Scrapy 是用 Python 实现的一个为了爬取网站数据、提取结构性数据而编写的应用框架。
Scrapy 常应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
Scrapy 是基于twisted框架开发而来,twisted是一个流行的事件驱动的python网络框架。因此Scrapy使用了一种非阻塞(又名异步)的代码来实现并发。
pip install scrapy1. pip install wheel
2. 下载twisted
http://www.lfd.uci.edu/-gohlke/pythonlibs/#twisted
3. 安装twisted
进入到下载目录,pip install Twisted-xxx.whl
4. pip install pywin32
5. pip install scrapy架构图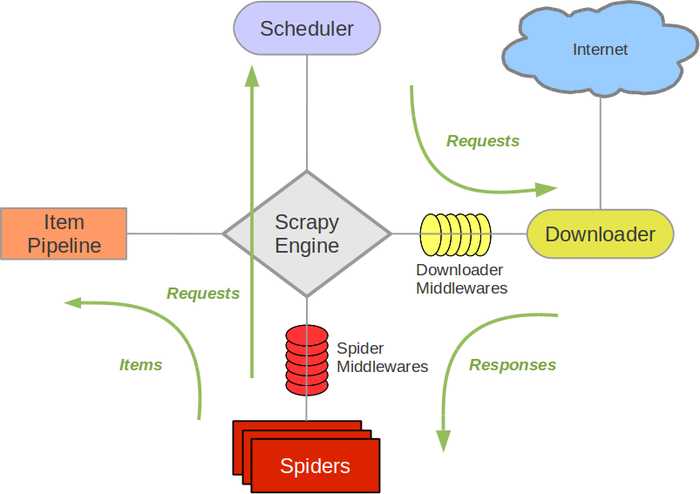
执行流程图
起始url被封装成request请求对象,经引擎传给调度器,存放在队列中且会对重复的请求对象进行过滤,之后经引擎传递给下载器去下载数据得到响应对象,响应对象经引擎返回给spider进行解析并封装到item对象中,用yield将item对象经引擎传给管道进行持久化处理,若spider中解析到新的url,重复上述操作。
当爬取的数据不在同一页面中时,要进行请求传参,不然持久化的数据结果会出错。
def parse(self, response):
...
yield scrapy.Request(url, callback=self.detail, meta={"item": item})
def detail(self, response):
item = response.meta['item']
...ua_list = [
]
ip_list = [
]
# 在下载中间件中
import random
def process_request(self, request, spider):
request.meta['proxy'] = random.choice(ip_list)
request.headers['User-Agent'] = random.choice(ua_list)
...settings.py中开启管道, 并设置优先级
# spider.py
def __init__(self):
self.browser = webdriver.Firefox()
def closed(self,spider):
print("spider closed")
self.browser.close()
# middlewares.py
def process_request(self, request, spider):
if spider.name == 'xxx':
try:
spider.browser.get(request.url)
spider.browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
except TimeoutException as e:
print('超时')
spider.browser.execute_script('window.stop()')
time.sleep(2)
return HtmlResponse(url=spider.browser.current_url, body=spider.browser.page_source,
encoding="utf-8", request=request)原文:https://www.cnblogs.com/tmdhhl/p/10661139.html