一、并发的本质
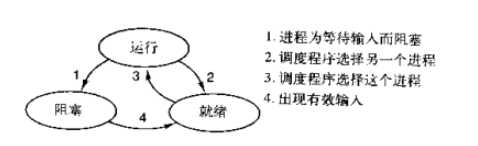
二、协程
三、协程的优缺点
四、协程的特点
五、在任务中切换的例子
def consumer(): while True: x = yield print(‘deal:‘,x) def producer(): c = consumer() next(c) for i in range(10): print(‘generate:‘,i) c.send(i) producer()
六、greenlet
#使用greenlet实现任务切换 from greenlet import greenlet def eat(): print(‘eat start‘) g2.switch() print(‘eat end‘) g2.switch() def play(): print(‘playing start‘) g1.switch() print(‘playing end‘) g1 = greenlet(eat) g2 = greenlet(play) g1.switch()

七、gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值
#如果没有遇到能识别的IO操作,不会进行任务切换,实现并发效果 #要加上from gevent import monkey;monkey.patch_all() from gevent import monkey;monkey.patch_all() import gevent,time def eat(): print(‘eat start‘) time.sleep(1) print(‘eat end‘) def play(): print(‘playing start‘) time.sleep(1) print(‘playing end‘) g1 = gevent.spawn(eat) g2 = gevent.spawn(play) g1.join() g2.join()
#我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程 from gevent import monkey;monkey.patch_all() import threading import gevent import time def eat(): print(threading.current_thread().getName()) print(‘eat food 1‘) time.sleep(2) print(‘eat food 2‘) def play(): print(threading.current_thread().getName()) print(‘play 1‘) time.sleep(1) print(‘play 2‘) g1=gevent.spawn(eat) g2=gevent.spawn(play) gevent.joinall([g1,g2]) print(‘主‘)
from gevent import monkey;monkey.patch_all() import gevent import time def task(): time.sleep(1) print(123) def synchronouse(): for i in range(10): task() def asynchronouse(): g_lst=[] for i in range(10): g = gevent.spawn(task) g_lst.append(g) gevent.joinall(g_lst) synchronouse() print(‘---‘) asynchronouse()
from gevent import monkey;monkey.patch_all() import requests import gevent url = [‘http://www.baidu.com‘, ‘http://www.sogou.com‘, ‘http://www.hao123.com‘, ‘http://www.taobao.com‘, ‘http://www.cnblog.com‘] def get_url(url): res = requests.get(url) content = res.content return len(content) g_lst = [] for i in url: g_lst.append(gevent.spawn(get_url,i)) gevent.joinall(g_lst) for i in g_lst: print(i.value)
原文:https://www.cnblogs.com/walthwang/p/10427804.html