Kullback-Leibler Divergence,即K-L散度,是一种量化两种概率分布P和Q之间差异的方式,又叫相对熵。更简单的、近似的分布来替代观察数据或太复杂的分布。K-L散度能帮助我们度量使用一个分布来近似另一个分布时所损失的信息。Cross Entropy 而非K-L Divergence。我们从下面这个问题出发思考K-L散度。
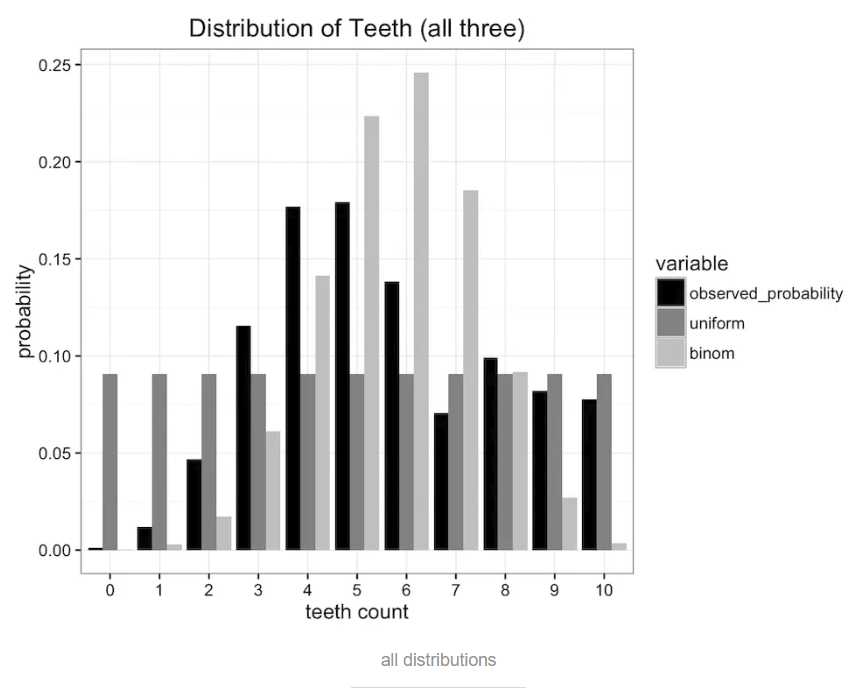
假设我们是一群太空科学家,经过遥远的旅行,来到了一颗新发现的星球。在这个星球上,生存着一种长有牙齿的蠕虫,引起了我们的研究兴趣。我们发现这种蠕虫生有10颗牙齿,但是因为不注意口腔卫生,又喜欢嚼东西,许多蠕虫会掉牙。收集大量样本之后,我们得到关于蠕虫牙齿数量的经验分布,如下图所示
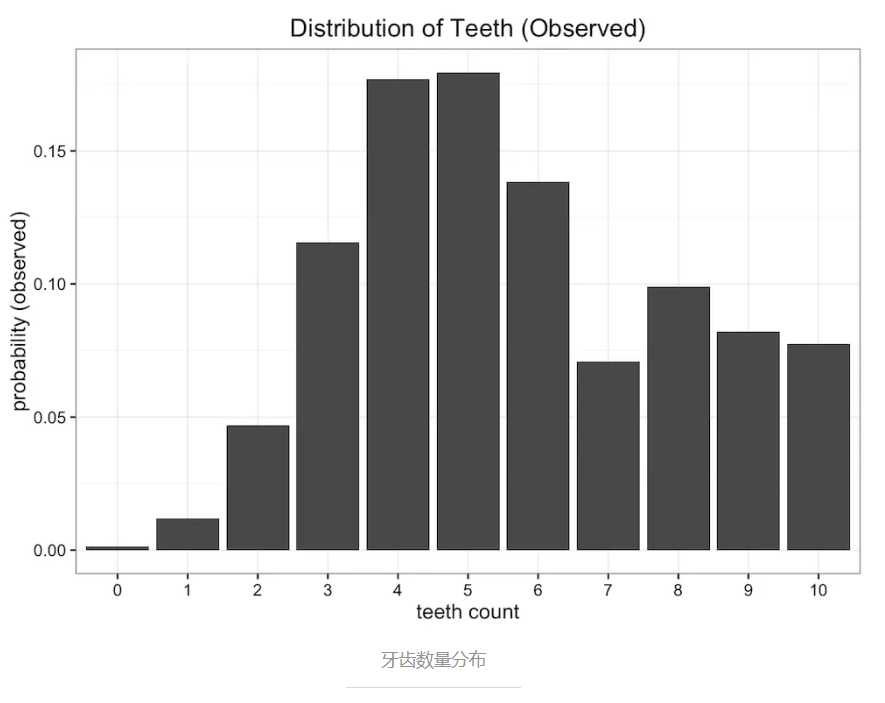
均分布,因为蠕虫牙齿不会超过10颗,所以有11个可能值,那蠕虫的牙齿数量概率都为 1/11。分布图如下: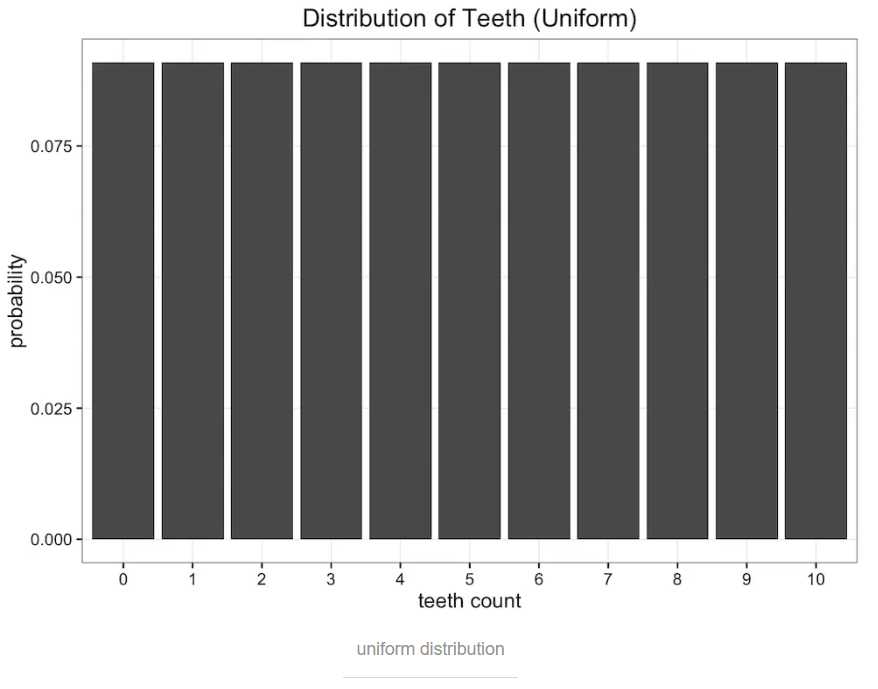
