文档http://keras.io
使用GPU加速模型训练:
1)选择合适的代价函数loss:MSE (Mean Squared Error)均方误差,Cross Entropy交叉熵。当输出层为softmax层时,选择交叉熵代价函数更为科学。
2)设置合理的batch size(每次批处理训练样本个数):所有的训练样本分出batch size个mini-batch用于训练,所有的mini-batch都训练完一次以后,记为完成了一个epoch。
使用mini-batch会使得loss可能会停留在局部极小值,但多完成几次epoch,这个问题就解决了;使用mini-batch会使得模型精确度提升。
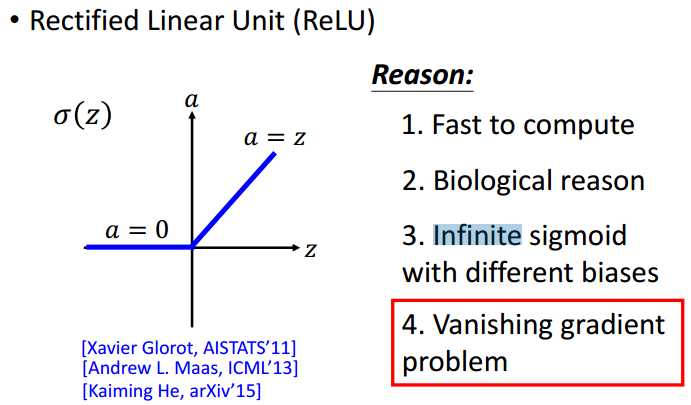
3)选择合适的active function(激活函数):Sigmod函数和ReLU(Rectified Linear Unit )函数。采用RelU激活函数可以解决梯度消失问题。
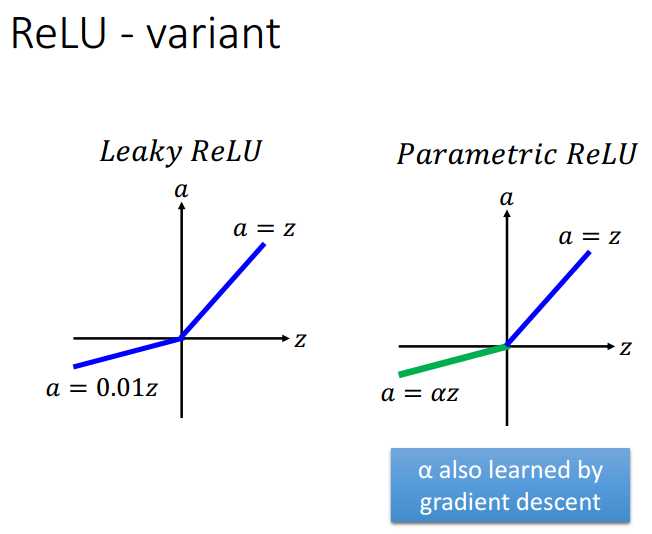
ReLU及其变体:
原文:https://www.cnblogs.com/defe-learn/p/10350642.html