HashMap的位桶数组实际使用时,大小是可变的。如果位桶数组中的元素达到(0.75*数组 length), 就重新调整数组大小变为原来2倍大小。
未扩容时的代码如下:
/** * 新建一个节点 * put方法增加键值对,键相同时覆盖相应节点,不同时放在最后 * 在table同一个地址的next增加值 * 重写toString方法 * get的方法 */ package mypro09; public class SxtHashMap03 { Node2[] table; //位桶数组。bucket array int size; //存放键值对的个数 public SxtHashMap03(){ table = new Node2[16]; //长度一般定义为2的整数幂 } public Object get(Object key) { int hash = myHash(key.hashCode(), table.length); Object value = null; if(table[hash]!=null) { Node2 temp = table[hash]; while(temp!=null) { if(temp.key.equals(key)) { //如果相等,则说明了找到键值对,返回相应的value value = temp.value; break; }else { temp = temp.next; } } } return value; } public void put(Object key, Object value) { //如果要完善。还需要考虑数组扩容问题!!!见ArrayList!!!! //定义了新的节点对象 Node2 newNode = new Node2(); newNode.hash = myHash(key.hashCode(), table.length); newNode.key = key; newNode.value = value; newNode.next = null; Node2 temp = table[newNode.hash]; Node2 iterLast = null; //正在遍历的最后一个元素,为保存遍历的最后一个节点信息 boolean keyRepeat = false; //在循环外判断循环到最后一个也没有找到重复key的情况 if(temp==null) { //此处数组元素为空,则直接将新节点放进去 table[newNode.hash] = newNode; }else { //此处数组元素不为空,遍历对应链表 while(temp!=null) { //判断key如果重复,则覆盖 if(temp.key.equals(key)) { keyRepeat = true; temp.value = value; break; }else { //如果key不重复,则遍历下一个 iterLast = temp; temp = temp.next; } } if(!keyRepeat) { //没有发生key重复的情况,则添加到链表最后 iterLast.next = newNode; } } } @Override public String toString() { //[10:aa, 20:bb] StringBuilder sb = new StringBuilder("["); //遍历bucket数组 for(int i=0;i<table.length;i++) { Node2 temp = table[i]; //遍历链表 while(temp!=null) { sb.append(temp.key+":"+temp.value+","); temp = temp.next; } } sb.setCharAt(sb.length()-1, ‘]‘); return sb.toString(); } //用v=key.hashCode,求出哈希值 public static int myHash(int v, int length) { // System.out.println("hash in myHash" + (v&(length-1))); //直接位运算,效率较高 // System.out.println("hash in myHash" + (v%(length))); //直接取模运算,效率较低 return v&(length-1); } public static void main(String[] args) { SxtHashMap03 map = new SxtHashMap03(); map.put(10, "aa"); map.put(20, "bb"); map.put(30, "cc"); map.put(30, "22c"); map.put(53, "gg"); map.put(69, "ff"); map.put(85, "shua"); System.out.println(map); System.out.println(map.get(53)); // for(int i=10;i<100;i++) { // System.out.println(i+"---"+myHash(i, 16)); //53,69,85 // } } }
对put函数增加扩容功能,为方便验证算法正确此处将table的length改为了4
修改后如下:
int tNodeCount = 0; //存放位桶数组元素个数 public void put(Object key, Object value) { //如果要完善。还需要考虑数组扩容问题!!!见ArrayList!!!! //定义了新的节点对象 Node2 newNode = new Node2(); newNode.hash = myHash(key.hashCode(), table.length); newNode.key = key; newNode.value = value; newNode.next = null; Node2 temp = table[newNode.hash]; Node2 iterLast = null; //正在遍历的最后一个元素,为保存遍历的最后一个节点信息 boolean keyRepeat = false; //在循环外判断循环到最后一个也没有找到重复key的情况 if(temp==null) { //此处数组元素为空,则直接将新节点放进去 tNodeCount++; table[newNode.hash] = newNode; //什么时候扩容 if(tNodeCount==0.75*table.length) { //怎么扩容,如果位桶数组中的元素达到(0.75*数组 length),就重新调整数组大小变为原来2倍大小。 Node2[] newTable = new Node2[table.length<<1]; //4-->4*2 System.arraycopy(table, 0, newTable, 0, table.length); table = newTable; } }else { //此处数组元素不为空,遍历对应链表 while(temp!=null) { //判断key如果重复,则覆盖 if(temp.key.equals(key)) { keyRepeat = true; temp.value = value; break; }else { //如果key不重复,则遍历下一个 iterLast = temp; temp = temp.next; } } if(!keyRepeat) { //没有发生key重复的情况,则添加到链表最后 iterLast.next = newNode; } } }
利用断点,可以看到原本table.length = 4,现在改为了table.length = 8
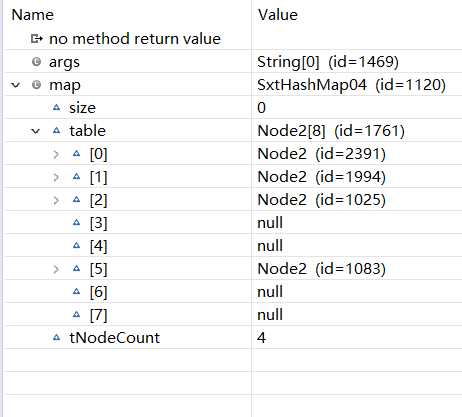
原文:https://www.cnblogs.com/kl-1998/p/10804609.html