hadoop的思想起源于google,google对于大量网页的存储:利用冗余储存方法应对节点失效时数据的挽回,page-rank网页价值计算方法,分散计算任务,
hdfs守护进程,
记录文件是如何分割成数据块的,以及数据块存在哪些节点上,
对内存和I/O进行集中管理,
是单点发生故障将使集群崩溃
监控HDFS状态的辅助后台程序,
每个集群都有一个,
与NameNode进行通讯,定期保存HDFS元数据快照,
当NameNode故障可以作为备用NameNode使用
每台从服务器都运行一个,
负责把HDFS数据块读写到本地文件系统
用于处理作业(用户提交代码)的后台程序,
决定有哪些文件参与处理,然后切割task并分配节点,
监控task,重启失败的task(于不同的节点),
每个集群只有唯一一个JobTracker,位于Master节点
位于slave节点上,与datanode结合(代码与数据一起的原则),
管理各自节点上的task(由jobtracker分配)
每个节点只有一个tasktracker,但一个tasktracker可以启动多个jvm,用于并行执行map或者reduce任务
与jobtracker交互
# 关闭 “系统防火墙” 命令
systemctl stop firewalld.service
# 关闭 “系统防火墙” 自启动命令
systemctl disable firewalld.service
# 关闭 “SELinux”命令
setenforce 0
# 关闭“SELinux”系统系统自启动服务
vi /etc/selinux/config
# 修改内容
SELINUX=disabled
hostnamectl set-hostname master #centos7
adduser hadoop
passwd hadoop
#输入两次密码
?
#将新建的hadoop用户添加到hadoop用户组
usermod -a -G hadoop hadoop
cat /etc/group
?
#赋予root权限
vim /etc/sudoers
?
hadoop ALL=(ALL) ALL
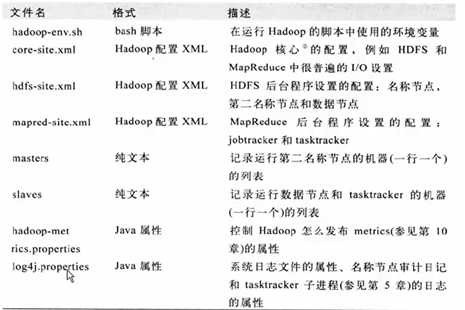

配置hadoop-env.sh(hadoop的一些环境变量配置)
export JAVA_HOME=/usr/local/java/ #jdk目录
配置yarn-env.sh
# export JAVA_HOME=/home/y/libexec/jdk1.6.0/
if [ "$JAVA_HOME" != "" ]; then
#echo "run java in $JAVA_HOME"
JAVA_HOME=/usr/local/java/ #jdk目录
fi
配置core-site.xml(hadoop的核心配置)
<configuration>
<property>
<!-- NameNode的IP地址和端口 -->
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<!-- 制定hadoop的temp文件夹地址 -->
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/temp/</value>
</property>
</configuration>
配置hdfs-site.xml(hdfs 的核心配置)
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/dfs/name/</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>file:/opt/hadoop/dfs/data/</value>
</property>
<property>
<!-- 文件备份数量(份) -->
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
配置mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
配置yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<!-- 客户端地址,向 resouce 请求地址 -->
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<!-- 调入器调入地址 -->
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<!-- notemanager 汇报心跳等任务 -->
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<!-- 管理员地址,可发送管理命令等操作 -->
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<!-- 通过浏览器看到 hadoop 情况 -->
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
配置slaves文件,删除localhost
slave1
slave2
scp -r /opt/hadoop/ slave:/opt/
先格式化namenode
hdfs namenode -format
启动
start-all.sh
验证
hadoop jar /opt/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.5.jar pi 10 10
参考:http://hadoop.apache.org/docs/r2.7.5/hadoop-project-dist/hadoop-common/FileSystemShell.html
mapreduce待续...
原文:https://www.cnblogs.com/REdrsnow/p/10742086.html