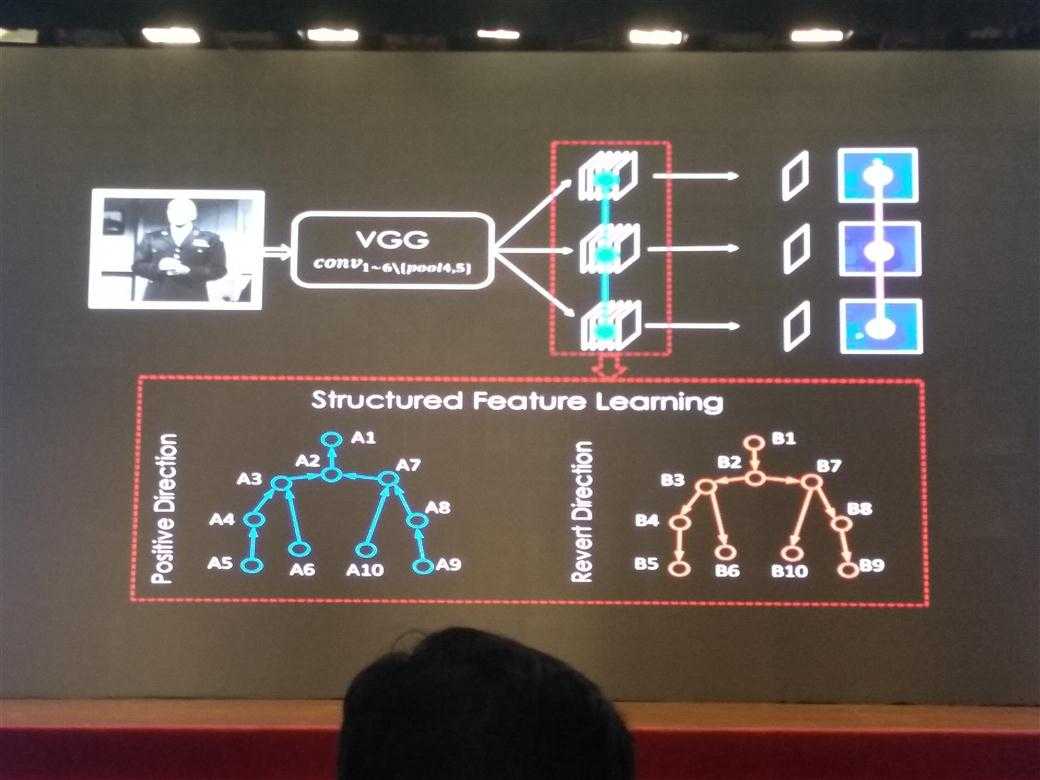
structured feature learning
back-bone model design
conclusion
一些图










原文:https://www.cnblogs.com/LS1314/p/10885080.html