SQLAlchemy 是一个用 Python 实现的 ORM (Object Relational Mapping)框架,它由多个组件构成,这些组件可以单独使用,也能独立使用。它的组件层次结构如下:
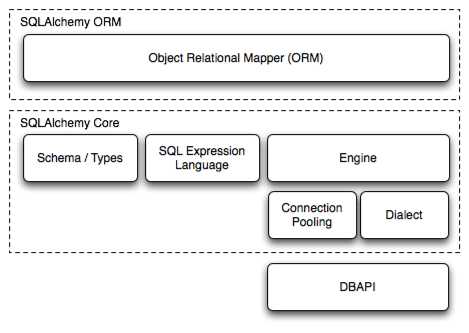
其中最常用的组件,应该是 ORM 和 SQL 表达式语言,这两者既可以独立使用,也能结合使用。
ORM 的好处在于它
但是 ORM 需要消耗额外的性能来处理对象关系映射,此外用 ORM 做多表关联查询或复杂 SQL 查询时,效率低下。因此它适用于场景不太复杂,性能要求不太苛刻的场景。
第一步是创建数据库引擎实例:
from sqlalchemy import create_engine
engine = create_engine('sqlite:///:memory:',
echo=True, # echo=True 表示打印出自动生成的 SQL 语句(通过 logging)
pool_size=5, # 连接池容量,默认为 5,生产环境下太小,需要修改。
# connection 回收的时间限制,默认 -1 不回收
pool_recyle=7200) # 超过 2 小时就重新连接(MySQL 默认的连接最大闲置时间为 8 小时)create_engine 接受的第一个参数是数据库 URI,格式为 dialect[+driver]://user:password@host/dbname[?key=value..],dialect 是具体的数据库名称,driver 是驱动名称。key-value 是可选的参数。举例:
# PostgreSQL
postgresql+psycopg2://scott:tiger@localhost/dbtest
# MySQL + PyMySQL(或者用更快的 mysqlclient)
mysql+pymysql://scott:tiger@localhost/dbtest
# sqlite 内存数据库
# 注意 sqlite 要用三个斜杠,表示不存在 hostname,sqlite://<nohostname>/<path>
sqlite:///:memory:
# sqlite 文件数据库
# 四个斜杠是因为文件的绝对路径以 / 开头:/home/ryan/Codes/Python/dbtest.db
sqlite:////home/ryan/Codes/Python/dbtest.db
# SQL Server + pyodbc
# 首选基于 dsn 的连接,dsn 的配置请搜索hhh
mssql+pyodbc://scott:tiger@some_dsn引擎创建后,我们就可以直接获取 connection,然后执行 SQL 语句了。这种用法相当于把 SQLAlchemy 当成带 log 的数据库连接池使用:
with engine.connect() as conn:
res = conn.execute("select username from users") # 无参直接使用
# 使用问号作占位符,前提是下层的 DBAPI 支持。更好的方式是使用 text(),这个后面说
conn.execute("INSERT INTO table (id, value) VALUES (?, ?)", 1, "v1") # 参数不需要包装成元组
# 查询返回的是 ResultProxy 对象,有和 dbapi 相同的 fetchone()、fetchall()、first() 等方法,还有一些拓展方法
for row in result:
print("username:", row['username'])但是要注意的是,connection 的 execute 是自动提交的(autocommit),这就像在 shell 里打开一个数据库客户端一样,分号结尾的 SQL 会被自动提交。
只有在 BEGIN TRANSACTION 内部,AUTOCOMMIT 会被临时设置为 FALSE,可以通过如下方法开始一个内部事务:
def transaction_a(connection):
trans = connection.begin() # 开启一个 transaction
try:
# do sthings
trans.commit() # 这里需要手动提交
except:
trans.rollback() # 出现异常则 rollback
raise
# do other things
with engine.connect() as conn:
transaction_a(conn)相比直接使用 string,text() 的优势在于它:
# 1. 参数绑定语法
from sqlalchemy import text
result = connection.execute(
# 使用 :key 做占位符
text('select * from table where id < :id and typeName=:type'),
{'id': 2,'type':'USER_TABLE'}) # 用 dict 传参数,更易读
# 2. 参数类型指定
from sqlalchemy import DateTime
date_param=datetime.today()+timedelta(days=-1*10)
sql="delete from caw_job_alarm_log where alarm_time<:alarm_time_param"
# bindparams 是 bindparam 的列表,bindparam 则提供参数的一些额外信息(类型、值、限制等)
t=text(sql, bindparams=[bindparam('alarm_time_param', type_=DateTime, required=True)])
connection.execute(t, {"alarm_time_param": date_param})stmt = text("SELECT * FROM table",
# 使用 typemap 指定将 id 列映射为 Integer 类型,name 映射为 String 类型
typemap={'id': Integer, 'name': String},
)复杂的 SQL 查询可以直接用 raw sql 写,而增删改一般都是单表操作,用 SQL 表达式语言最方便。
SQLAlchemy 表达式语言是一个使用 Python 结构表示关系数据库结构和表达式的系统。
待续
详见 SQL 表达式语言入门
待续
数据库迁移:alembic
原文:https://www.cnblogs.com/kirito-c/p/10269485.html