二项式分布binomial distribution。蠕虫嘴里面共有n=10个牙槽,每个牙槽出现牙齿与否为独立事件,且概率均为p。则蠕虫牙齿数量即为期望值E[x]=n*p,真实期望值即为观察数据的平均值,比如说5.7,则p=0.57,得到如下图所示的二项式分布: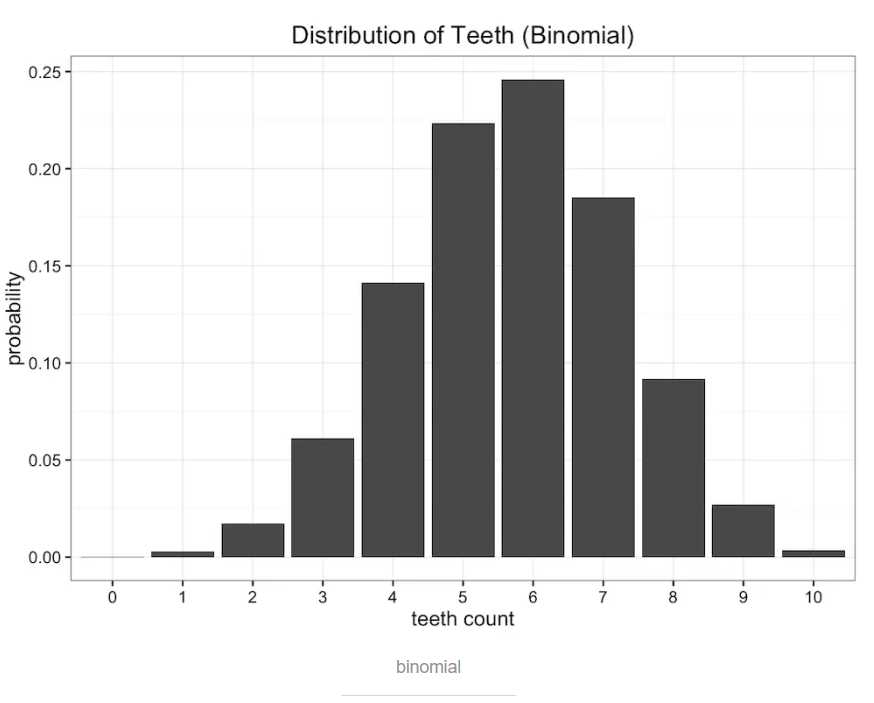
对比一下原始数据,可以看出均分布和二项分布都不能完全描述原始分布。
K-L散度源于信息论。信息论主要研究如何量化数据中的信息。最重要的信息度量单位是熵Entropy,一般用H表示。分布的熵的公式如下:
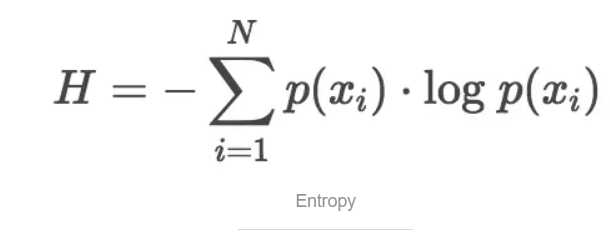
熵H的计算公式就能得到K-L散度的计算公式。设p为观察得到的概率分布,q为另一分布来近似p,则p、q的K-L散度为: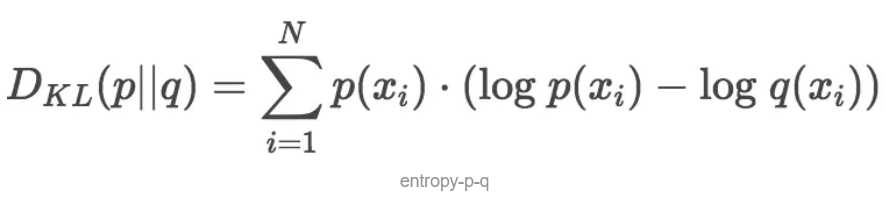
显然,根据上面的公式,K-L散度其实是数据的原始分布p和近似分布q之间的对数差值的期望。如果继续用2为底的对数计算,则K-L散度值表示信息损失的二进制位数。下面公式以期望表达K-L散度:
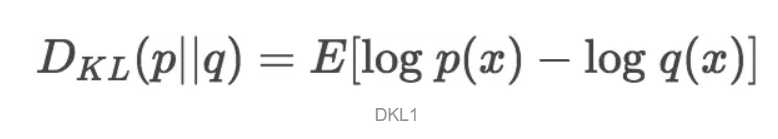
一般,K-L散度以下面的书写方式更常见:
