1.1 Hadoop环境配置
本文用于指导hadoop在windows10环境下单机版的使用,软件版本选择:
l Windows10家庭版
l JDK 1.8.0_171-b11
l hadoop-2.7.3
1.1.1 Hadoop简要介绍
Hadoop 是Apache基金会下一个开源的分布式计算平台,它以分布式文件系统HDFS和MapReduce算法为核心,为用户提供了系统底层细节透明的分布式基础架构。
从官网下载Hadoop二进制版本,然后解压到:D:\Study\codeproject\hadoop-2.7.3。
Java是Hadoop依赖的运行环境,读者可以在Oracle官网获取最新版的Java版本,由于只是运行不是开发,所以也可以只下载JRE。安装完成后配置安装完成后,配置JAVA_HOME和JRE_HOME环境变量。执行如下命令表示JDK安装成功:
C:\Users\45014>java -version
java version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.171-b11, mixed mode)
右键单击我的电脑 –>属性 –>高级环境变量配置 –>高级选项卡 –>环境变量 –> 单击新建HADOOP_HOME,接着编辑环境变量path,将hadoop的bin目录加入到后面
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的core-site.xml文件:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/data/temp</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/data/name</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的mapred-site.xml文件:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>hdfs://localhost:9001</value>
</property>
</configuration>
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的hdfs-site.xml文件:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value> <!-- 这个参数设置为1,因为是单机版hadoop -->
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/data/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/datanode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/D:/Study/codeproject/hadoop-2.7.3/datanode</value>
</property>
</configuration>
l 编辑“D:\Study\codeproject\hadoop-2.7.3\etc\hadoop”下的yarn-site.xml文件:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(1)进入D:\Study\codeproject\hadoop-2.7.3\bin目录,格式化hdfs,在cmd中运行命令 hdfs namenode -format
(2)运行cmd窗口,切换到hadoop的sbin目录,执行“start-all.cmd”,它将会启动以下进程。
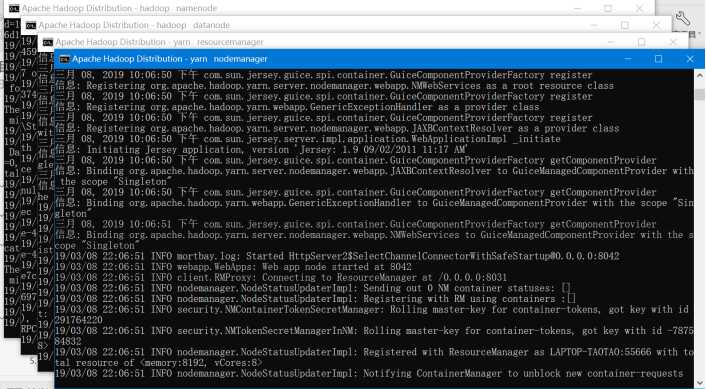
启动成功后,进入资源管理GUI:http://localhost:8088/
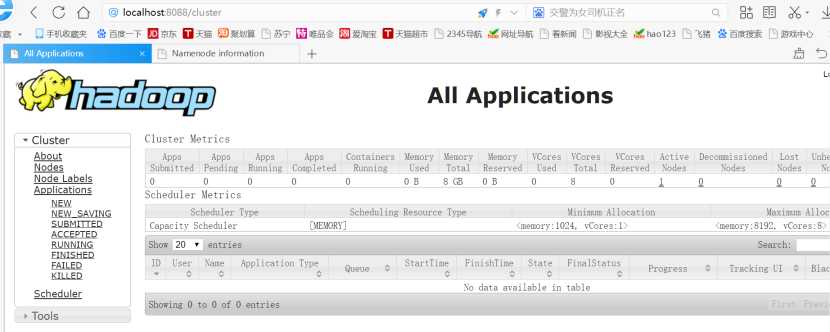
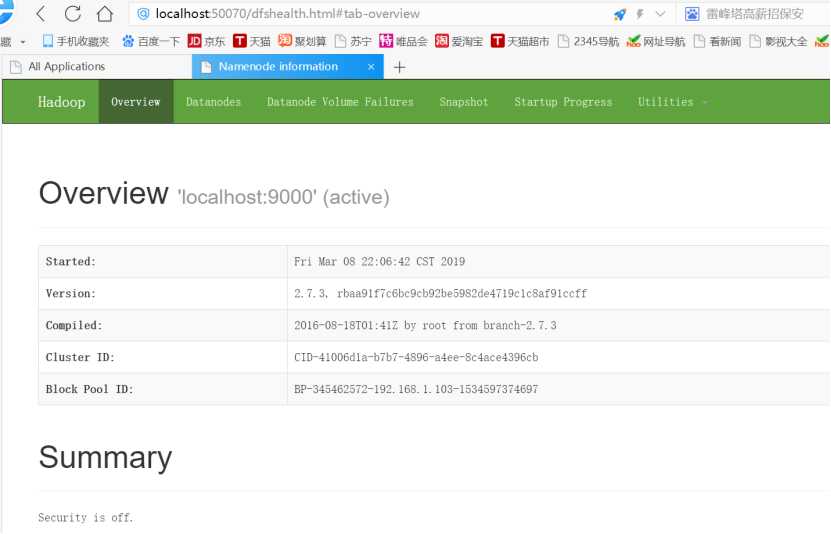
节点管理GUI:http://localhost:50070/;
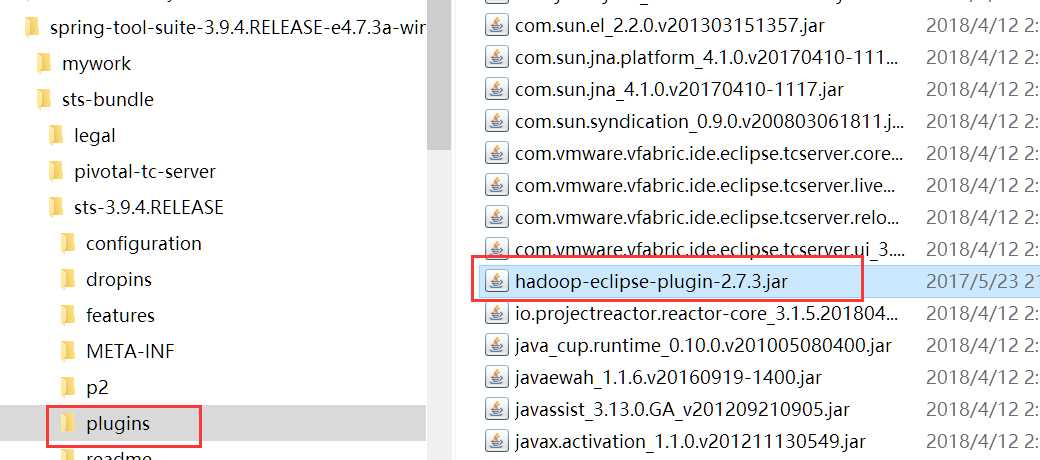
1.在eclipse上安装Hadoop插件
把下载好的hadoop-eclipse-plugin-2.7.1.jar文件拷贝到eclipse安装目录中的plugins文件夹内(注意版本选择,否则可能导致不可用)。如下图:
