1、资源优化理解:
不同设备,io不同。每种设备都有两个指标:延时(响应时间):表示硬件的突发处理能力;带宽(吞吐量):代表硬件持续处理能力。
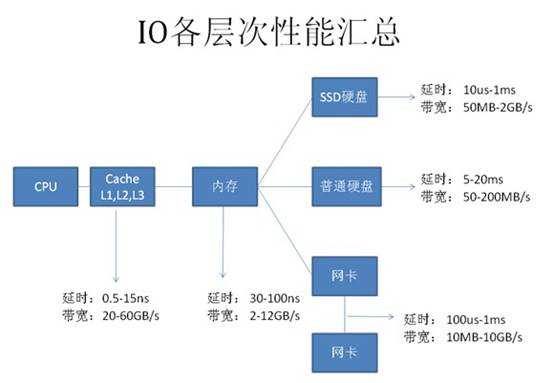
每种硬件主要的工作内容:
CPU及内存:缓存数据访问、比较、排序、事务检测、SQL解析、函数或逻辑运算;
网络:结果数据传输、SQL请求、远程数据库访问(dblink);
硬盘:数据访问、数据写入、日志记录、大数据量排序、大表连接。
2、资源优化方法:
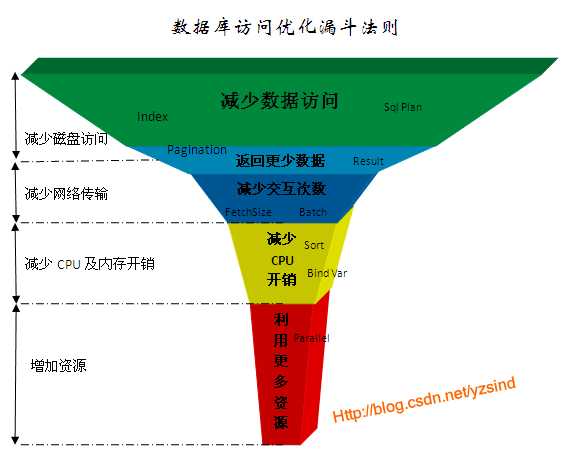
这个优化法则归纳为5个层次:
1、 减少数据访问(减少磁盘访问)
2、 返回更少数据(减少网络传输或磁盘访问)
3、 减少交互次数(减少网络传输)
4、 减少服务器CPU开销(减少CPU及内存开销)
5、 利用更多资源(增加资源)
我们任何一个SQL的性能优化都应该按这个规则由上到下来诊断问题并提出解决方案,而不应该首先想到的是增加资源解决问题。
以下是每个优化法则层级对应优化效果及成本经验参考:
|
优化法则 |
性能提升效果 |
优化成本 |
|
减少数据访问 |
1~1000 |
低 |
|
返回更少数据 |
1~100 |
低 |
|
减少交互次数 |
1~20 |
低 |
|
减少服务器CPU开销 |
1~5 |
低 |
|
利用更多资源 |
@~10 |
高 |
3、详细介绍
一些总结
1.对查询进行优化,要尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。 2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描
3.应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。 select id from t where num=10 or Name = ‘admin‘ 可以这样查询: select id from t where num = 10 union all select id from t where Name = ‘admin‘ 4.应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描
5.in 和 not in 也要慎用,否则会导致全表扫描对于连续的数值,能用 between 就不要用 in 了很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2 = 100 应改为: select id from t where num = 100*2 8.对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。 9.select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的。 10.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。 11.应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。 12.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。(这是因为引擎在处理查询和连 接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了)。 13.尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。14.尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。 15. 避免频繁创建和删除临时表,以减少系统表资源的消耗。临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件, 最好使用导出表。 16.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。 17.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。 18.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。 19.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。 20.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。 21.在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF 。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC 消息。 22.尽量避免大事务操作,提高系统并发能力。 23.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。 24.拆分大的 DELETE 或INSERT 语句,批量提交SQL语句
如果你有一个大的处理,你一定把其拆分,使用 LIMIT oracle(rownum),sqlserver(top)条件是一个好的方法。下面是一个mysql示例: while(1){ //每次只做1000条 mysql_query(“delete from logs where log_date <= ’2012-11-01’ limit 1000”); if(mysql_affected_rows() == 0){ //删除完成,退出! break; } //每次暂停一段时间,释放表让其他进程/线程访问。 usleep(50000) }
参考:https://blog.csdn.net/weixin_39106371/article/details/82117148
https://www.cnblogs.com/yunfeifei/p/3850440.html
其他:https://www.trinea.cn/android/performance/
https://blog.csdn.net/zhangbijun1230/article/details/81608252
原文:https://www.cnblogs.com/51python/p/10878079.html