scrapy 没有界面,需要命令行来操作。
非常简单,总共也就十四五个命令,分为全局命令和项目命令。
在哪都能用
常用命令
scrapy startproject name 创建项目/工程
scrapy genspider taobao taobao.com 创建爬虫
不太常用
查看爬虫配置/参数 scrapy settings --get DOWNLOAD_DELAY 下载延迟 scrapy settings --get BOT_NAME 爬虫名字 启动爬虫 scrapy runspider scrapy_cn.py 执行爬虫脚本 scrapy crawl spider [这个也是启动爬虫,是项目命令,需要创建工程] 下载源码 # 看看有没有异步之类的 scrapy fetch https://hao.360.com/?llqxqd scrapy fetch https://hao.360.com/?llqxqd >E:/3.html 下载并保存源码(WINDOWS) scrapy view https://hao.360.com/?llqxqd 下载并直接用浏览器打开 shell 工具 scrapy shell https://hao.360.com/?llqxqd 版本查看 scrapy version
在项目目录才能用
scrapy crawl spider 启动爬虫(需要进入app目录)
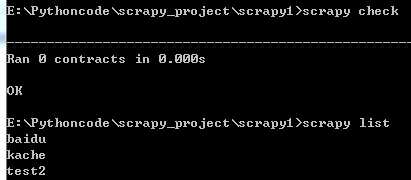
scrapy check 检测爬虫
scrapy list 显示有多少爬虫(以name为准)
为了增强scrapy的灵活性,在命令行中可以设置参数,这使得构建好的爬虫能够执行不同的任务。
实例代码
def start_requests(self):
url = ‘http://lab.scrapyd.cn/‘
tag = getattr(self, ‘tag‘, None) # 获取tag值,也就是爬取时传过来的参数
if tag is not None: # 判断是否存在tag,若存在,重新构造url
url = url + ‘tag/‘ + tag # 构造url若tag=爱情,url= "http://lab.scrapyd.cn/tag/爱情"
yield scrapy.Request(url, self.parse)
命令行参数设置
scrapy crawl argsSpider -a tag=爱情
原文:https://www.cnblogs.com/yanshw/p/10851220.html