Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Series是一种类似与一维数组的对象,由下面两个部分组成:
from pandas import Series,DataFrame import numpy as np
两种创建方式:
(1) 由列表或numpy数组创建
默认索引为0到N-1的整数型索引 #使用列表创建Series(列表也可以换为numpy的array) Series([1,2,3,4,5],index=[‘a‘,‘b‘,‘c‘,‘d‘,‘e‘],name=‘Hello‘) # a 1 b 2 c 3 d 4 e 5 Name: Hello, dtype: int64
(2) 由字典创建:不能在使用index.但是依然存在默认索引
dict = {
‘hello‘:12,
‘hey‘:30
}
Series(data=dict)
#
hello 12
hey 30
dtype: int64
可以使用中括号取单个索引(此时返回的是元素类型),或者中括号里一个列表取多个索引(此时返回的是一个Series类型)。
(1) 显式索引:
- 使用index中的元素作为索引值
- 使用s.loc[](推荐):注意,loc中括号中放置的一定是显示索引
注意,此时是闭区间
s1 = Series(data=[1,2,3],index=[‘a‘,‘b‘,‘c‘]) s1 # a 1 b 2 c 3 dtype: int64 s1.loc["a"] # 1
(2) 隐式索引:
- 使用整数作为索引值
- 使用.iloc[](推荐):iloc中的中括号中必须放置隐式索引
注意,此时是半开区间
s1.loc["a":"c"] # a 1 b 2 c 3 dtype: int64
可以把Series看成一个定长的有序字典
向Series增加一行:相当于给字典增加一组键值对
s1[‘a‘] = 10 s1 # a 10 b 2 c 3 dtype: int64 s1[‘d‘]=20 s1 # a 10 b 2 c 3 d 20 dtype: int64
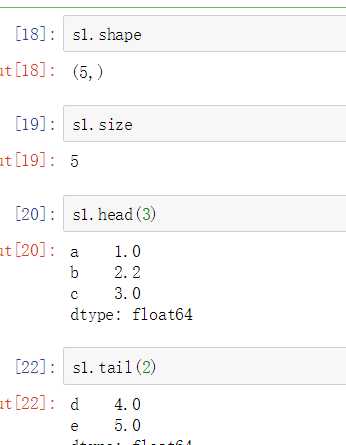
s1 = Series([1, 2, 3, 4], index=[‘a‘, ‘b‘, ‘c‘, ‘d‘]) s1 # a 1 b 2 c 3 d 4 dtype: int64 s1.values # array([1, 2, 3, 4], dtype=int64) s1.index # Index([‘a‘, ‘b‘, ‘c‘, ‘d‘], dtype=‘object‘)
可以使用pd.isnull(),pd.notnull(),或s.isnull(),notnull()函数检测缺失数据
