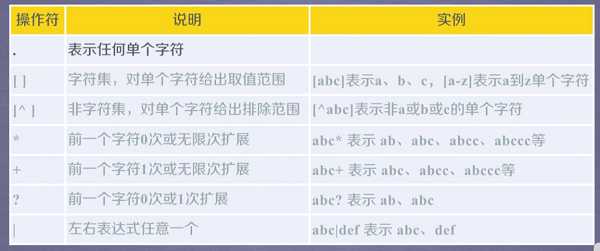
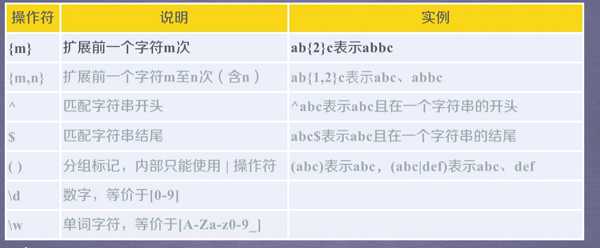
常用正则表达式操作符
. :表示任何单位个字符
[ ]:字符集,表示对单个字符给出取值范围,[abc]表示a,b,c,[a-z]表示a到z单个字符
[^ ]:非字符集,对单个给出排除范围,[^abc]表示非a或非b或非c的单个字符
*:前一个字符0次或者无限次扩展,*abc表示ab abc abcc abccc等
+:前一个字符1次或者无限次扩展
?:前一个字符o次或者1次扩展
|:左右表达式任意一个,abc|edf表示abc 或者def


当字符串中有转义字符是建议使用原生字符串raw string 即r‘text‘
#!/usr/bin/python3 import re match=re.search(r‘[1-9]\d{5}‘,‘BIT 100086‘) if match: print(match.group(0))
re.compile将原生正则表达式字符串编译成正则表达式对象,可以直接调用该对象(优点:可以多次调用该对象)
pat=re.compile(r‘[1-9]\d{5}‘) result=pat.search(‘BIT100081‘) print(result.group(0))
常用函数用法
#!/usr/bin/python3 import re match=re.search(r‘[1-9]\d{5}‘,‘BIT 100086‘) if match: print(match.group(0)) match1=re.findall(r‘[1-9]\d{5}‘,‘BIT100081 TSU100084‘) print(match1) match2=re.split(r‘[1-9]\d{5}‘,‘BIT100081 TSU100084‘) print(match2) match21=re.split(r‘[1-9]\d{5}‘,‘BIT100081 TSU100084‘,maxsplit=1) print(match21) for m in re.finditer(r‘[1-9]\d{5}‘,‘BIT100081 TSU100084‘): if m: print(‘m:‘,m.group(0)) match3=re.sub(r‘[1-9]\d{5}‘,‘zipCode‘,‘BIT100081 TSU100084‘) print(‘match3:‘,match3)
match对象的常用函数
import re m=re.search(r‘[1-9]\d{5}‘,‘TSU100084 BIT100081‘) print(‘将要匹配的字符串:‘+m.string) print(‘将要匹配的正则表达式:‘,m.re) print(‘开始匹配的起始位置:‘,m.pos) print(‘开始匹配的结束位置:‘,m.endpos) print(‘返回匹配的结果:‘,m.group(0)) print(‘匹配到的起始位置:‘,m.start()) print(‘匹配到的结束位置:‘,m.end()) print(‘匹配到的起始位置和结束位置:‘,m.span())
将要匹配的字符串:TSU100084 BIT100081 将要匹配的正则表达式: re.compile(‘[1-9]\\d{5}‘) 开始匹配的起始位置: 0 开始匹配的结束位置: 19 返回匹配的结果: 100084 匹配到的起始位置: 3 匹配到的结束位置: 9 匹配到的起始位置和结束位置: (3, 9)
re库的贪婪匹配与最小匹配
re库默认贪婪匹配,如需最小匹配则需要在正则表达式合适的地方加?



原文:https://www.cnblogs.com/liberate20/p/10784104.html