1、模块初识
2、数据类型初识
3、数据运算
4、列表、元组操作
5、字符串操作
6、字典操作
7、集合操作
8、文件操作
9、字符编码与转换
Python的强大之处在于他有非常丰富和强大的标准库和第三方库,几乎你想实现的任何功能都有相应的Python库支持,以后的课程中会深入讲解常用到的各种库,现在,我们先来象征性的学2个简单的。
sys
|
1
2
3
4
5
6
7
8
9
10
11
|
#!/usr/bin/env python# -*- coding: utf-8 -*-import sysprint(sys.argv)#输出$ python test.py helo world[‘test.py‘, ‘helo‘, ‘world‘] #把执行脚本时传递的参数获取到了 |
os
|
1
2
3
4
5
6
|
#!/usr/bin/env python# -*- coding: utf-8 -*-import osos.system("df -h") #调用系统命令 |
完全结合一下
|
1
2
3
|
import os,sysos.system(‘‘.join(sys.argv[1:])) #把用户的输入的参数当作一条命令交给os.system来执行 |
自己写个模块
python tab补全模块
1 import sys 2 import readline 3 import rlcompleter 4 5 if sys.platform == ‘darwin‘ and sys.version_info[0] == 2: 6 readline.parse_and_bind("bind ^I rl_complete") 7 else: 8 readline.parse_and_bind("tab: complete") # linux and python3 on mac 9 10 for mac

1 #!/usr/bin/env python 2 # python startup file 3 import sys 4 import readline 5 import rlcompleter 6 import atexit 7 import os 8 # tab completion 9 readline.parse_and_bind(‘tab: complete‘) 10 # history file 11 histfile = os.path.join(os.environ[‘HOME‘], ‘.pythonhistory‘) 12 try: 13 readline.read_history_file(histfile) 14 except IOError: 15 pass 16 atexit.register(readline.write_history_file, histfile) 17 del os, histfile, readline, rlcompleter 18 19 for Linux