s1 = Series(data=[1,2,3,4,5],index=[‘a‘,‘b‘,‘c‘,‘d‘,‘e‘]) s2 = Series(data=[1,2,3,4,5],index=[‘a‘,‘g‘,‘c‘,‘e‘,‘f‘]) s3 = s1 + s2 s3 # a 2.0 b NaN c 6.0 d NaN e 9.0 f NaN g NaN dtype: float64 s3.isnull() # a False b True c False d True e False f True g True dtype: bool s3[~s3.isnull()] # 利用布尔索引 获取不是NaN的数据 # a 2.0 c 6.0 e 9.0 dtype: float64 s3.notnull() # a True b False c True d False e True f False g False dtype: bool s3[s3.notnull()] # a 2.0 c 6.0 e 9.0 dtype: float64
(1) + - * /
(2) add() sub() mul() div() : s1.add(s2,fill_value=0)
(3) Series之间的运算
sr3 =sr1+sr2 sr3 # a 33.0 b NaN c 32.0 d 45.0 dtype: float64 sr3.dropna() # 获取所有不是NaN的数 # a 33.0 c 32.0 d 45.0 dtype: float64 sr3.fillna(0) # 使用相近的数 自动填充NaN # a 33.0 b 0.0 c 32.0 d 45.0 dtype: float64