2.继续配置hadoop编译环境(方便配置,确保已经启动了 Hadoop)
启动 Eclipse 后就可以在左侧的Project Explorer中看到DFS Locations。
3.插件的配置
第一步:选择 Window 菜单下的 Preference。
此时会弹出一个窗体,点击选择 Hadoop Map/Reduce 选项,选择 Hadoop 的安装目录(例如:/home/hadoop/hadoop)。
第二步:切换 Map/Reduce 开发视图
选择Window 菜单下选择 Open Perspective -> Other,弹出一个窗体,从中选择Map/Reduce 选项即可进行切换。
第三步:建立与 Hadoop 集群的连接
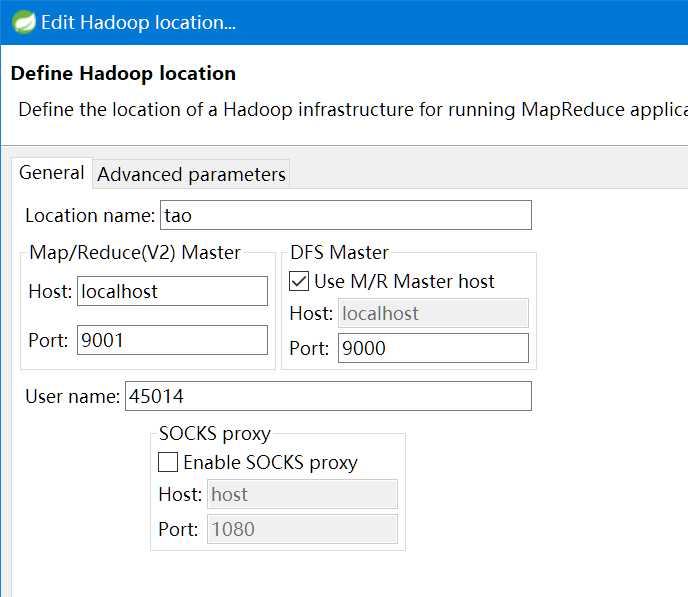
点击Eclipse软件右下角的Map/Reduce Locations 面板,在面板中单击右键,选择New Hadoop Location。
在弹出来的General选项面板中,General的设置要与 Hadoop 的配置一致。一般两个 Host值是一样的,如果是伪分布式,填写 localhost 即可,这里使用的是Hadoop伪分布,设置fs.defaultFS为 hdfs://localhost:9000,则 DFS Master 的 Port 改为 9000。Map/Reduce(V2) Master 的 Port 用默认的即可,Location Name 随意填写。
HDFS是Hadoop体系中数据存储管理的基础。 HDFS采用主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。NameNode作为主服务器,管理文件系统命名空间和客户端对文件的访问操作。DataNode管理存储的数据。
1.运行cmd窗口,执行“hdfs namenode -format”;
根据你core-site.xml的配置,接下来你就可以通过:hdfs://localhost:9000来对hdfs进行操作了。
1.创建输入目录
C:\Users\45014>hadoop fs -mkdir hdfs://localhost:9000/user/
C:\Users\45014>hadoop fs -mkdir hdfs://localhost:9000/user/wcinput
2.上传数据到目录
C:\Users\45014>hadoop fs -put D:\file1.txt hdfs://localhost:9000/user/wcinput
C:\Users\45014>hadoop fs -put D:\file2.txt hdfs://localhost:9000/user/wcinput
3.查看文件
C:\Users\45014>hadoop fs -ls hdfs://localhost:9000/user/wcinput
Found 2 items
-rw-r--r-- 1 45014 supergroup 52 2019-03-08 22:48 hdfs://localhost:9000/user/wcinput/file1.txt
-rw-r--r-- 1 45014 supergroup 13 2019-03-08 22:48 hdfs://localhost:9000/user/wcinput/file2.txt
在esclipse界面的DFS Locations右键点击refresh,如下图:

MapReduce是Google的一项重要技术,它是一个编程模型,用以进行大数据量的计算。对于大数据量的计算,通常采用的处理手法就是并行计算。至少现阶段而言,对许多开发人员来说,并行计算还是一个比较遥远的东西。MapReduce就是一种简化并行计算的编程模型,它让那些没有多少并行计算经验的开发人员也可以开发并行应用。
1、修改HBase下的conf/hbase-env.cmd
配置JDK:
set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_121
set HBASE_MANAGES_ZK=true
2、修改HBase下的hbase-site.xml
3、配置用户变量HADOOP_HOME
新建环境变量HADOOP_HOME,值为D:\hadoop\hadoop-common-2.2.0-bin-master
在path后添加:%HADOOP_HOME%\bin