写完保存后就可以使用了
|
1
2
3
4
5
|
localhost:~ jieli$ pythonPython 2.7.10 (default, Oct 23 2015, 18:05:06)[GCC 4.2.1 Compatible Apple LLVM 7.0.0 (clang-700.0.59.5)] on darwinType "help", "copyright", "credits" or "license" for more information.>>> import tab |
你会发现,上面自己写的tab.py模块只能在当前目录下导入,如果想在系统的何何一个地方都使用怎么办呢? 此时你就要把这个tab.py放到python全局环境变量目录里啦,基本一般都放在一个叫 Python/2.7/site-packages 目录下,这个目录在不同的OS里放的位置不一样,用 print(sys.path) 可以查看python环境变量列表。
2 是一个整数的例子。
长整数 不过是大一些的整数。
3.23和52.3E-4是浮点数的例子。E标记表示10的幂。在这里,52.3E-4表示52.3 * 10-4。
(-5+4j)和(2.3-4.6j)是复数的例子,其中-5,4为实数,j为虚数,数学中表示复数是什么?。
int(整型)
"hello world"
|
1
2
3
4
|
name = "alex"print "i am %s " % name #输出: i am alex |
PS: 字符串是 %s;整数 %d;浮点数%f
|
1
2
3
|
name_list = [‘alex‘, ‘seven‘, ‘eric‘]或name_list = list([‘alex‘, ‘seven‘, ‘eric‘]) |
基本操作:
|
1
2
3
|
ages = (11, 22, 33, 44, 55)或ages = tuple((11, 22, 33, 44, 55)) |
|
1
2
3
|
person = {"name": "mr.wu", ‘age‘: 18}或person = dict({"name": "mr.wu", ‘age‘: 18}) |
常用操作:
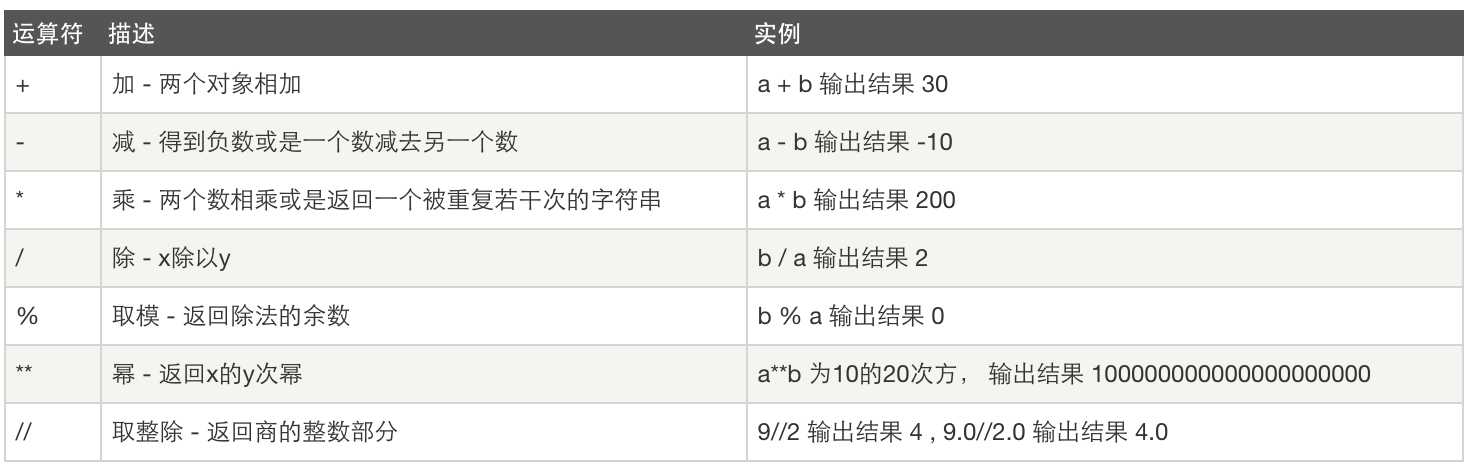
比较运算:

赋值运算:
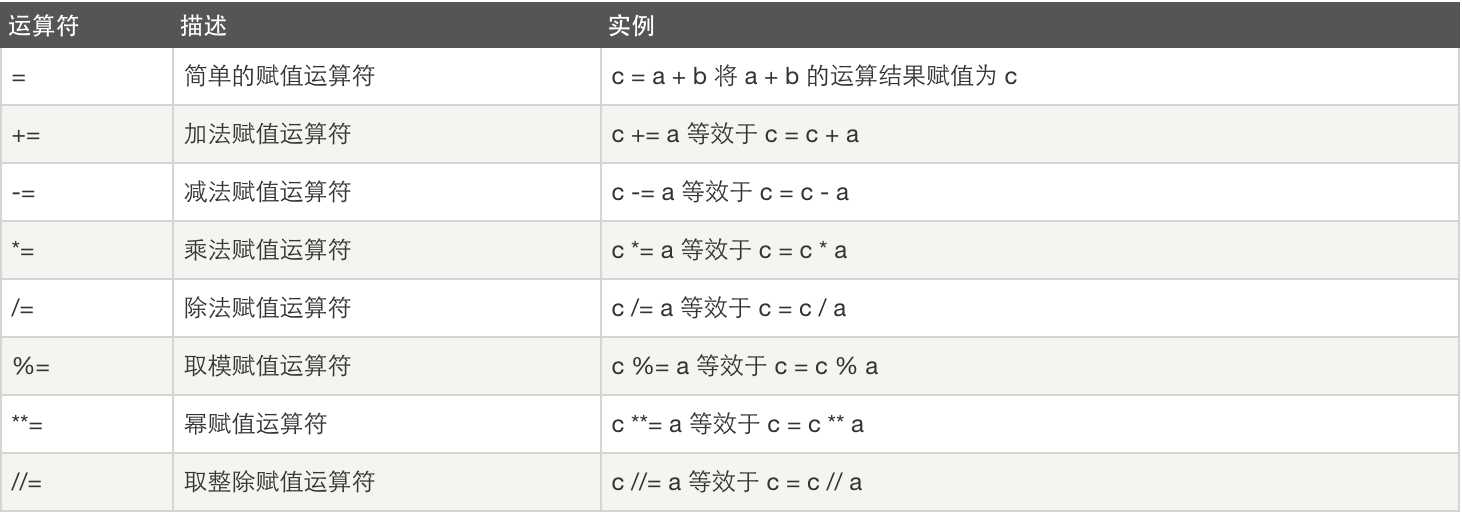
