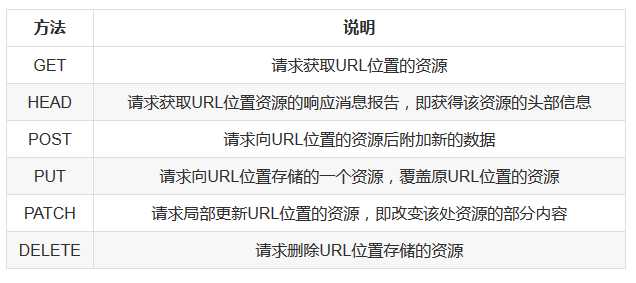
| 方法 | 说明 |
| requests.request() | 构造一个请求,支撑一下各方法的基础方法 |
| requests.get() | 获取HTML网页的主要方法,对应于HTTP的GET |
| requests.head() | 获取HTML网页头信息的方法,对应于HTTP的HEAD |
| requests.post() | 向HTML网页提交POST请求的方法,对应于HTTP的POST |
| requests.put() | 向HTML网页提交PUT请求的方法,对应于HTTP的PUT |
| requests.patch() | 向HTML网页提交局部修改请求,对应于HTTP的PATCH |
| requests.delete() | 向HTML页面提交删除请求,对应于HTTP的DELETE |
request.get()方法
构造一个向服务器请求资源的Request对象
返回一个包含服务器资源的Response对象



| 属性 | 说明 |
| r.status_code | HTTP请求的返回状态,200表示连接成功,404表示失败 |
| r.text | HTTP响应内容的字符串形式,即,url对应的页面内容 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容分析出的响应内容编码方式(备选编码方式) |
| r.content | HTTP响应内容的二进制形式 |
| 属性 | 说明 |
| r.encoding | 从HTTP header中猜测的响应内容编码方式 |
| r.apparent_encoding | 从内容中分析出的响应内容编码方式(备选编码方式) |
r.encoding:如果header中不存在charset,则认为编码为ISO-8859-1
r.apparent_encoding:根据网页内容分析出的编码方式

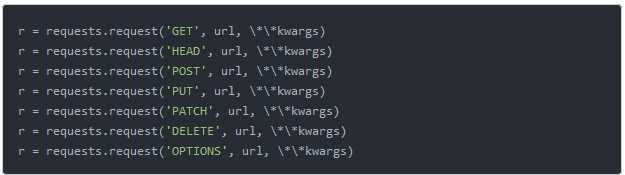
**kwargs:控制访问的参数,均为可选项,共13个
1)params:字典或字节序列,作为参数增加到url中

2)data:字典、字节序列或文件对象,作为Request的对象

3)json:JSON格式的数据,作为Request的内容

4)headers:字典,HTTP定制头

5)cookies:字典或CookieJar,Request中的cookie
6)auth:元组,支持HTTP认证功能
7)files:字典类型,传输文件

8)timeout:设定超时时间,秒为单位

9)proxies:字典类型,设置访问代理服务器,可以增加登录认证

10)allow_redirects:True/False,默认为Ture,重定向开关
11)stream:True/False,默认为True,获取内容立即下载开关
12)verigy:True/False,默认为True,认证SSL证书开关
13)cert:本地SSL证书路径
requests的各方法使用样式
a)requests.get(url, params=None, **kwargs)

b)requests.head(url, **kwargs)

c)requests.post(url, data=None, json=None, **kwargs)

d)requests.put(url, data=None, **kwargs)

e)requests.patch(url, data=None, **kwargs)

f)requests.delete(url, **kwargs)

原文:https://www.cnblogs.com/wxlog/p/10731540.html