‘‘‘
爬虫:通过编写程序,模拟浏览器上网,让其去互联网上爬取数据的过程
分类:
通用爬虫:爬取全部的页面数据
聚焦爬虫:抓取页面中局部数据
增量式爬虫:爬取网站中更新出的数据
反爬机制:门户网站会通过制定相关的技术手段,组织爬虫程序进行数据获取
反反爬策略:针对反爬机制制定的策略,为了获取数据
第一个反爬机制:
robots.txt协议:防君子不防小人的协议
‘‘‘
‘‘‘
request使用流程:
- 制定url
- 发起请求
- 获取响应回来的页面数据
- 持久化存储
‘‘‘
1 获取搜狗页面(反反爬机制:防君子不防小人)
import requests #获取搜狗页面数据 #1.指定url url=‘https://www.sogo.com/‘ #2.发起请求 response=requests.get(url=url) #3.获取页面数据 response_text=response.text #4.持久化存储 with open(‘sogo.html‘,mode=‘w‘,encoding=‘utf8‘) as f: f.write(response_text)
2 获取知乎页面数据(UA伪装)
‘‘‘
User-Agent:请求载体的身份标识
反爬机制:UA检测
反反爬策略:UA伪装
‘‘‘
#请求知乎 url=‘https://www.zhihu.com/‘ #指定请求头,进行UA伪装 headers={ ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36‘ } response=requests.get(url=url,headers=headers) print(response.text)
3 post请求实例(请求百度翻译结果)
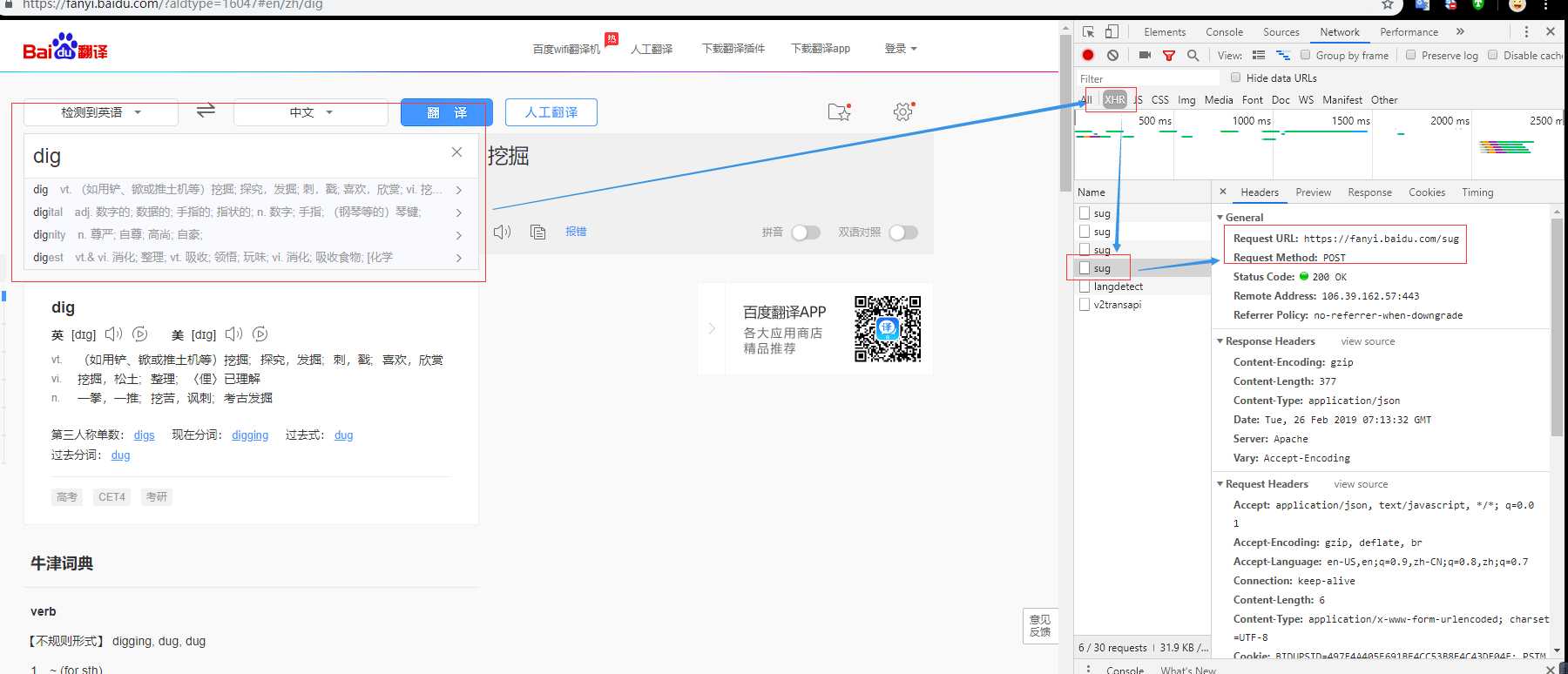
#请求百度翻译结果 #经过分析发现,百度翻译发送的请求是ajax请求
import requests url=‘https://fanyi.baidu.com/sug‘ #指定请求头,进行UA伪装 headers={ ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36‘ } #搜索数据不要写死 kw=input(‘input a word:‘) #构建请求数据 data={ ‘kw‘:kw } response=requests.post(url=url,headers=headers,data=data) print(response.json())
4 post 请求携带更多参数data={}
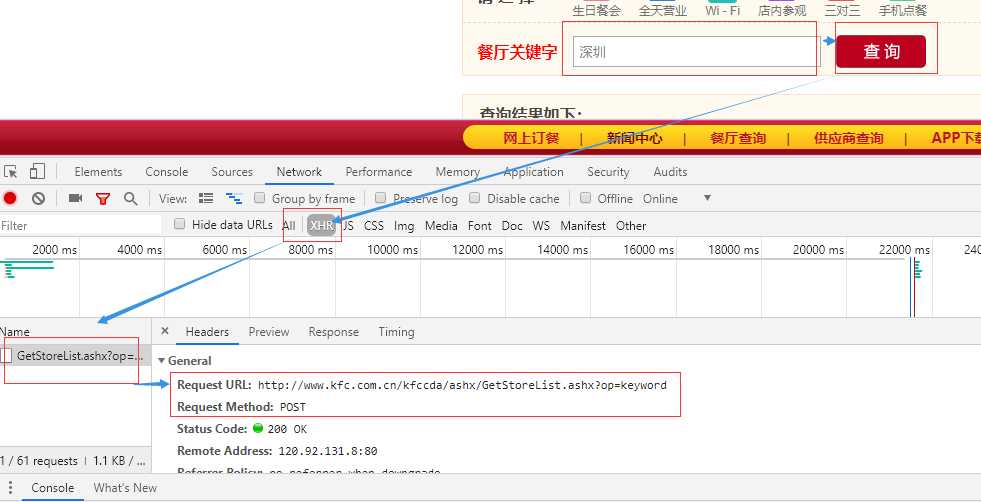