逻辑运算:

成员运算:

身份运算:

位运算:
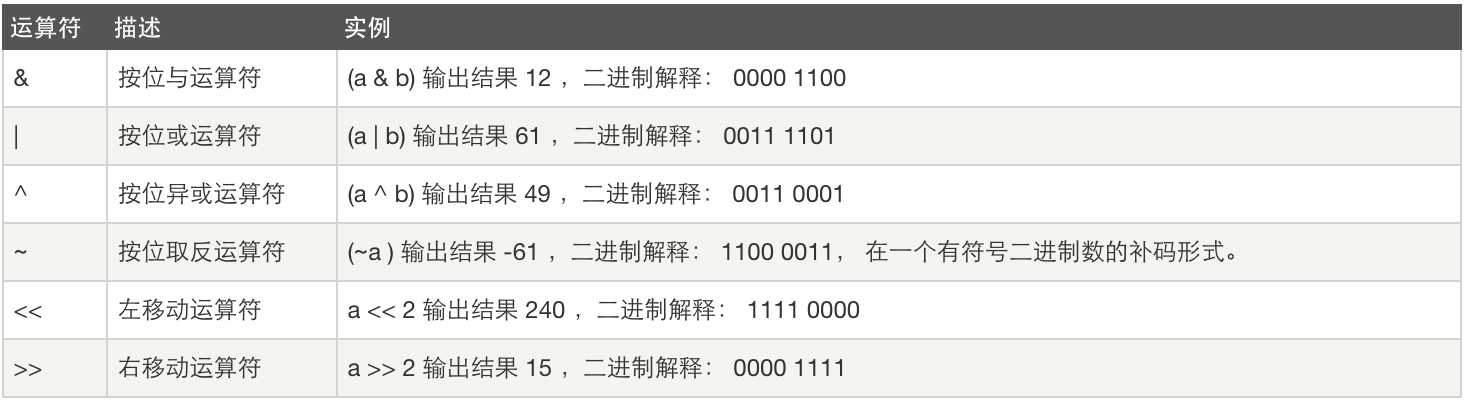
*按位取反运算规则(按位取反再加1) 详解http://blog.csdn.net/wenxinwukui234/article/details/42119265
运算符优先级:
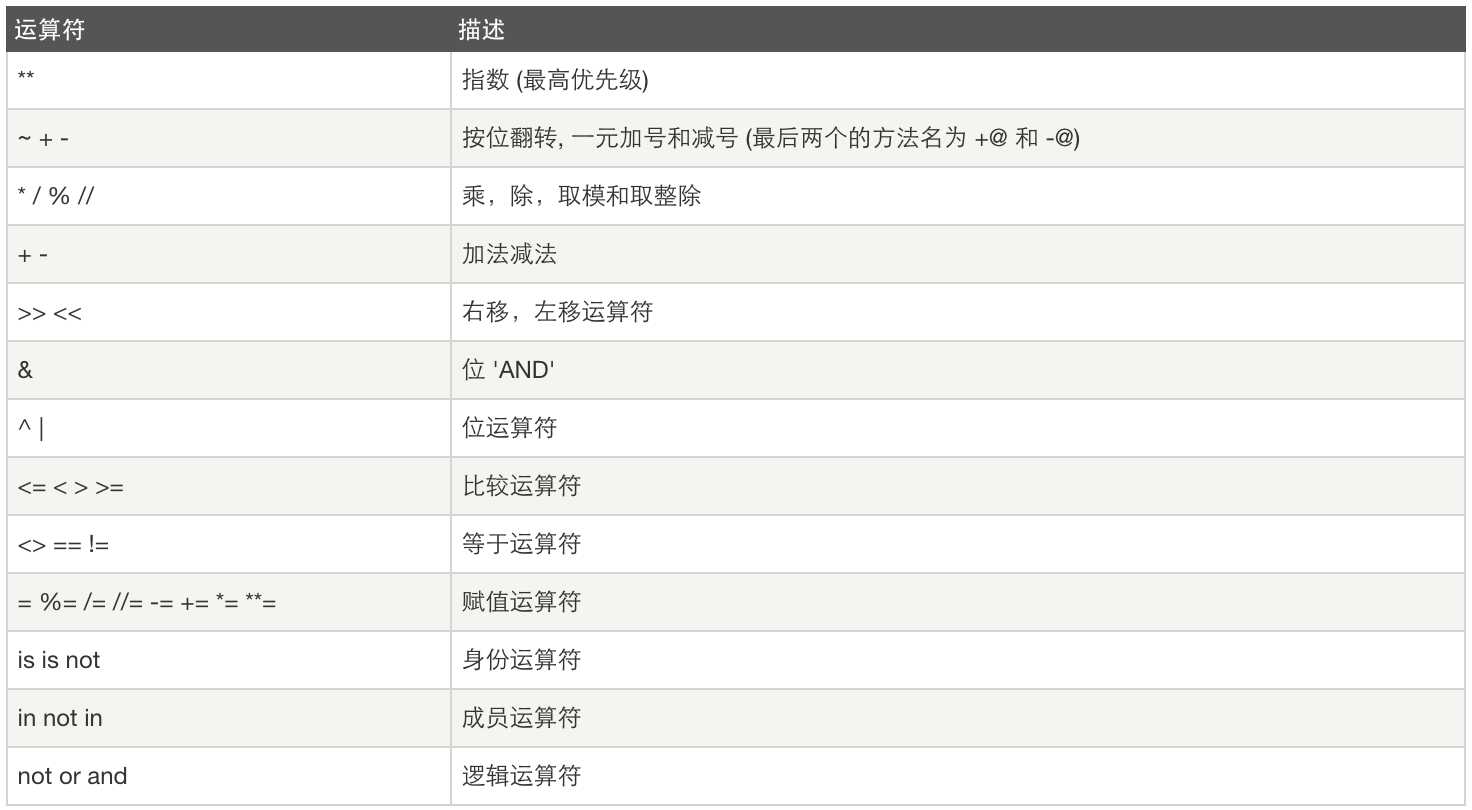
更多内容:猛击这里
列表是我们最以后最常用的数据类型之一,通过列表可以对数据实现最方便的存储、修改等操作
定义列表
|
1
|
names = [‘Alex‘,"Tenglan",‘Eric‘] |
通过下标访问列表中的元素,下标从0开始计数
|
1
2
3
4
5
6
7
8
|
>>> names[0]‘Alex‘>>> names[2]‘Eric‘>>> names[-1]‘Eric‘>>> names[-2] #还可以倒着取‘Tenglan‘ |
切片:取多个元素
>>> names = ["Alex","Tenglan","Eric","Rain","Tom","Amy"] >>> names[1:4] #取下标1至下标4之间的数字,包括1,不包括4 [‘Tenglan‘, ‘Eric‘, ‘Rain‘] >>> names[1:-1] #取下标1至-1的值,不包括-1 [‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘] >>> names[0:3] [‘Alex‘, ‘Tenglan‘, ‘Eric‘] >>> names[:3] #如果是从头开始取,0可以忽略,跟上句效果一样 [‘Alex‘, ‘Tenglan‘, ‘Eric‘] >>> names[3:] #如果想取最后一个,必须不能写-1,只能这么写 [‘Rain‘, ‘Tom‘, ‘Amy‘] >>> names[3:-1] #这样-1就不会被包含了 [‘Rain‘, ‘Tom‘] >>> names[0::2] #后面的2是代表,每隔一个元素,就取一个 [‘Alex‘, ‘Eric‘, ‘Tom‘] >>> names[::2] #和上句效果一样 [‘Alex‘, ‘Eric‘, ‘Tom‘]
追加
>>> names [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘] >>> names.append("我是新来的") >>> names [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘]
插入