DataFrame是一个【表格型】的数据结构。DataFrame由按一定顺序排列的多列数据组成。设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
最常用的方法是传递一个字典来创建。DataFrame以字典的键作为每一【列】的名称,以字典的值(一个数组)作为每一列。
此外,DataFrame会自动加上每一行的索引。
使用字典创建的DataFrame后,则columns参数将不可被使用。
同Series一样,若传入的列与字典的键不匹配,则相应的值为NaN。
dict = {
"java":[90,22,66],
‘python‘:[12,33,66]
}
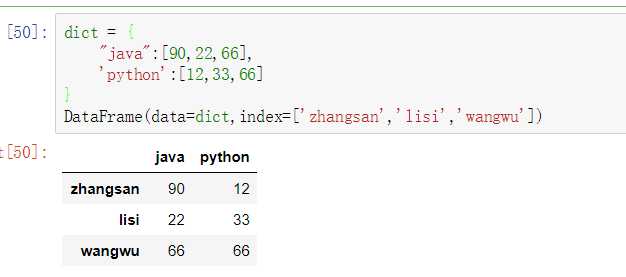
DataFrame(data=dict,index=[‘zhangsan‘,‘lisi‘,‘wangwu‘])
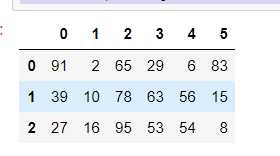
DataFrame(data=np.random.randint(0,100,size=(3,6)))
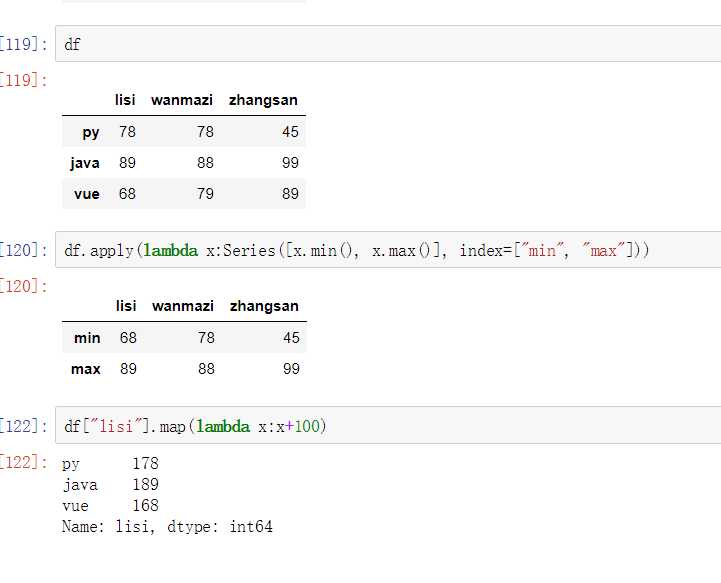
DataFrame属性:values、columns、index、shape
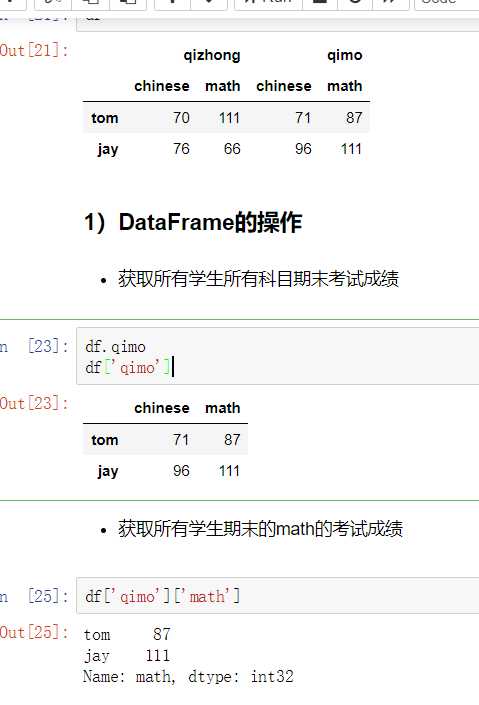