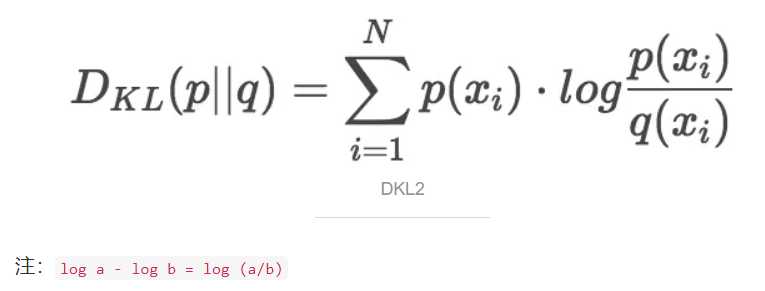
OK,现在我们知道当用一个分布来近似另一个分布时如何计算信息损失量了。接下来,让我们重新回到最开始的蠕虫牙齿数量概率分布的问题。
首先是用均分布来近似原始分布的K-L散度:

接下来计算用二项式分布近似原始分布的K-L散度:

通过上面的计算可以看出,使用均分布近似原始分布的信息损失要比用二项式分布近似小。所以,如果要从均分布和二项式分布中选择一个的话,均分布更好些。
很自然地,一些同学把K-L散度看作是不同分布之间距离的度量。这是不对的,因为从K-L散度的计算公式就可以看出它不符合对称性(距离度量应该满足对称性)。如果用我们上面观察的数据分布来近似二项式分布,得到如下结果:
 所以,
所以,Dkl (Observed || Binomial) != Dkl (Binomial || Observed)。也就是说,用p近似q和用q近似p,二者所损失的信息并不是一样的。前面使用的二项式分布的参数是概率 p=0.57,是原始数据的均值。p的值域在 [0, 1] 之间,我们要选择一个p值,建立二项式分布,目的是最小化近似误差,即K-L散度。那么0.57是最优的吗?
