你好如果你搜到这篇文章,说明你正在经历spark编译的各种坑,我当时是编译了4天,还没有成功,心态崩了,后来还是在小伙伴的帮助下才成功的。
以下的内容希望能助你成功
这个过程不是让你瞪着眼睛看要动手检查
echo $JAVA_HOME
echo $SCALA_HOME
echo $MAVEN_HOME
echo $HADOOP_HOME
| 软件 | Hadoop | scala | maven | JDK |
|---|---|---|---|---|
| 版本 | 2.6.0-cdh5.7.0 | 2.11.12 | 3.6.1 | jdk1.8.0_45 |
如果你是scala2.11.8,应该也没有问题,因为看下图,也就是说我们的spark2.4.2版本对应着2.11版本的任何一个小版本的scala都可以。

但是建议用scala因为我用scala2.11.8编译失败N次。 彩蛋:官网部署文档:http://spark.apache.org/docs/latest/building-spark.html maven一定要用最新版
[root@hadoop001 sourcecode]# pwd /opt/sourcecode [root@hadoop001 sourcecode]# wget https://archive.apache.org/dist/spark/spark-2.4.2/spark-2.4.2.tgz [root@hadoop001 sourcecode]# ll total 28208 -rw-r--r-- 1 root root 14222744 May 1 12:34 spark-2.2.0.tgz [root@hadoop001 sourcecode]#
[root@hadoop001 sourcecode]#tar -zxvf spark-2.4.2.tgz -C /home/hadoop/app/ 小坑:解压以后一定要看一下用户和用户组是否发生改变 [root@hadoop001 sourcecode]# cd /home/hadoop/app/spark-2.4.2
[root@hadoop001 spark-2.4.2]# vim dev/make-distribution.sh
**修改**
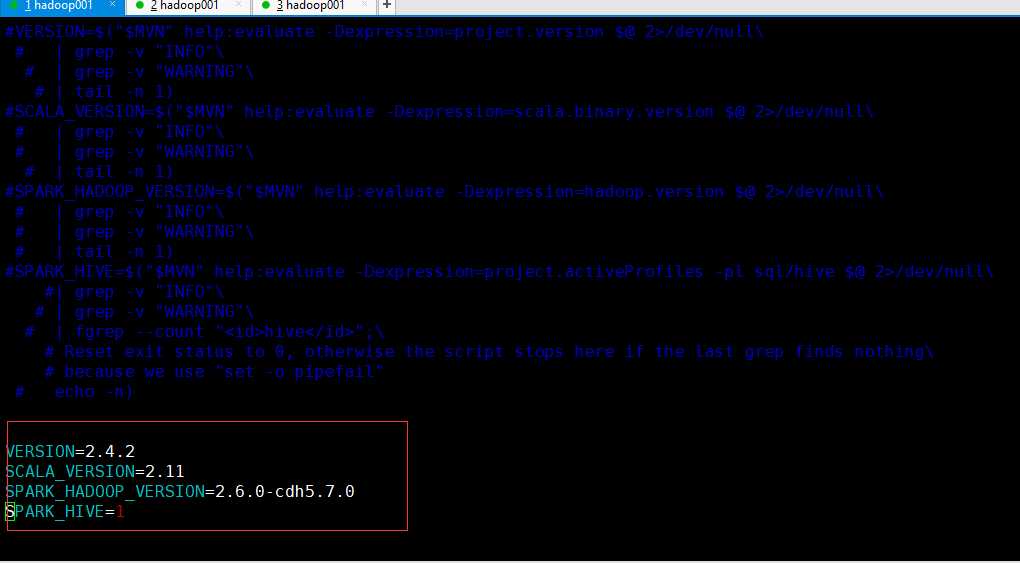
VERSION=$("$MVN" help:evaluate -Dexpression=project.version $@ 2>/dev/null| grep -v "INFO"| grep -v "WARNING"| tail -n 1)
SCALA_VERSION=$("$MVN" help:evaluate -Dexpression=scala.binary.version $@ 2>/dev/null| grep -v "INFO"| grep -v "WARNING"| tail -n 1)
SPARK_HADOOP_VERSION=$("$MVN" help:evaluate -Dexpression=hadoop.version $@ 2>/dev/null| grep -v "INFO"| grep -v "WARNING"| tail -n 1)
SPARK_HIVE=$("$MVN" help:evaluate -Dexpression=project.activeProfiles -pl sql/hive $@ 2>/dev/null| grep -v "INFO"| grep -v "WARNING"| fgrep --count "<id>hive</id>";# Reset exit status to 0, otherwise the script stops here if the last grep finds nothing# because we use "set -o pipefail"
echo -n)
**修改为**
VERSION=2.4.2 ##spark版本
SCALA_VERSION=2.11
SPARK_HADOOP_VERSION=2.6.0-cdh5.7.0
SPARK_HIVE=1
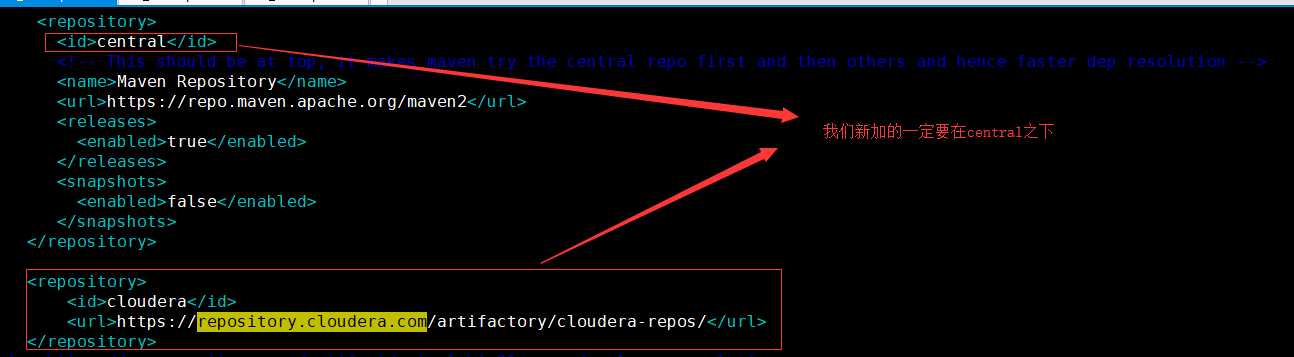