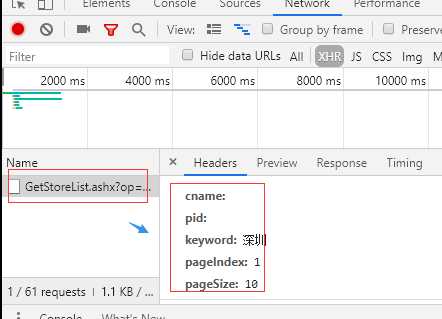
#爬取城市肯德基餐厅的位置信息 http://www.kfc.com.cn/kfccda/storelist/index.aspx ‘‘‘ 抓包获取的数据 Request URL: http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword Request Method: POST Status Code: 200 OK Remote Address: 120.92.131.8:80 Referrer Policy: no-referrer-when-downgrade ‘‘‘ import requests url=‘http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword‘ headers={ ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36‘ } data={ ‘cname‘:‘‘, ‘pid‘:‘‘, ‘keyword‘: ‘深圳‘, ‘pageIndex‘: 3, ‘pageSize‘: 10, } response=requests.post(url=url,headers=headers,data=data) print(response.json())
5 爬取豆瓣电影中的详细数据(ajax请求)
import requests #爬取豆瓣电影中的详细数据(ajax请求) #‘https://movie.douban.com/j/chart/top_list?type=24&interval_id=100%3A90&action=&start=20&limit=20‘ url=‘https://movie.douban.com/j/chart/top_list‘ headers={ ‘user-agent‘: ‘Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.20 Safari/537.36‘ } #此处参数已经写死,后续项目中在此基础修改 params={ ‘type‘: ‘24‘, ‘interval_id‘: ‘100:90‘, ‘action‘:‘‘, ‘start‘:‘40‘, ‘limit‘:‘20‘, } response=requests.get(url=url,headers=headers,params=params) print(response.json())
原文:https://www.cnblogs.com/angle6-liu/p/10437482.html