下图是原始数据分布和二项式分布的K-L散度变化随二项式分布参数p变化情况:
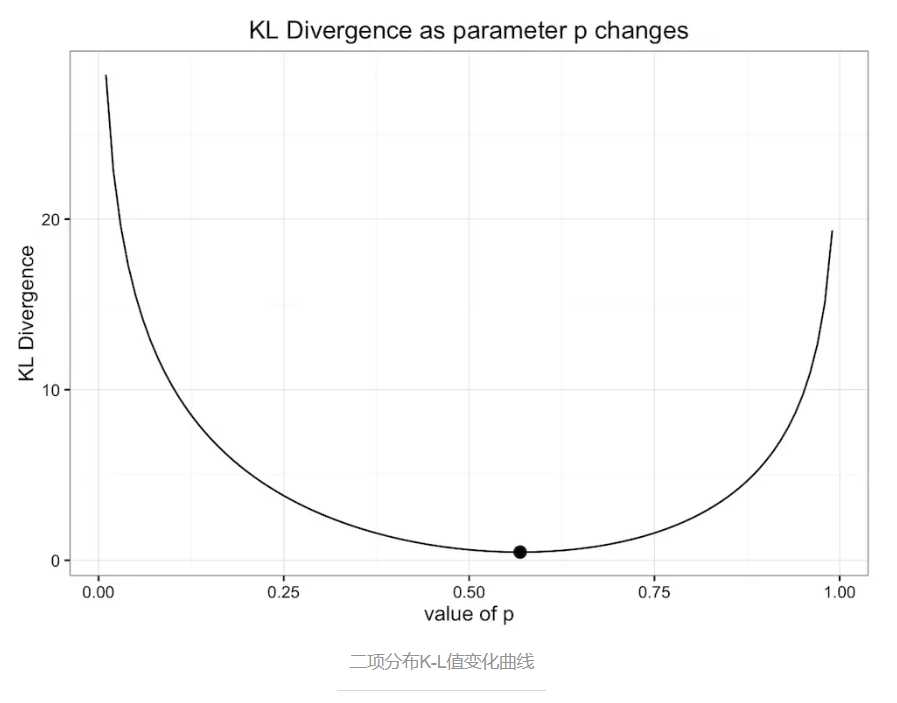
通过上面的曲线图可以看出,K-L散度值在圆点处最小,即p=0.57。所以我们之前的二项式分布模型已经是最优的二项式模型了。注意,我已经说了,是二项式模型,这里只限定在二项式模型范围内。
前面只考虑了均分布模型和二项式分布模型,接下来我们考虑另外一种模型来近似原始数据。首先把原始数据分成两部分,1)0-5颗牙齿的概率和 2)6-10颗牙齿的概率。概率值如下:

即,一只蠕虫的牙齿数量x=i的概率为p/5; x=j的概率为(1-p) / 6,i=0,1,2,3,4,5; j=6,7,8,9,10。
Aha,我们自己建立了一个新的(奇怪的)模型来近似原始的分布,模型只有一个参数p,像前面那样优化二项式分布的时候所做的一样,让我们画出K-L散度值随p变化的情况:
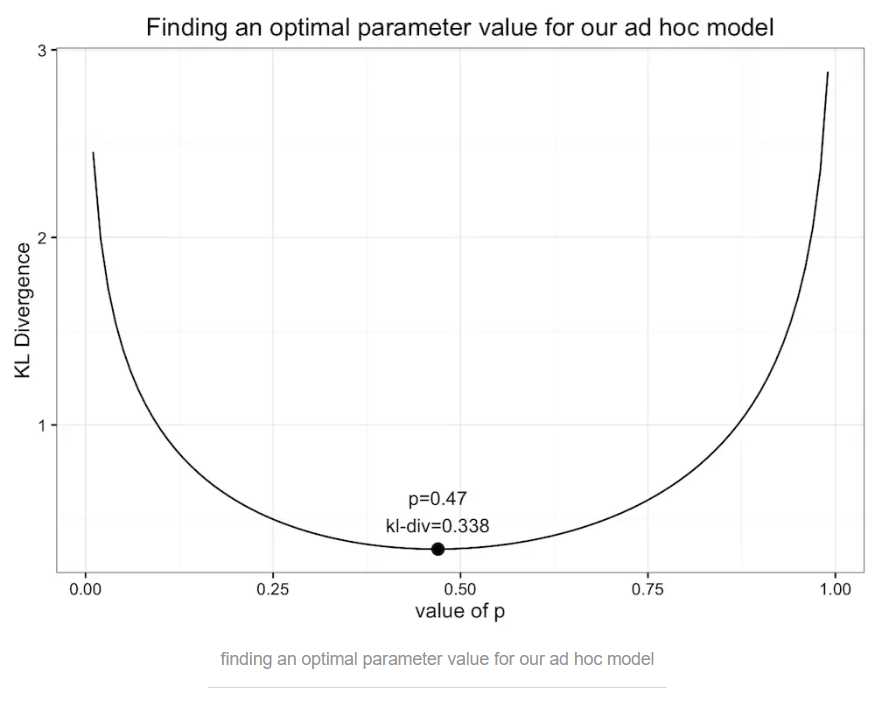
当p=0.47时,K-L值取最小值0.338。似曾相识吗?对,这个值和使用均分布的K-L散度值是一样的(这并不能说明什么)!下面我们继续画出这个奇怪模型的概率分布图,看起来确实和均分布的概率分布图相似:
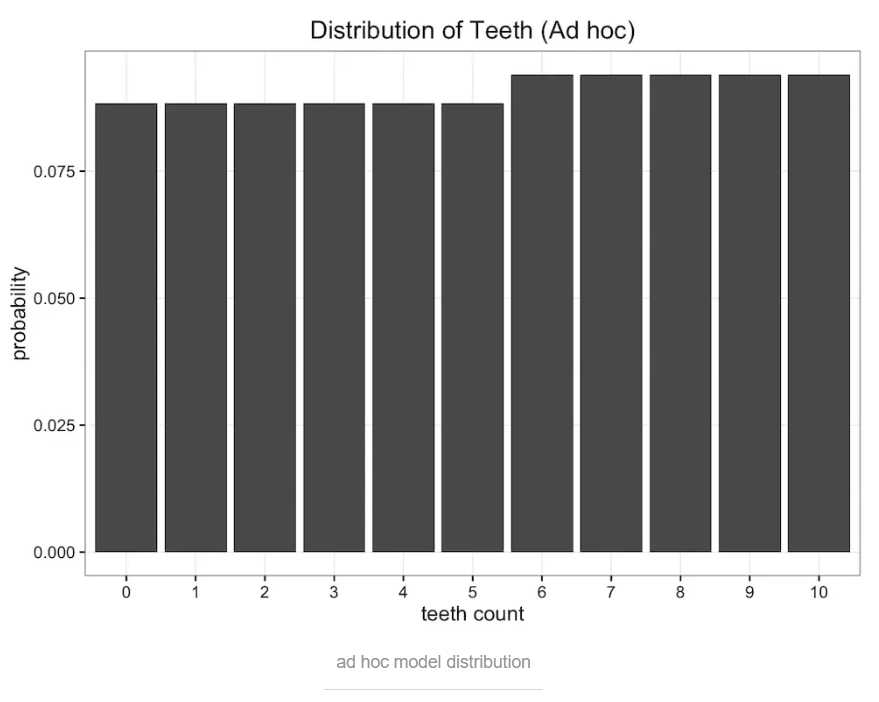
我们自己都说了,这是个奇怪的模型,在K-L值相同的情况下,更倾向于使用更常见的、更简单的均分布模型。
回头看,我们在这一小节中使用K-L散度作为目标方程,分别找到了二项式分布模型的参数p=0.57和上面这个随手建立的模型的参数p=0.47。是的,这就是本节的重点:使用K-L散度作为目标方程来优化模型。当然,本节中的模型都只有一个参数,也可以拓展到有更多参数的高维模型中。
f(x),通过设定目标函数,可以训练神经网络逼近非常复杂的真实函数g(x)。训练的关键是要设定目标函数,反馈给神经网络当前的表现如何。训练过程就是不断减小目标函数值的过程。


K-L散度=交叉熵-熵,即 DKL( p||q )=H(p,q)−H(p)。
在神经网络所涉及到的范围内,H(p)不变,则DKL( p||q )等价H(p,q)。
更多讨论见Why do we use Kullback-Leibler divergence rather than cross entropy in the t-SNE objective function?和Why train with cross-entropy instead of KL divergence in classification?
原文:https://www.cnblogs.com/jiangkejie/p/10741462.html