在 <repositories> </repositories>块中添加一下内容,<id>central</id>部分的内容地须在第一个位置
[hadoop@hadoop614 spark-2.4.2]$ vim pom.xml
<repositories>
.......
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
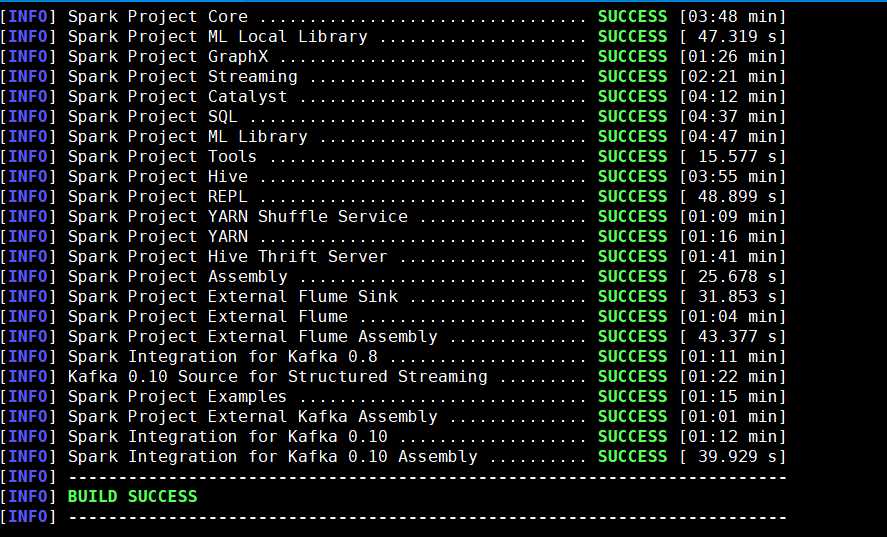
[root@hadoop001 spark-2.4.2]#./dev/make-distribution.sh --name 2.6.0-cdh5.7.0 --tgz -Phadoop-2.6 -Dhadoop.version=2.6.0-cdh5.7.0 -Phive -Phive-thriftserv
er -Pyarn -Pkubernetes
第一次时长无上限,我有一个同事编译了6个小时
蒋蒋蒋!!!编译成功!!!是不是很羡慕,但是自己的却各种报错,那看看我遇到的坑吧!
[INFO] Compiling 203 Scala sources and 9 Java sources to /Users/me/Development/spark/core/target/scala-2.12/classes... [ERROR] Java heap space -> [Help 1]
您需要通过设置来配置Maven以使用比平时更多的内存MAVEN_OPTS:
export MAVEN_OPTS="-Xmx2g -XX:ReservedCodeCacheSize=512m"
小提示:配置在你的maven家目录配置的文件里
[ERROR] Plugin org.codehaus.mojo:build-helper-maven-plugin:3.0.0 or one of its dependencies could not be resolved: Failed to read artifact descriptor for org.codehaus.mojo:build-helper-maven-plugin:jar:3.0.0: Could not transfer artifact org.codehaus.mojo:build-helper-maven-plugin:pom:3.0.0 from/to central (http://maven.aliyun.com/nexus/content/groups/public): maven.aliyun.com:80 failed to respond -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/PluginResolutionException 解决方法: 在pom文件中添加以下依赖即可 <dependency> <groupId>org.codehaus.mojo</groupId> <artifactId>build-helper-maven-plugin</artifactId> <version>3.0.0</version> </dependency>
说明:这个错误非常崩溃,因为他可能是不同的地方报错 [ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile (scala-compile-first) on project spark-core_2.11: Execution scala-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.2:compile failed.: CompileFailed -> [Help 1]

1.你上网搜这个问题一定会看到这样的 在spark的pom文件中添加这个依赖,但是下边的那个version3.2.2,你要看自己的报错处的具体数字,我的是3.2.2 <dependency> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> </dependency> 不管怎么样,你先加上吧,因为也没有别的办法,如果编译的过程中报错说pom文件有问题,具体就是显示你新加的那个位置有问题,那你就好好检查一下,如果没有问题还是报错,那就删了吧!
