图像超分辨重构的原理,输入一张像素点少,像素较低的图像, 输出一张像素点多,像素较高的图像
而在作者的文章中,作者使用downsample_up, 使用imresize(img, []) 将图像的像素从原理的384,384降低到96, 96, 从而构造出高水平的图像和低水平的图像
作者使用了三个部分构成网络,
第一部分是生成网络,用于进行图片的生成,使用了16层的残差网络,最后的输出结果为tf.nn.tanh(),即为-1, 1, 因为图像进行了-1,1的预处理
第二部分是判别网络, 用于进行图片的判别操作,对于判别网络而言,是希望将生成的图片判别为假,将真的图片判别为真
第三部分是VGG19来提取生成图片和真实图片的conv5层卷积层的输出结果,用于生成局部部位的损失值mse
损失值说明:
d_loss:
d_loss_1: tl.cost.sigmoid_cross_entropy(logits_real, tf.ones_like(logits_real)) # 真实图像的判别结果的损失值
d_loss_2: tl.cost.sigmoid_cross_entrpopy(logits_fake, tf.zeros_like(logits_real)) # 生成图像的判别结果的损失值
g_loss:
g_gan_loss: 1e-3 * tl.cost.sigmoid_cross_entropy(logits_fake, tf.ones_like(logits_real)) # 损失值表示为 -log(D(g(lr))) # 即生成的图像被判别为真的损失值
mse_loss: tl.cost.mean_squared_error(net_g.outputs, t_target_image) # 计算真实值与生成值之间的像素差
vgg_loss: tl.cost.mean_squared_error(vgg_predict_emb.outputs, vgg_target_emb.outputs) # 用于计算生成图片和真实图片经过vgg19的卷积层后,特征图之间的差异,用来获得特征细节的差异性
训练说明:
首先进行100次迭代,用来优化生成网络,使用tf.train.AdamOptimer(lr_v, beta1=beta1).minimize(mse_loss, var_list=g_var)
等生成网络迭代好以后,开始迭代生成网络和判别网络,以及VGG19的损失值缩小
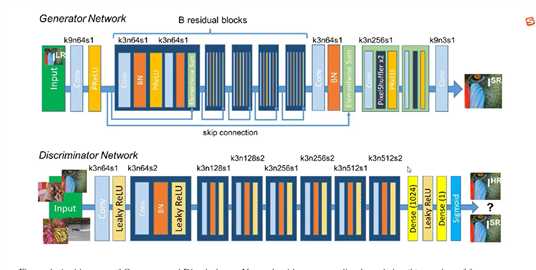
生成网络:使用了16个残差模块,在残差模块的输入与下一层的输出之间又进行一次残差直连
判别网络:使用的是feature_map递增的卷积层构造成的判别网路
代码说明:
第一步:将参数从config中导入到main.py
第二步:使用tl.file.exists_or_mkdir() 构造用于储存图片的文件夹,同时定义checkpoint的文件夹
第三步:使用sorted(tl.files.load_file_list) 生成图片的列表, 使用tl.vis.read_images() 进行图片的读入
第四步:构建模型的构架Model
第一步:定义输入参数t_image = tf.placeholder(‘float32‘, [batch_size, 96, 96, 3]), t_target_image = tf.placeholder(‘float32‘, [batch_size, 384, 384, 3])
第二步: 使用SGRAN_g 用来生成最终的生成网络,net_g, 输入参数为t_image, is_training, reuse
第三步: 使用SGRAN_d 用来生成判别网络,输出结果为net_d网络架构,logits_real, 输入参数为t_target_image, is_training, reuse, 同理输入t_image, 获得logits_fake
第四步: 使用net_g.print_params(False) 和 net_g.print_layers() 不打印参数,打印每一层
第五步:将net_g.outputs即生成的结果和t_target_image即目标图像的结果输入到Vgg_19_simple_api, 获得vgg_net, 以及conv第五层的输出结果
第一步:tf.image.resize_images()进行图片的维度变换,为了可以使得其能输入到VGG_19中
第二步:将变化了维度的t_target_image 输入到Vgg_19_simple_api, 获得net_vgg, 和 vgg_target_emb即第五层卷积的输出结果
第三步:将变化了维度的net_g.outputs 输入到Vgg_19_simple_api, 获得 vgg_pred_emb即第五层卷积的输出结果
第六步: 构造net_g_test = SGRAN_g(t_image, False, True) 用于进行训练中的测试图片
第五步:构造模型loss,还有trian_ops操作
第一步: loss的构造
第一步: d_loss的构造, d_loss_1 + d_loss_2
第一步: d_loss_1: 构造真实图片的判别损失值,即tl.cost.softmax_cross_entropy(logits_real, tf.ones_like(logits_real))
第二步: d_loss_2: 构造生成图片的判别损失值, 即tl.cost.softmax_cross_entropy(logits_fake, tf.ones_like(logits_fake))
第二步: g_loss的构造,g_gan_loss, mse_loss, vgg_loss
第一步: g_gan_loss, 生成网络被判别网络判别为真的概率,使用tl.cost.softmax_cross_entropy(logits_fake, tf.ones_like(logits_fake))
第二步:生成图像与目标图像之间的像素点差值,使用tl.cost.mean_squared_error()
原文:https://www.cnblogs.com/my-love-is-python/p/10660602.html