在SQL复习中,分为两大部分,一主要是先大致过一遍常用的数据操作--菜鸟联盟,二是再结合牛客网上的SQL例题和编程进行查漏补缺。
定义: SQL语句即结构化查询语言,目前使用的是SQL92,
用途: SQL语句解决--1)关系数据库(关系型数据库是由多张能互相联接的二维行列表格组成的数据库),2 )非关系型数据库,即数据结构化存储方法的集合,可以是文档或者键值对等,常用spark,hive作为接口。
分类: 常用SQL语句类型
DDL( Data Definition Language数据定义语言): 数据定义类型 ,用来建立数据库
- TPL 事务处理语言
- DCL( Data Control Language数据控制语言;控制数据库对象的访问权限
- DML( Data Manipulation Language数据操作语言),对数据进行操作,****
创建数据库,含有一个简单的数据表,并进行C(创建)U(更新)R(读取,查询)D(删除)操作数据表
CREATE DATABASE STUDENTS
USE STUDENTS
show DATABASES
SELECT DATABASE()
删除数据库 drop databases 数据库名
DROP DATABASE STUDENTS
在数据库中创建表----
CREATE TABLE tb1(
ID INT(20) NOT NULL,
姓名 varchar(20),
性别 varchar(5)
)
#查看数据表
SHOW TABLES FROM STUDENTS
#查看数据表结构
SHOW COLUMNS FROM STUDENTS
向 表中插入元素 INSERT 表名称 (列1, 列2,...) VALUES (值1, 值2,....)
INSERT tb1(ID, 姓名, 性别) VALUES(1,‘张三‘, ‘男‘);
INSERT tb1(ID, 姓名, 性别) VALUES(2,‘李四‘, ‘女‘);
INSERT tb1(ID, 姓名, 性别) VALUES(3,‘王五‘, ‘男‘);
INSERT tb1(ID, 姓名, 性别) VALUES(4,‘赵六‘, ‘女‘);
---------------------
删除记录的数据-----DELETE FROM 表名 WHERE 列名称 = 某值
DELETE FROM tb1 WHERE 姓名 = ‘赵六‘
更新记录中的数据-----UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
UPDATE persons SET 性别 = ‘男‘ WHERE 姓名 =‘赵六‘
ALTER TABLE 语句用于在已有的表中添加、修改或删除列
select 语句
select colum 1 ,colum 2 from table # 从表中搜索数据列1,和2
select distinct SELECT DISTINCT 语句用于返回唯一不同的值,去除重复值
SELECT DISTINCT column_name,column_name
FROM table_name;
WHERE 子句用于提取那些满足指定标准的记录。where后面一般跟指定的标准,常与select一起用
SELECT column_name,column_name
FROM table_name
WHERE column_name operator value;
使用单引号来环绕文本值(大部分数据库系统也接受双引号)。如果是数值字段,请不要使用引号
where后子句常用的运算符
如语句选取 name 以字母 "G" 开始的所有客户WHERE name LIKE ‘G%‘;选取 name 以字母 "k" 结尾的所有客户,WHERE name LIKE ‘%k‘; name 包含模式 "oo" 的所有客户,WHERE name LIKE ‘%oo%‘;
下面的 SQL 语句选取 name 以一个任意字符开始,然后是 "oogle" 的所有客户:WHERE name REGEXP ‘^[GFs]‘; name 以 "G"、"F" 或 "s" 开始的所有网站
AND & OR 运算符用于基于一个以上的条件对记录进行过滤。常和where连用
SELECT * FROM Websites
WHERE alexa > 15
AND (country=‘CN‘ OR country=‘USA‘);
ORDER BY 关键字用于对结果集进行排序。
SELECT column_name,column_name
FROM table_name
ORDER BY column_name,column_name ASC|DESC;
ORDER BY 多列的时候,先按照第一个column name排序,在按照第二个column name排序;默认是升序
order by A,B 这个时候都是默认按升序排列
order by A desc,B 这个时候 A 降序,B 升序排列
order by A ,B desc 这个时候 A 升序,B 降序排列
INSERT INTO 语句用于向表中插入新记录。
INSERT INTO 语句可以有两种编写形式。
第一种形式无需指定要插入数据的列名,只需提供被插入的值即可:
INSERT INTO table_name
VALUES (value1,value2,value3,...);
第二种形式需要指定列名及被插入的值:
INSERT INTO table_name (column1,column2,column3,...)