(1) 对列进行索引
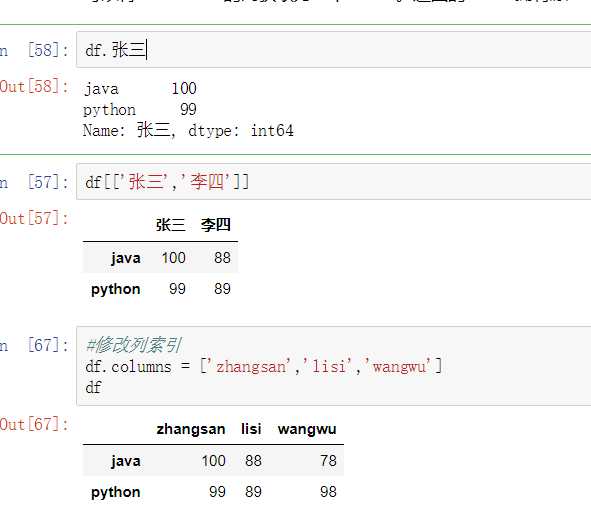
- 通过类似字典的方式 df[‘q‘]
- 通过属性的方式 df.q
可以将DataFrame的列获取为一个Series。返回的Series拥有原DataFrame相同的索引,且name属性也已经设置好了,就是相应的列名。
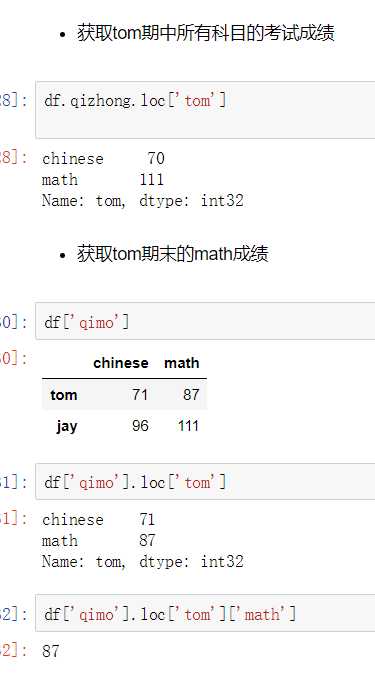
(2) 对行进行索引
- 使用.loc[]加index来进行行索引
- 使用.iloc[]加整数来进行行索引
同样返回一个Series,index为原来的columns。
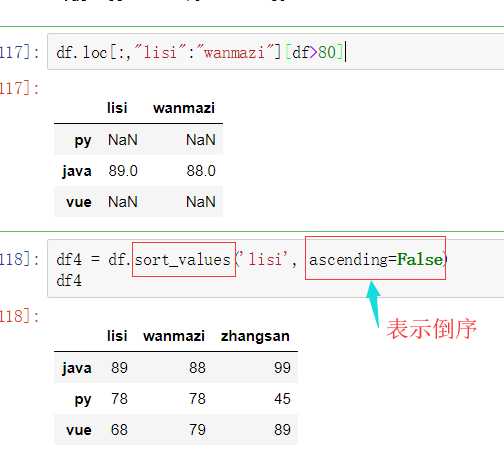
df.loc[‘java‘] # zhangsan 100 lisi 88 wangwu 78 Name: java, dtype: int64
【注意】 直接用中括号时:
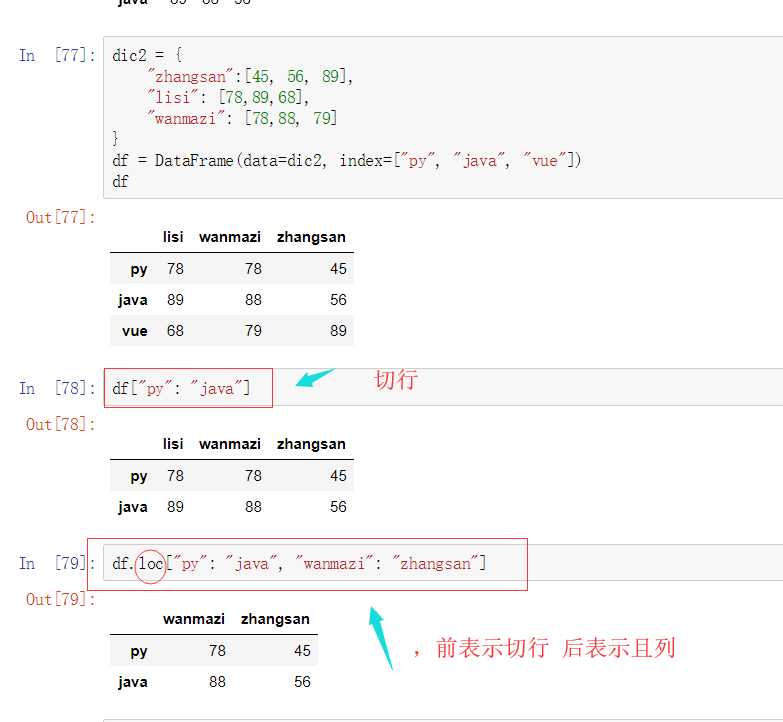
1) DataFrame之间的运算
同Series一样:
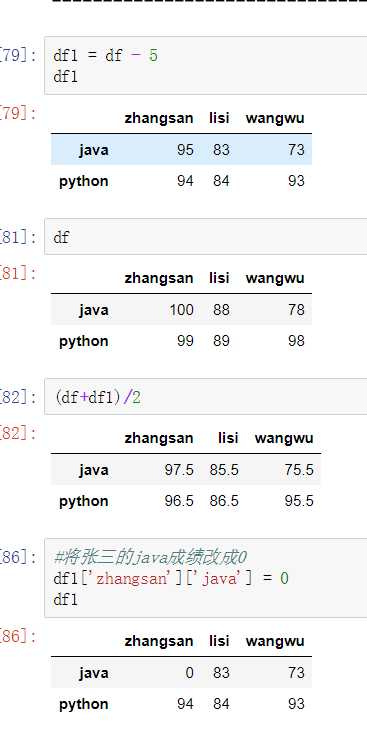
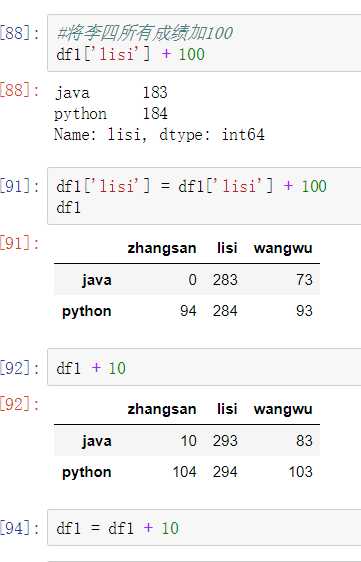

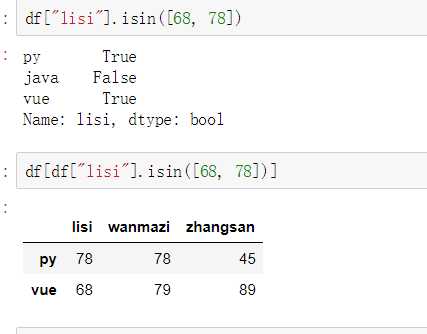
有两种丢失数据:
None是Python自带的,其类型为python object。因此,None不能参与到任何计算中。
np.nan是浮点类型,能参与到计算中。但计算的结果总是NaN。
1) pandas中None与np.nan都视作np.nan
2) pandas处理空值操作
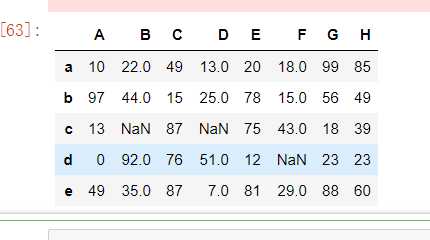
isnull()notnull()dropna(): 过滤丢失数据fillna(): 填充丢失数据#创建DataFrame,给其中某些元素赋值为nan df = DataFrame(data=np.random.randint(0,100,size=(5,8)),index=[‘a‘,‘b‘,‘c‘,‘d‘,‘e‘],columns=[‘A‘,‘B‘,‘C‘,‘D‘,‘E‘,‘F‘,‘G‘,‘H‘]) df[‘B‘][‘c‘] = None df[‘F‘][‘d‘] = np.nan df[‘D‘][‘c‘] = None df
(1)判断函数
isnull()notnull()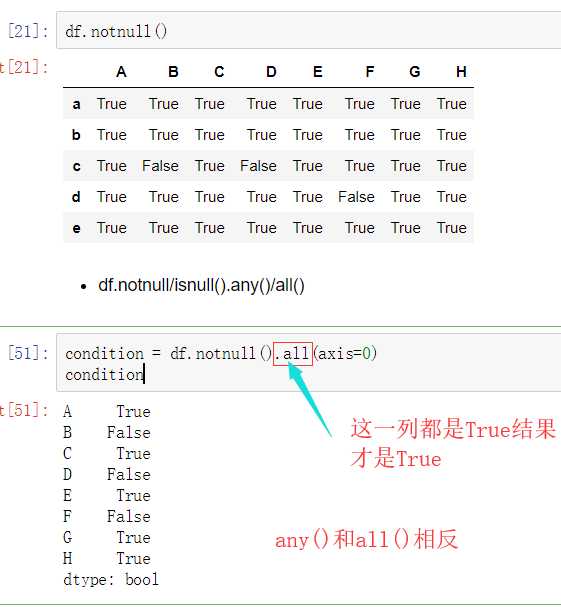
(2)过滤函数
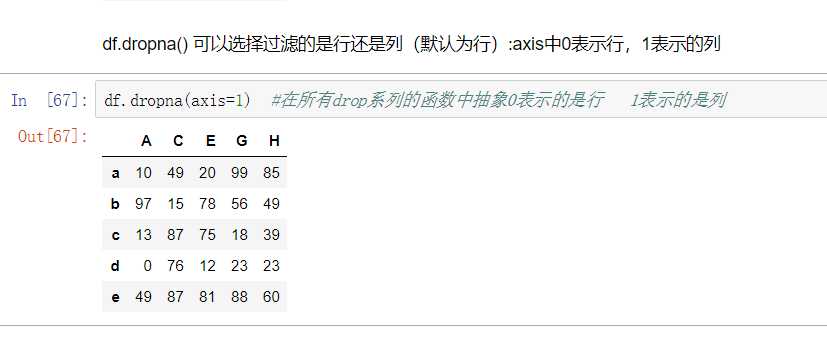
3) 填充函数 Series/DataFrame
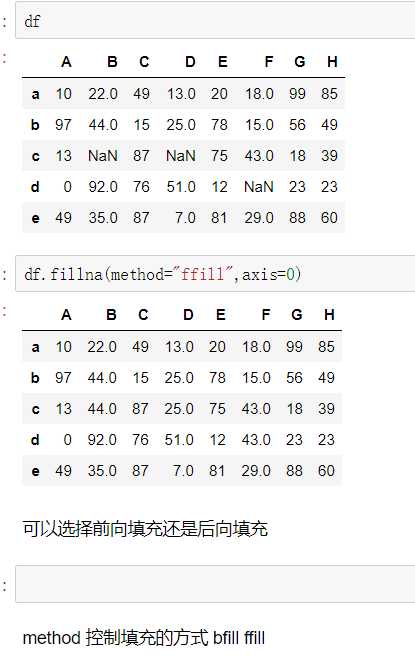
fillna():value和method参数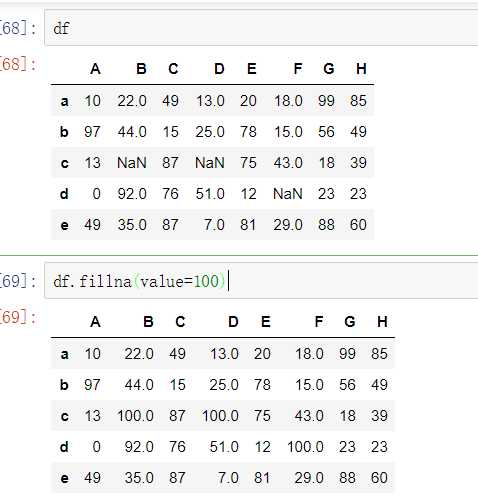