2.修改spark的pom文件这里的true,说改了这个在编译就能解决这个问题。 <scalaVersion>${scala.version}</scalaVersion> <recompileMode>incremental</recompileMode> <useZincServer>true</useZincServer>
3.如果你试完了以上方法还是报错,你需要检查一下你的zinc进程是否还留着,一定要杀死,要不然会让你的编译done住或者直接被莫名奇妙的杀死。 图解莫名奇妙的杀死一般会报错/home/hadoop/app/spark-2.4.2/build/mvn的第168行"${MVN_BIN}" -DzincPort=${ZINC_PORT} "$@" killed
错误大约是这样描述的,当时没有保存下来,若是这个错基本上就是因为没有杀死zinc进程,导致端口号被占用

下图是我编译的时候检查的时候一个各种进程的残留,可以看到有很多zinc进程残留,我们需要杀死,这些都是我的经验,以及查询资料获得的信息,
若果有大佬发现不对请及时提点。
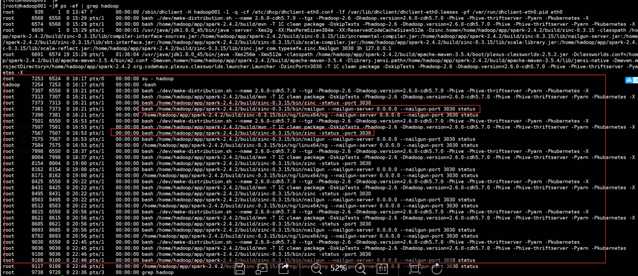
解决方法 ps -ef |grep hadoop 看看有关于zinc的进程全部杀掉 再一次进行编译。
4.如果你进行了以上方法还是没有编译成功,或者说报错都没有改变,还有一种情况就是那么在你确定环境确实没有问题的情况下我们要进行一下操作 进入spark家目录,执行vim dev/make-distribution.sh,找到第39行(MVN="$SPARK_HOME/build/mvn") 把它注掉并且添加MVN="${MAVEN_HOME}/bin/mvn"
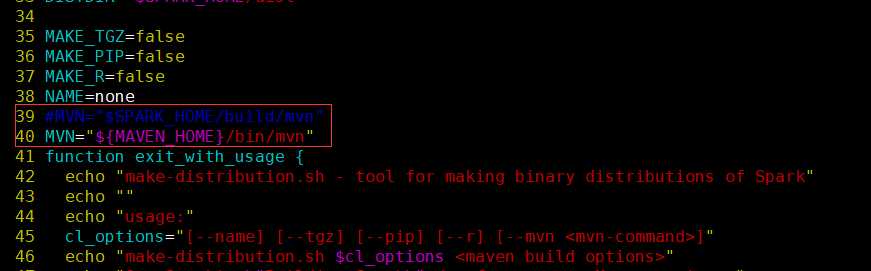
最后这一步修改完了,一般就会成功了,具体为什么这样改,我不是很清楚,当时小伙伴帮助我的时候就这样改的。
如果你编译成功了,那我们来部署吧 [root@hadoop001 spark-2.4.2]# ll -rw-rw-r-- 1 root root 224531756 May 2 00:49 spark-2.4.2-bin-2.6.0-cdh5.7.0.tgz 这个包就是我们编译出来的包
[root@hadoop001 spark-2.4.2]# tar -zxvf spark-2.4.2-bin-2.6.0-cdh5.7.0.tgz -C /home/hadoop/app/ [root@hadoop001 app]# ll drwxrwxr-x 11 root root 4096 May 2 00:49 spark-2.4.2-bin-2.6.0-cdh5.7.0
[root@hadoop001 app] vim /etc/profile export SPARK_HOME=/home/hadoop/app/spark-2.4.2-bin-2.6.0-cdh5.7.0 export PATH=${SPARK_HOME}/bin:$PATH [root@hadoop001 app] source /etc/profile
[root@hadoop001 app]# spark-shell 19/05/02 14:02:25 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Using Spark‘s default log4j profile: org/apache/spark/log4j-defaults.properties Setting default log level to "WARN". To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel). Spark context Web UI available at http://hadoop001:4040 Spark context available as ‘sc‘ (master = local[*], app id = local-1556776953433). Spark session available as ‘spark‘. Welcome to ____ __ / __/__ ___ _____/ /__ _\ \/ _ \/ _ `/ __/ ‘_/ /___/ .__/\_,_/_/ /_/\_\ version 2.4.2 /_/ Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_45) Type in expressions to have them evaluated. Type :help for more information. scala>


原文:https://www.cnblogs.com/xuziyu/p/10803959.html