VALUES (value1,value2,value3,...);
UPDATE 语句用于更新表中已存在的记录。where不能省略
UPDATE table_name
SET column1=value1,column2=value2,...
WHERE some_column=some_value;
DELETE 语句用于删除表中的行。如果省略了where,则所有记录都被删除
DELETE FROM table_name
WHERE some_column=some_value;
SELECT TOP 子句用于规定要返回的记录的数目。SELECT TOP 子句对于拥有数千条记录的大型表来说,是非常有用的,并非所有的数据库系统都支持 SELECT TOP 语句。 MySQL 支持 LIMIT 语句来选取指定的条数数据, Oracle 可以使用 ROWNUM 来选取。
SQL Server / MS Access 语法
SELECT TOP number|percent column_name(s)
FROM table_name;
MySQL 语法
SELECT column_name(s)
FROM table_name
LIMIT number;
实例
SELECT *
FROM Persons
LIMIT 5;
Oracle 语法
SELECT column_name(s)
FROM table_name
WHERE ROWNUM <= number;
实例
SELECT *
FROM Persons
WHERE ROWNUM <=5;
between 用于两个数值之间
SQL 语句选取 alexa 介于 1 和 20 之间但 country 不为 USA 和 IND 的所有网站:
实例
SELECT * FROM Websites
WHERE (alexa BETWEEN 1 AND 20)
AND country NOT IN (‘USA‘, ‘IND‘);
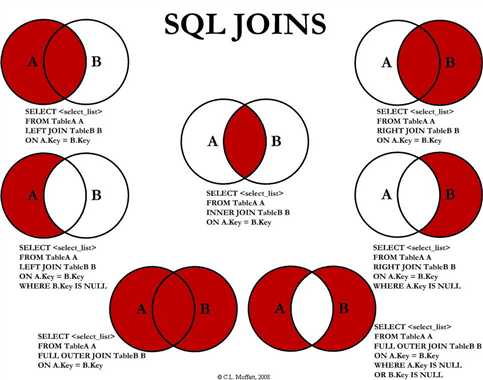
1. SQL JOIN 子句用于把来自两个或多个表的行结合起来,基于这些表之间的共同字段。
最常见的 JOIN 类型:SQL INNER JOIN(简单的 JOIN)。 SQL INNER JOIN 从多个表中返回满足 JOIN 条件的所有行。满足A也满足B的数据
SELECT Websites.id, Websites.name, access_log.count, access_log.date
FROM Websites
INNER JOIN access_log
ON Websites.id=access_log.site_id;
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name=table2.column_name;
注释:INNER JOIN 与 JOIN 是相同的。
注释:INNER JOIN 关键字在表中存在至少一个匹配时返回行。如果 "Websites" 表中的行在 "access_log" 中没有匹配,则不会列出这些行,以A为参照,找B中id相同的,补充其他属性
LEFT JOIN 关键字从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
LEFT OUTER JOIN table2
ON table1.column_name=table2.column_name;
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。带不带outer都一样
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name=table2.column_name;
或:
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
注释:在某些数据库中,RIGHT JOIN 称为 RIGHT OUTER JOIN。
FULL OUTER JOIN 关键字只要左表(table1)和右表(table2)其中一个表中存在匹配,则返回行.