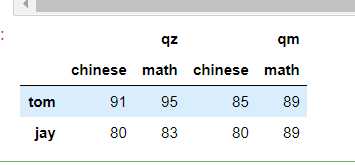
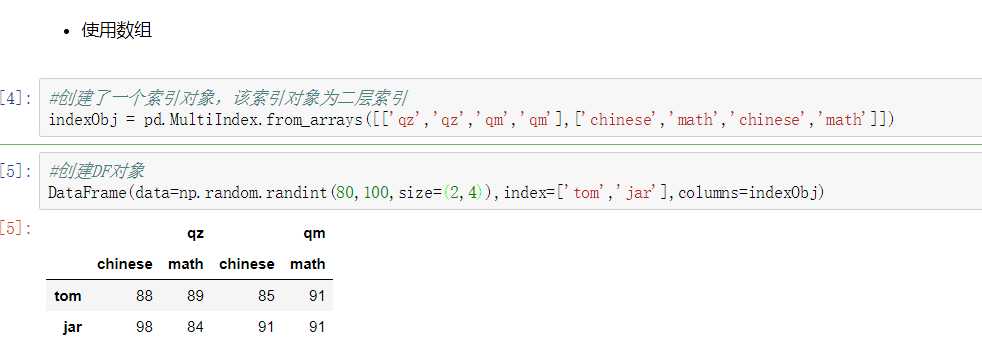
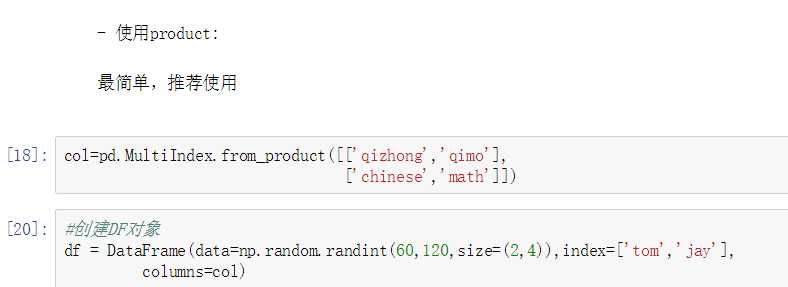
最常见的方法是给DataFrame构造函数的index或者columns参数传递两个或更多的数组
df = DataFrame(data=np.random.randint(80,100,size=(2,4)),index=[‘tom‘,‘jay‘],columns=[[‘qz‘,‘qz‘,‘qm‘,‘qm‘],[‘chinese‘,‘math‘,‘chinese‘,‘math‘]]) df
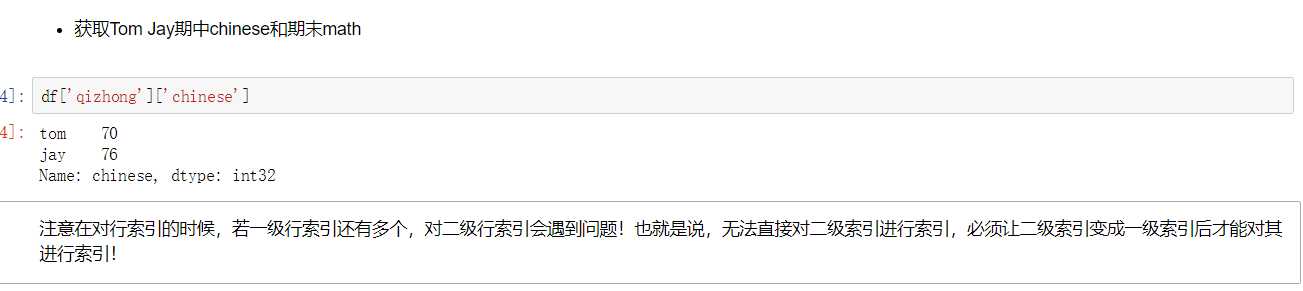
切片操作
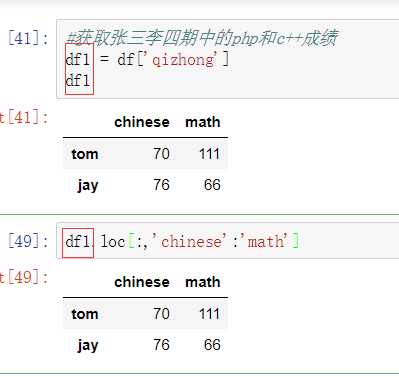
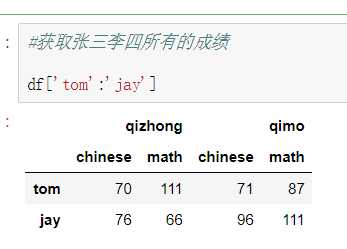

所谓的聚合操作:平均数,方差,最大值,最小值……
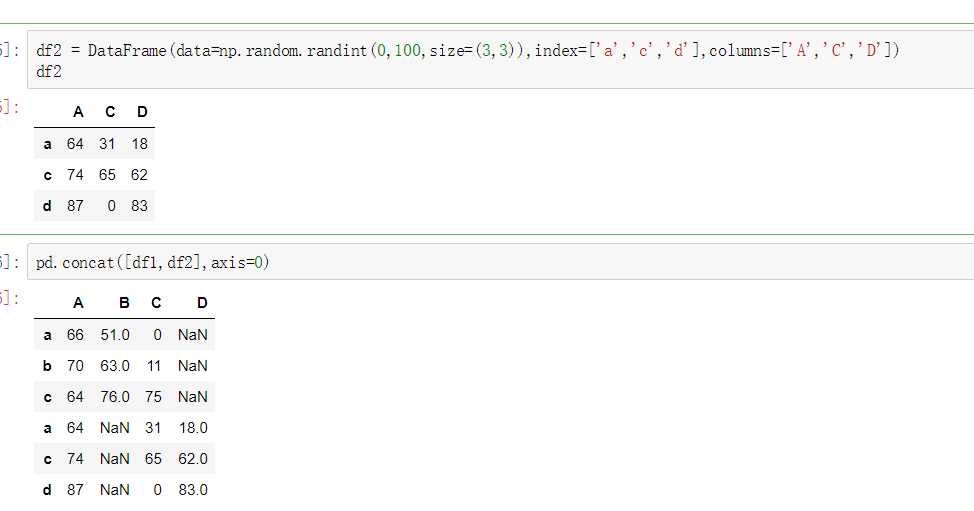
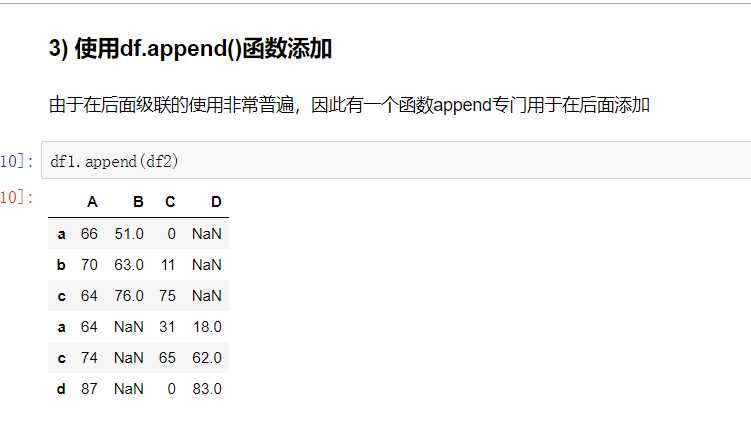
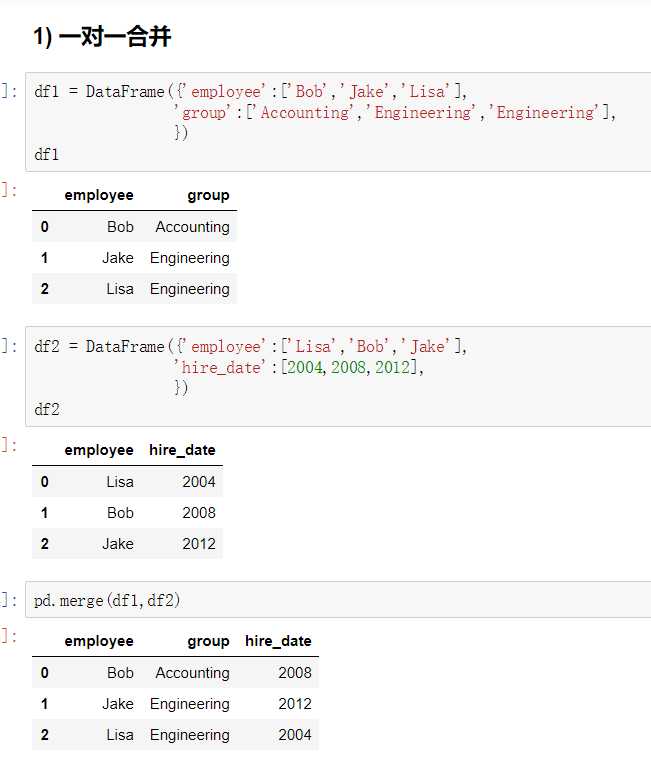
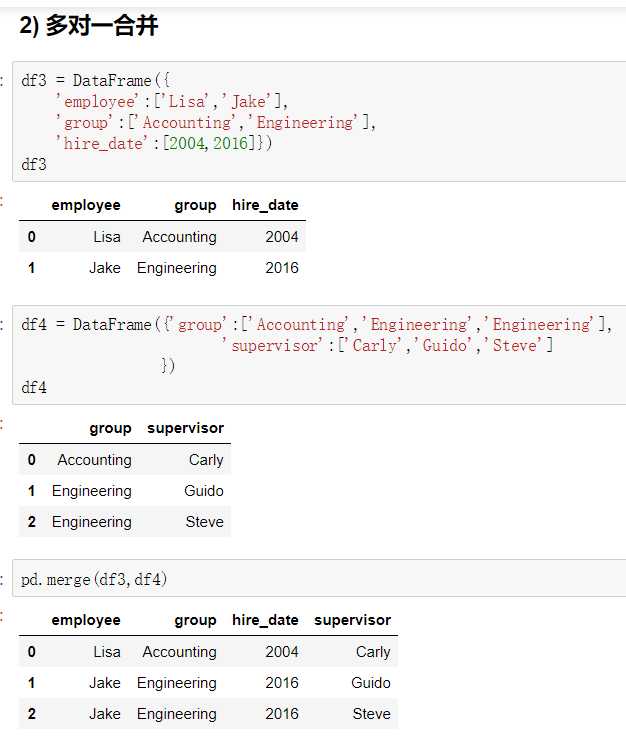
