人脸识别从去年的火热也开始逐渐变得不温不火了,在这期间也关注了不少论文和大佬们,对相关的技术发展也有了一些皮毛上的了解,在这里记录一下。
主流的 CNN 网络主要有 VGG, GoogleLeNet, ResNet, ResNeXt, DenseNet 等,已经开源的人脸识别模型, 如 InsightFace 用的就是ResNet,其他的网络在人脸识别中的应用还比较少见。这里就主要介绍一下ResNet, 该模型结构是何凯明大神的团队提出的,用于解决深度学习模型的深度加深而导致的“退化”问题。由于网络深度增加后,梯度消失或者爆炸的问题就会接踵而来,这是因为对于深层网络来说,优化变得更加困难,因此模型达不到很优的收敛效果。
针对这个问题,作者提出了一个残差(Residual)的结构,如下:
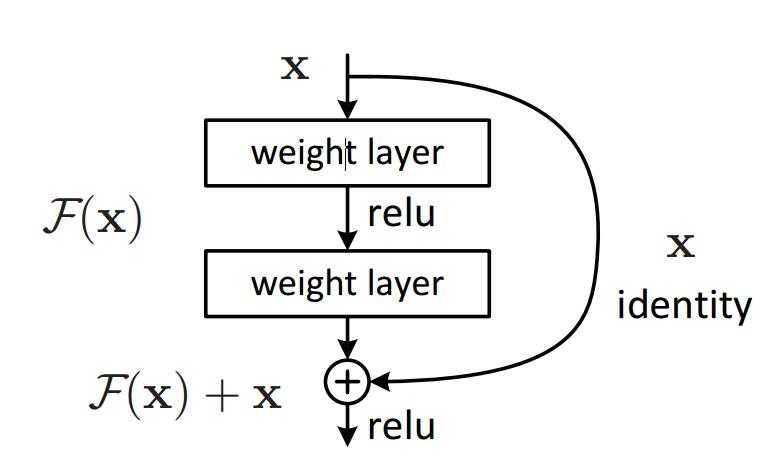
对于一个简单的 block , 当输入为 x 时其学习到的特征记为 H(x) ,作者通过增加了一个恒等映射(identity mapping),将所需要学习的 H(x) 转换成学习残差 F(x)=H(x)-x 。这一想法源于图像处理中的残差向量编码,通过一个reformulation,将一个问题分解成多个尺度直接的残差问题,能够很好的起到优化训练的效果。
以下是收集的有关 CNN 网络的论文和博客等资料。
人脸识别中所用的 LOSS 真的是百花齐放,从最基础的 SoftMax 到加入各种 trick 的 ArcFace, 从欧氏距离到余弦距离,从无 Margin 到加入 Margin。整理了一下,大概有如下这么多:
L2-softmax: L2-constrained Softmax Loss for Discriminative Face Verification
原始的 softmax 未优化提取的人脸特征,而 L2-softmax 将人脸 id 限定在一个超球面上,添加了一个 L2 约束,使得类内的距离减小。实验结果:在 LFW 上的准确率达到 99.78%, YTF 上的准确率为 96.08%。
Contrastive Loss: Dimensionality Reduction by Learning an Invariant Mapping
主要是用在降维中,即本来相似的样本,在经过降维(特征提取)后,在特征空间中,两个样本仍旧相似;而原本不相似的样本,在经过降维后,在特征空间中,两个样本仍旧不相似。在人脸识别中,DeepID 运用了该 loss,结合 Softmax + Contrastive Loss 在 LFW 上的准确率为 99.53%。更多关于 DeepID 的介绍可以参考 Deep learning face representation from predicting 10,000 classes。
Triplet Loss: FaceNet: A Unified Embedding for Face Recognition and Clustering
该 Loss 主要用于优化人脸识别模型,对于输入到模型中的若干个人脸图像,提取其特征并计算相互之间的欧氏距离,选择特定的三元组(a, p, n), 优化类内和类间的距离。FaceNet 仅仅使用 128 维的特征,就在 LFW 上达到了 99.63% 。Triplet Loss 针对于人脸认证的场景可以有较好的提升,强力推荐一波。
Center Loss: A Discriminative Feature Learning Approach for Deep Face Recognition
Center Loss 为每个类别都学习一个分类中心,并将每个类别的所有人脸特征都聚集到其对应的类别中心,即使得类内更加紧凑。作者仅使用 0.7 M 的训练样本,7 层的 CNN 在 LFW 上达到了 99.28% 的精度。
NormFace: L2 Hypersphere Embedding for Face Verification
NormFace 从人脸特征的归一化来考虑人脸的分类问题,它对 softmax 改进的为添加了2个限制,分别为特征和权重矩阵参数 W 的归一化。因为对于普通的 softmax loss 而言,loss 的大小与特征的模长相关,若一个样本分对了,softmax 继续优化的时候会朝着特征的模增长的方向,但对于整体的分类性能来说并没有很大的意义。且在实际的人脸识别应用中,使用的一般是 cosine 或者欧氏距离,也会导致优化的方向与最终的应用不一致。因此 NormFace 为了限制 softmax 的优化方向,对特征和 W 进行归一化,让 loss 更关注类中心的夹角。
Coco Loss: Rethinking Feature Discrimination and Polymerization for Large-scale Recognition
Coco Loss 与 NormFace 的思路是一样的,都是为了解决同一个问题,这里就不再说明了。
L-softmax: Large Margin Loss: Large-Margin Softmax Loss for Convolutional Neural Networks
前面介绍的 loss 都是为了拉大分类中心之间的距离,而接下来的 loss 还考虑了人脸识别中另外一个非常重要的问题,就是类之间的距离。NormFace 在优化的时候,若分类正确,就不会再继续压缩类内的间距,对于数量庞大的人脸识别来说,让每个类别的特征都尽可能的靠近,是最优的情况。于是就产生了 Margin 这个超参数。
第一个比较重要的工作是 L-softmax(Large-Margin Softmax),它的意思是我在做分类时,希望不同的类之间能够区分得更开,把同一个类压缩得更紧,但它跟之前的思路有一定的相似性,但并没有通过额外的限制来做,它深入分析了 softmax loss 的形式,直接对这个形式做了精细的改动,把其中的cosθ改成了cosmθ,起到了增加 margin 的效果。
Asoftmax loss: SphereFace: Deep Hypersphere Embedding for Face Recognition
Asoftmax 是在 L-softmax 的基础上进行了微小的改进,增添了两个限制条件:一是 W 的 norm 必须是一个固定的值,例如 1,二是偏置项直接设为0。但是该方法的预测仅取决于 W 和 特征之间的角度,比较难优化。
AAM: Face Recognition via Centralized Coordinate Learning
AAM Softmax 提出了自适应参数 η ,针对不同的角度差异设置不同的值,对于大角度差异系数值设定较小,而小角度差异系数需要足够大才能保证 margin 的宽度。但单独使用 AAM softmax 不稳定,需要和 Asoftmax 一起使用。
AMSoftmax: Additive Margin Softmax for Face Verification
AMSoftmax 减小cosθ 的方式是让它减去一个值 m ,同时也要求 W 的 norm 必须是固定的,特征的 norm 也是固定的。
ArcFace: Additive Angular Margin Loss for Deep Face Recognition
ArcFace 则是通过增大 θ 角度的方式来让 cosθ 的值降低。
原文:https://www.cnblogs.com/danpe/p/10598035.html