FULL OUTER JOIN 关键字结合了 LEFT JOIN 和 RIGHT JOIN 的结果。
SELECT column_name(s)
FROM table1
FULL OUTER JOIN table2
ON table1.column_name=table2.column_name;
FULL OUTER JOIN 关键字返回左表(Websites)和右表(access_log)中所有的行。如果 "Websites" 表中的行在 "access_log" 中没有匹配或者 "access_log" 表中的行在 "Websites" 表中没有匹配,也会列出这些行。---相当于是同时查找了两个表
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
请注意,UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;
注释:默认地,UNION 操作符选取不同的值。如果允许重复的值,请使用 UNION ALL。
下面的 SQL 语句使用 UNION ALL 从 "Websites" 和 "apps" 表中选取所有的中国(CN)的数据(也有重复的值):
实例
SELECT country, name FROM Websites
WHERE country=‘CN‘
UNION ALL
SELECT country, app_name FROM apps
WHERE country=‘CN‘
ORDER BY country;
SELECT INTO 语句从一个表复制数据,然后把数据插入到另一个新表中。
MySQL 数据库不支持 SELECT ... INTO 语句,但支持 INSERT INTO ... SELECT 。
当然你可以使用以下语句来拷贝表结构及数据:
CREATE TABLE 新表
AS
SELECT * FROM 旧表
SQL SELECT INTO 语法
我们可以复制所有的列插入到新表中:
SELECT *
INTO newtable [IN externaldb]
FROM table1;
或者只复制希望的列插入到新表中:
SELECT column_name(s)
INTO newtable [IN externaldb]
FROM table1;
INSERT INTO SELECT 语句从一个表复制数据,然后把数据插入到一个已存在的表中。目标表中任何已存在的行都不会受影响
我们可以从一个表中复制所有的列插入到另一个已存在的表中:
INSERT INTO table2
SELECT * FROM table1;
或者我们可以只复制希望的列插入到另一个已存在的表中:
INSERT INTO table2
(column_name(s))
SELECT column_name(s)
FROM table1;
SQL 约束用于规定表中的数据规则。
如果存在违反约束的数据行为,行为会被约束终止。
约束可以在创建表时规定(通过 CREATE TABLE 语句),或者在表创建之后规定(通过 ALTER TABLE 语句)
SQL CREATE TABLE + CONSTRAINT 语法
CREATE TABLE table_name
(
column_name1 data_type(size) constraint_name,
column_name2 data_type(size) constraint_name,
column_name3 data_type(size) constraint_name,
....
);
在 SQL 中,我们有如下约束:
CREATE TABLE Persons
(
P_Id int NOT NULL,
LastName varchar(255) NOT NULL,
FirstName varchar(255),
Address varchar(255),
City varchar(255)
)
您可以在表中创建索引,以便更加快速高效地查询数据。
用户无法看到索引,它们只能被用来加速搜索/查询。
注释:更新一个包含索引的表需要比更新一个没有索引的表花费更多的时间,这是由于索引本身也需要更新。因此,理想的做法是仅仅在常常被搜索的列(以及表)上面创建索引
在表上创建一个简单的索引。允许使用重复的值:
CREATE INDEX index_name
ON table_name (column_name)
在表上创建一个唯一的索引。不允许使用重复的值:唯一的索引意味着两个行不能拥有相同的索引值。Creates a unique index on a table. Duplicate values are not allowed:
CREATE UNIQUE INDEX index_name
ON table_name (column_name)
注释:用于创建索引的语法在不同的数据库中不一样。因此,检查您的数据库中创建索引的语法
视图
函数
AVG() 函数返回数值列的平均值
COUNT(column_name) 函数返回指定列的值的数目(NULL 不计入):
FIRST() 函数返回指定的列中第一个记录的值
LAST() 函数返回指定的列中最后一个记录的值。
在 SQL 中增加 HAVING 子句原因是,WHERE 关键字无法与聚合函数一起使用。
HAVING 子句可以让我们筛选分组后的各组数据。
6.错题解析
注意limit用法 可用于查找最后一个,前几个的数据,排名
下面是几种limit的方法:原则看看下面几个例子应该就懂了
在数据库中很多地方都会用到,比如当你数据库查询记录有几万、几十万时使用limit查询效率非常快,只需要查询出你需要的数据就可以了·再也不用全表查询导致查询数据库崩溃的情况。
select * from Customer LIMIT 10;--检索前10行数据,显示1-10条数据
select * from Customer LIMIT 1,10;--检索从第2行开始,累加10条id记录,共显示id为2....11
select * from Customer limit 5,10;--检索从第6行开始向前加10条数据,共显示id为6,7....15
select * from Customer limit 6,10;--检索从第7行开始向前加10条记录,显示id为7,8...16
原文:https://www.cnblogs.com/869222wxy-/p/10426104.html