数据集:mnist
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist=input_data.read_data_sets(‘MNIST_data‘,one_hot=True)
def weight_variable(shape):
initial=tf.truncated_normal(shape,stddev=0.1) #tf.truncted_normal产生随机变量来进行初始化,类似normal
return tf.Variable(initial)
def bias_variable(shape):
initial=tf.constant(0.1,shape=shape)
return tf.Variable(initial)
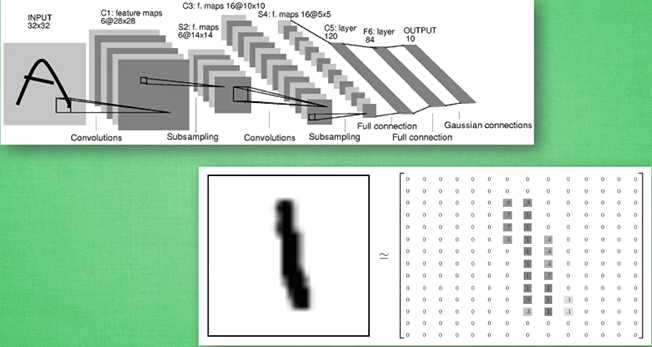
定义卷积,tf.nn.conv2d函数是tensoflow里面的二维的卷积函数,x是图片的所有参数,W是此卷积层的权重,然后定义步长strides=[1,1,1,1]值,strides[0]和strides[3]的两个1是默认值,中间两个1代表padding时在x方向运动一步,y方向运动一步,padding采用的方式是SAME。
def conv2d(x,W):
return tf.nn.conv2d(x,W,strides=[1,1,1,1],padding=‘SAME‘)
接着定义池化pooling,为了得到更多的图片信息,padding时我们选的是一次一步,也就是strides[1]=strides[2]=1,这样得到的图片尺寸没有变化,而我们希望压缩一下图片也就是参数能少一些从而减小系统的复杂度,因此我们采用pooling来稀疏化参数,也就是卷积神经网络中所谓的下采样层。pooling 有两种,一种是最大值池化,一种是平均值池化,本例采用的是最大值池化tf.max_pool()。池化的核函数大小为2x2,因此ksize=[1,2,2,1],步长为2,因此strides=[1,2,2,1]
def max_pool_2x2(x):
return tf.nn.max_pool(x,ksize=[1,2,2,1],strides=[1,2,2,1],padding=‘SAME‘)
def compute_accuracy(v_xs, v_ys):
global prediction
y_pre = sess.run(prediction, feed_dict={xs: v_xs, keep_prob: 1})
correct_prediction = tf.equal(tf.argmax(y_pre,1), tf.argmax(v_ys,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
result = sess.run(accuracy, feed_dict={xs: v_xs, ys: v_ys, keep_prob: 1})
return result
xs=tf.placeholder(tf.float32,[None,784]) ys=tf.placeholder(tf.float32,[None,10]) keep_prob=tf.placeholder(tf.float32) x_image=tf.reshape(xs,[-1,28,28,1])#-1表示暂时不管,自动计算 [n_samples,28,28,-1]
# 建立卷积层conv1,conv2 W_conv1=weight_variable([5,5,1,32])#patch/kernel 5*5,in size 1是image的厚度,out size 32 b_conv1=bias_variable([32]) #一个kernel一个bias h_conv1=tf.nn.relu(conv2d(x_image,W_conv1)+b_conv1)#output size 28*28*32 h_pool1=max_pool_2x2(h_conv1) #output size 14*14*32 W_conv2=weight_variable([5,5,32,64])#kernel 5*5,in size 32,out size 64 b_conv2=bias_variable([64])#output size 14*14*64 h_conv2=tf.nn.relu(conv2d(h_pool1,W_conv2)+b_conv2)#output size 7*7*64 h_pool2=max_pool_2x2(h_conv2)
#建立全连接层fc1,fc2 #[n_samples,7,7,64]->>[n_samples,7*7*64] h_pool2_flat=tf.reshape(h_pool2,[-1,7*7*64]) W_fc1=weight_variable([7*7*64,1024]) b_fc1=bias_variable([1024]) h_fc1=tf.nn.relu(tf.matmul(h_pool2_flat,W_fc1)+b_fc1) h_fc1_drop=tf.nn.dropout(h_fc1,keep_prob) W_fc2=weight_variable([1024,10]) b_fc2=bias_variable([10]) prediction=tf.nn.softmax(tf.matmul(h_fc1_drop,W_fc2)+b_fc2)
cross_entropy=tf.reduce_mean(-tf.reduce_sum(ys*tf.log(prediction),reduction_indices=[1]))
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
sess=tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(1000):
batch_xs,batch_ys = mnist.train.next_batch(100)
sess.run(train_step,feed_dict={xs:batch_xs,ys:batch_ys,keep_prob:1.0})
if i % 50 == 0:
print(compute_accuracy(mnist.test.images[:2000],mnist.test.labels[:2000]))
tensorflow目前只能保存variable,不能保存网络框架
import tensorflow as tf import numpy as np ## Save to file # remember to define the same dtype and shape when restore W = tf.Variable([[1,2,3],[3,4,5]], dtype=tf.float32, name=‘weights‘) b = tf.Variable([[1,2,3]], dtype=tf.float32, name=‘biases‘) # init= tf.initialize_all_variables() # tf 马上就要废弃这种写法 # 替换成下面的写法: init = tf.global_variables_initializer()
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
save_path = saver.save(sess, "nxf_net/save_net.ckpt")
print("Save to path: ", save_path)
"""
Save to path: nxf_net/save_net.ckpt
"""
# restore variables
# reduce the same shape and same type for your variables
# 先建立W,b的容器
W = tf.Variable(np.arange(6).reshape((2, 3)), dtype=tf.float32, name="weights")
b = tf.Variable(np.arange(3).reshape((1, 3)), dtype=tf.float32, name="biases")
# 这里不需要初始化步骤 init= tf.initialize_all_variables()
saver = tf.train.Saver()
with tf.Session() as sess:
# 提取变量
saver.restore(sess, "my_net/save_net.ckpt")
print("weights:", sess.run(W))
print("biases:", sess.run(b))
"""
weights: [[ 1. 2. 3.]
[ 3. 4. 5.]]
biases: [[ 1. 2. 3.]]
"""
参考文献:
【1】莫烦python
原文:https://www.cnblogs.com/nxf-rabbit75/p/10633846.html