2019-03-0911:48:22
使用post请求:
寻找url地址:
根据响应找url地址
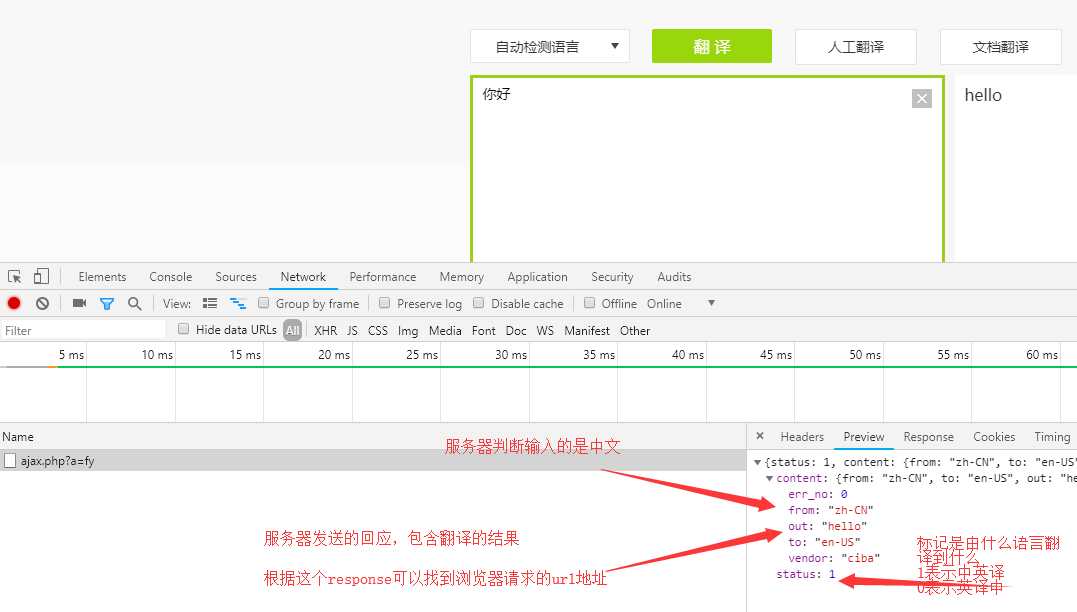
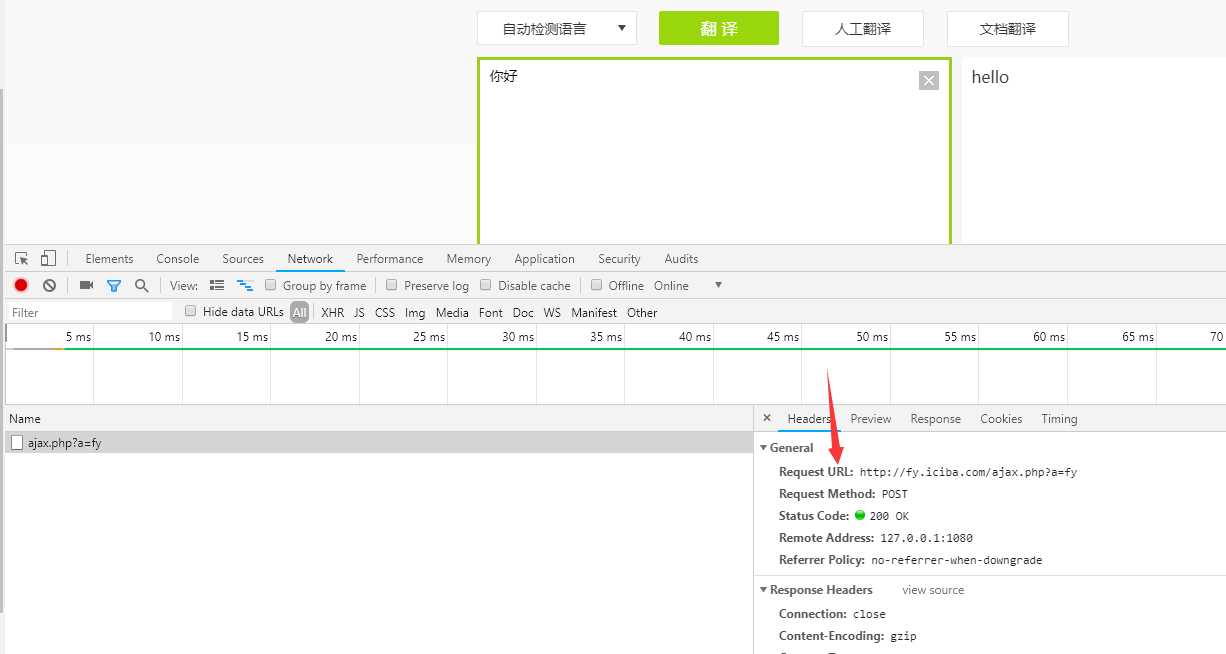
因此可以找到request的url地址: http://fy.iciba.com/ajax.php?a=fy
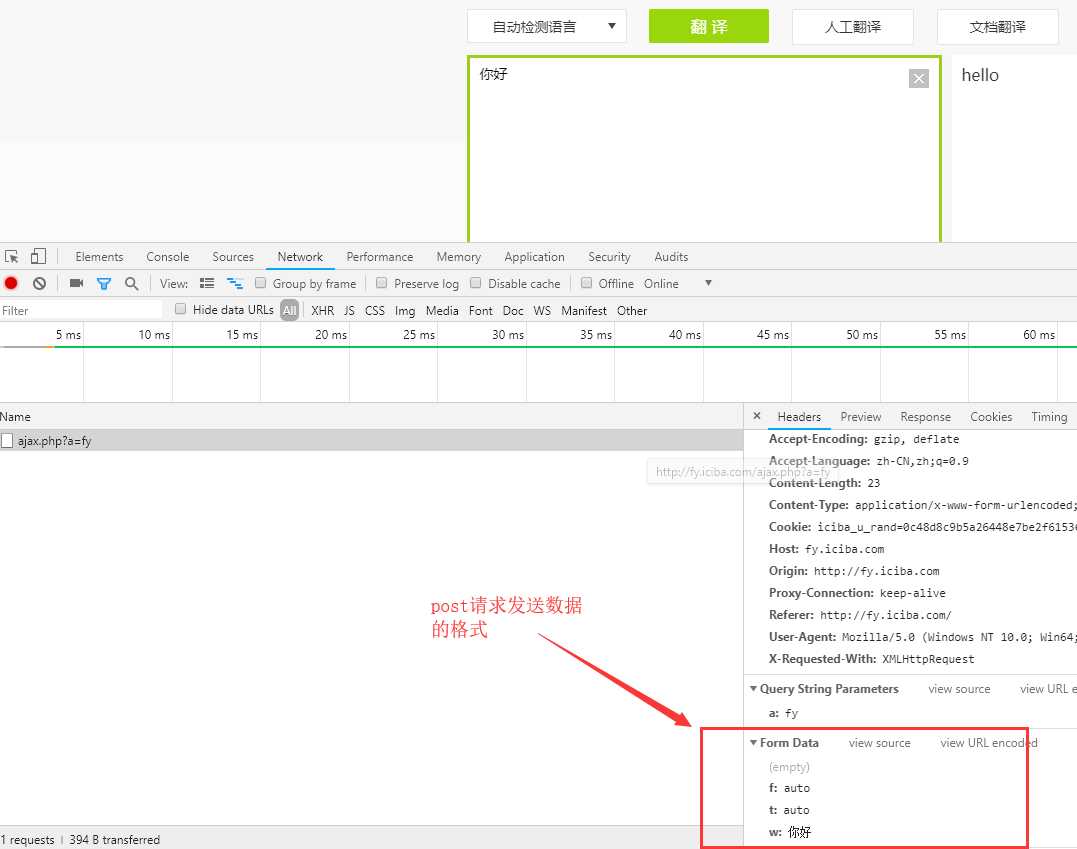
发送post请求需要post的数据格式和数据
找到了url地址和post请求的数据格式后,利用代码模拟浏览器发送请求获取响应。
代码如下:
1 import requests 2 import json 3 4 5 while True: 6 word = input("input:") 7 headers = { 8 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36"} 9 url_post = "http://fy.iciba.com/ajax.php?a=fy" 10 11 data = {"f": " auto", 12 "t": " auto", 13 "w": word 14 } 15 16 r = requests.post(url_post, headers=headers, data=data) 17 # print(r.status_code) 18 res = json.loads(r.content.decode()) 19 if res[‘status‘] == 0: 20 print("result is:\n", "\n".join(res[‘content‘][‘word_mean‘])) 21 else: 22 print("result is:\n",res[‘content‘][‘out‘])
由于服务器发送的response响应是json格式,需要调用json.loads()转换为python的数据格式。
代码可以实现本地中译英和英译中。
最后在python的数据格式中,提取想要的结果!
第一次写blog,难免有很多不足,欢迎批评指正,以后会慢慢改正。!
原文:https://www.cnblogs.com/khx686/p/10500114.html