==================================
1、启动HBase
在D:\hadoop\hbase-1.2.6\bin下打开命令行,输入start-hbase.cmd,启动HBase。
2、测试Shell
HBase启动后,在命令行输入hbase shell,打卡HBase的shell命令行。
3、打开HBase主页,网址:http://127.0.0.1:16010/master-status

以上就配置完了,用 Hbase Shell试一下是否能操作数据库
:> cd D:\HBase\hbase-1.2.3\bin
:>hbase shell
1,创建表hbase_1102有两个列族CF1和CF2
此表有两个列族,CF1和CF2,其中CF1和CF2下分别有两个列name和gender,Chinese和Math
hbase(main):041:0> create ‘hbase_1102‘, {NAME=>‘cf1‘}, {NAME=>‘cf2‘}
2,向表中添加数据,在想HBase的表中添加数据的时候,只能一列一列的添加,不能同时添加多列。
hbase(main):042:0> put‘hbase_1102‘, ‘001‘,‘cf1:name‘,‘Tom‘
hbase(main):043:0> put‘hbase_1102‘, ‘001‘,‘cf1:gender‘,‘man‘
hbase(main):044:0> put‘hbase_1102‘, ‘001‘,‘cf2:chinese‘,‘90‘
hbase(main):045:0> put‘hbase_1102‘, ‘001‘,‘cf2:math‘,‘91‘
这样表结构就起来了,其实比较自由,列族里边可以自由添加子列很方便。如果列族下没有子列,加不加冒号都是可以的。
如果在添加数据的时候,需要手动的设置时间戳,则在put命令的最后加上相应的时间戳,时间戳是long类型的,所以不需要加引号
hbase(main):045:0> put‘hbase_1102‘, ‘001‘,‘cf2:math‘,‘91‘,1478053832459
3,查看表中的所有数据
hbase(main):046:0> scan ‘hbase_1102‘
ROW COLUMN+CELL
001 column=cf1:gender, timestamp=1478053832459, value=man
001 column=cf1:name, timestamp=1478053787178, value=Tom
001 column=cf2:chinese, timestamp=1478053848225, value=90001 column=cf2:math, timestamp=1478053858144, value=911 row(s) in0.0140seconds
4,查看其中某一个Key的数据
hbase(main):048:0> get‘hbase_1102‘,‘001‘
COLUMN CELL
cf1:gender timestamp=1478053832459, value=man
cf1:name timestamp=1478053787178, value=Tom
cf2:chinese timestamp=1478053848225, value=90
cf2:math timestamp=1478053858144, value=914 row(s) in0.0290seconds
private HBaseAdmin admin = null;
// 定义配置对象HBaseConfiguration
private HBaseConfiguration cfg = null;
public HbaseTest() throws Exception
{
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set("hbase.zookeeper.quorum", "192.168.1.103");
HBASE_CONFIG.set("hbase.zookeeper.property.clientPort", "2181");
cfg = new HBaseConfiguration(HBASE_CONFIG);
admin = new HBaseAdmin(cfg);
}
windows 10环境下搭建基于Hadoop的Eclipse开发环境
原文:https://www.cnblogs.com/taoweizhong/p/10502261.html