>>> names [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘] >>> names.insert(2,"强行从Eric前面插入") >>> names [‘Alex‘, ‘Tenglan‘, ‘强行从Eric前面插入‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘] >>> names.insert(5,"从eric后面插入试试新姿势") >>> names [‘Alex‘, ‘Tenglan‘, ‘强行从Eric前面插入‘, ‘Eric‘, ‘Rain‘, ‘从eric后面插入试试新姿势‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘]
修改
>>> names [‘Alex‘, ‘Tenglan‘, ‘强行从Eric前面插入‘, ‘Eric‘, ‘Rain‘, ‘从eric后面插入试试新姿势‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘] >>> names[2] = "该换人了" >>> names [‘Alex‘, ‘Tenglan‘, ‘该换人了‘, ‘Eric‘, ‘Rain‘, ‘从eric后面插入试试新姿势‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘]
删除
>>> del names[2] >>> names [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘从eric后面插入试试新姿势‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘] >>> del names[4] >>> names [‘Alex‘, ‘Tenglan‘, ‘Eric‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘] >>> >>> names.remove("Eric") #删除指定元素 >>> names [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, ‘我是新来的‘] >>> names.pop() #删除列表最后一个值 ‘我是新来的‘ >>> names [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘]
扩展
>>> names [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘] >>> b = [1,2,3] >>> names.extend(b) >>> names [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, 1, 2, 3]
拷贝
>>> names [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, 1, 2, 3] >>> name_copy = names.copy() >>> name_copy [‘Alex‘, ‘Tenglan‘, ‘Rain‘, ‘Tom‘, ‘Amy‘, 1, 2, 3]
统计
>>> names [‘Alex‘, ‘Tenglan‘, ‘Amy‘, ‘Tom‘, ‘Amy‘, 1, 2, 3] >>> names.count("Amy")
排序&翻转
>>> names [‘Alex‘, ‘Tenglan‘, ‘Amy‘, ‘Tom‘, ‘Amy‘, 1, 2, 3] >>> names.sort() #排序 Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: unorderable types: int() < str() #3.0里不同数据类型不能放在一起排序了,擦 >>> names[-3] = ‘1‘ >>> names[-2] = ‘2‘ >>> names[-1] = ‘3‘ >>> names [‘Alex‘, ‘Amy‘, ‘Amy‘, ‘Tenglan‘, ‘Tom‘, ‘1‘, ‘2‘, ‘3‘] >>> names.sort() >>> names [‘1‘, ‘2‘, ‘3‘, ‘Alex‘, ‘Amy‘, ‘Amy‘, ‘Tenglan‘, ‘Tom‘] >>> names.reverse() #反转 >>> names [‘Tom‘, ‘Tenglan‘, ‘Amy‘, ‘Amy‘, ‘Alex‘, ‘3‘, ‘2‘, ‘1‘]
获取下标
>>> names [‘Tom‘, ‘Tenglan‘, ‘Amy‘, ‘Amy‘, ‘Alex‘, ‘3‘, ‘2‘, ‘1‘] >>> names.index("Amy") 2 #只返回找到的第一个下标
元组其实跟列表差不多,也是存一组数,只不是它一旦创建,便不能再修改,所以又叫只读列表
语法
|
1
|
names = ("alex","jack","eric") |
它只有2个方法,一个是count,一个是index,完毕。
请闭眼写出以下程序。
程序:购物车程序
需求:
原文:https://www.cnblogs.com/jian-ger/p/10856471.html