pandas的拼接分为两种:
pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
objs
axis=0
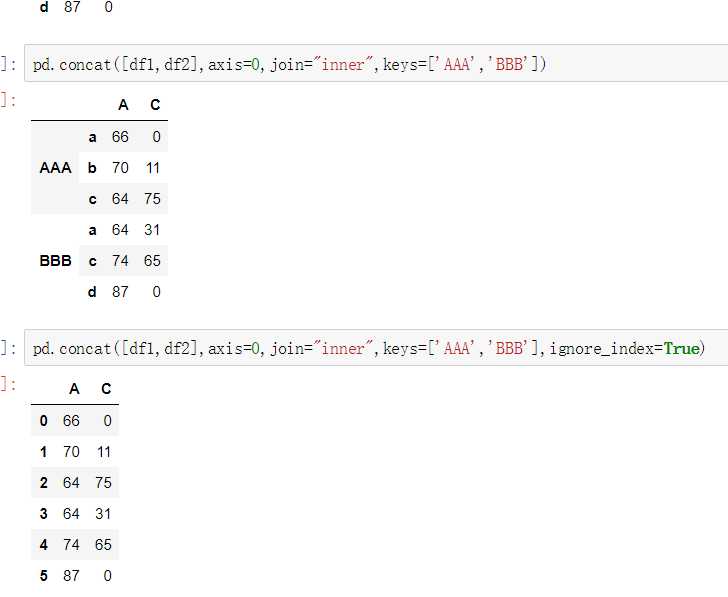
keys:列表,列表元素表示的是进行级联的df的一个名称
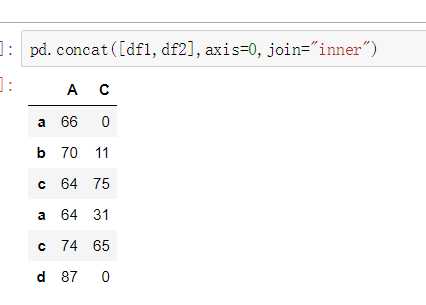
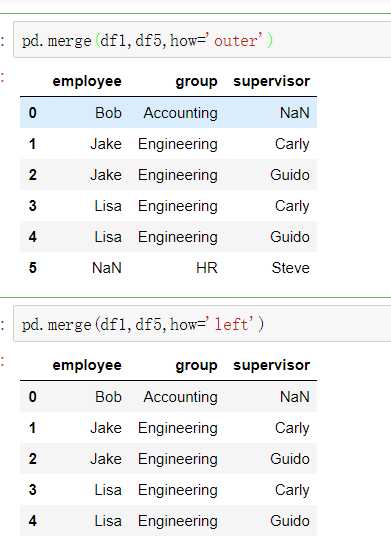
join=‘outer‘ / ‘inner‘:表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
ignore_index=False匹配级联
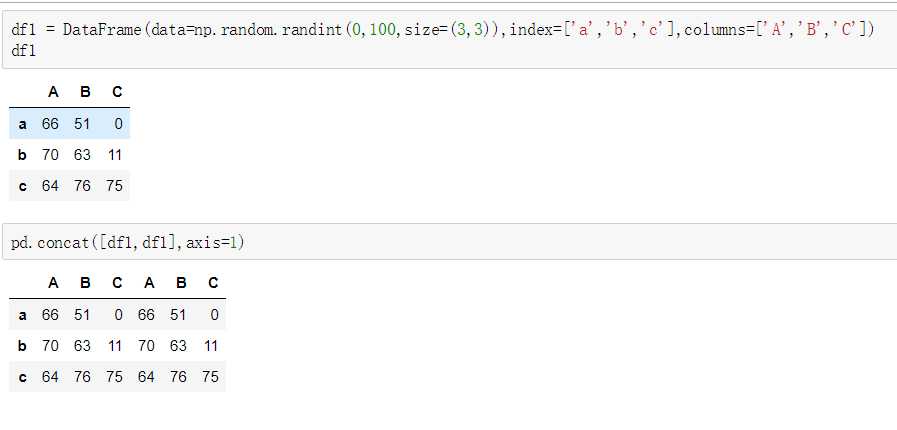
不匹配级联
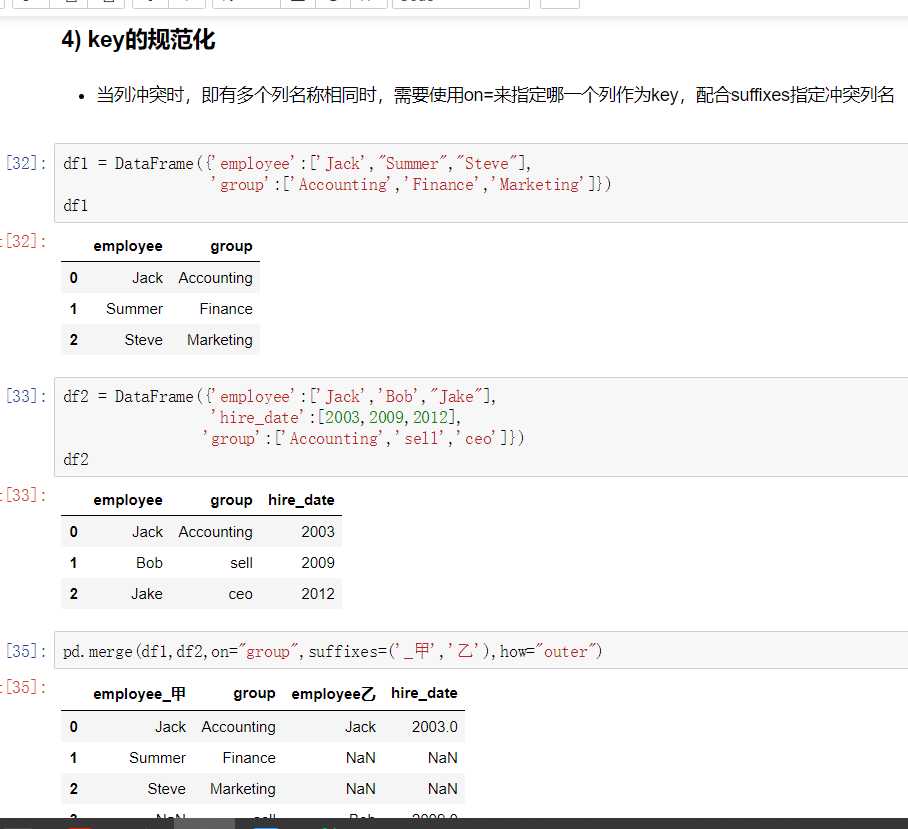
不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
有2种连接方式:



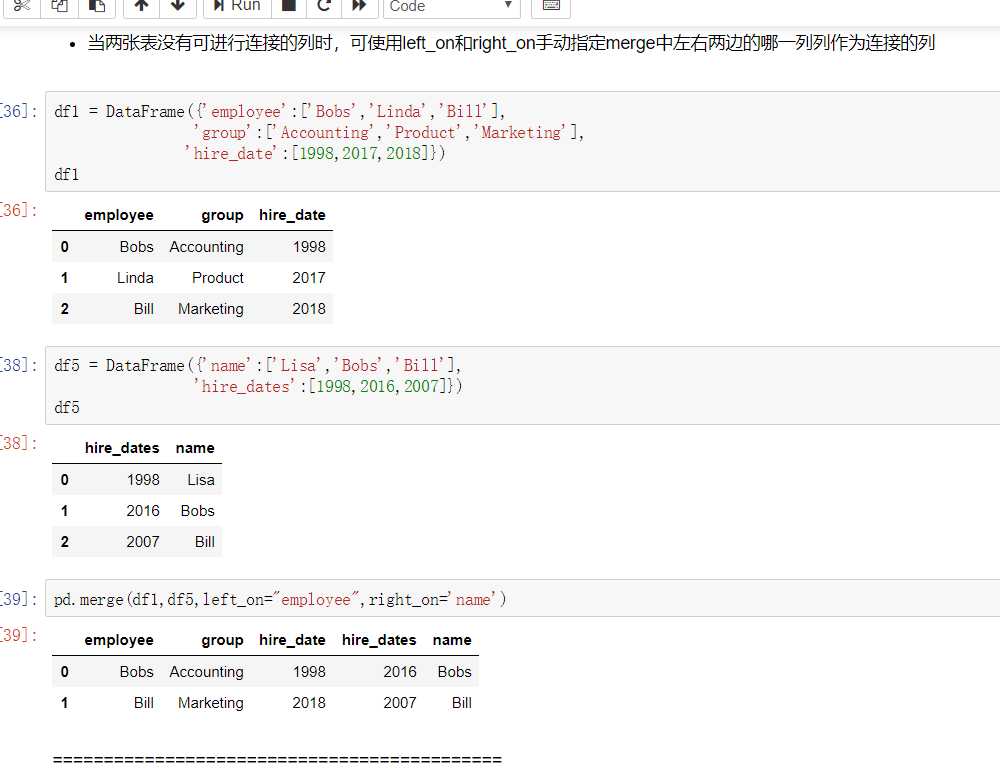
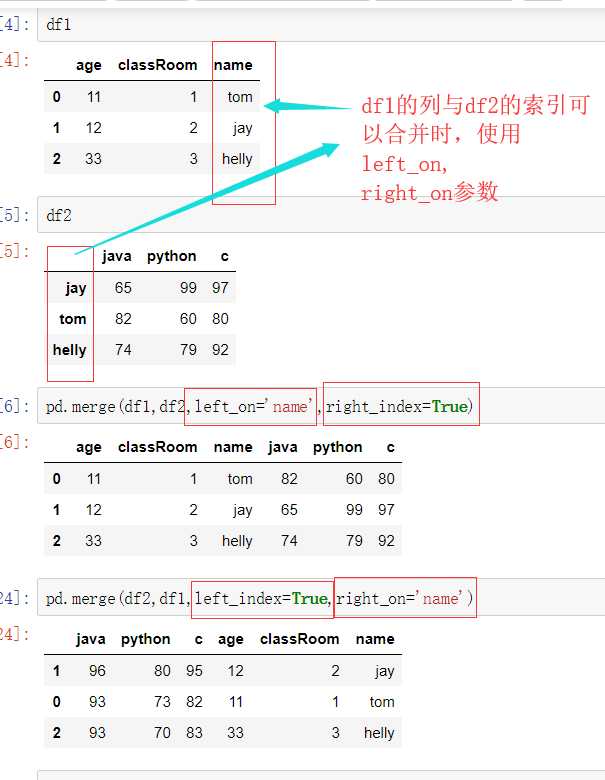
原文:https://www.cnblogs.com/qq631243523/p/10500798.html