本来打算学习pandas模块,并写一个博客记录一下自己的学习,但是不知道怎么了,最近好像有点急功近利,就想把别人的东西复制过来,当心沉下来,自己自觉地将原本写满的pandas学习笔记删除了,这次打算写上自己的学习记录,这里送给自己一句话,同时送给看这篇博客的人,共勉
当你迷茫的时候,当你饱受煎熬的时候,请停下来,想想自己学习的初衷,想想自己写博客的初衷,爱你所爱,行你所行,听从你心,无问西东。
好了,正文开始。
pandas是做数据分析非常重要的一个模块,它使得数据分析的工作变得更快更简单。由于现实世界中数据源的格式非常多,但是pandas也支持了不同数据格式的导入方法,所以学习pandas非常有必要。
本文首先记录一下自己学习read_csv的笔记,当然了自己需要用什么,就学习什么,而不是记录人家read_csv的所有方法,要是想看所有的方法详解可以去官网,要想学习Pandas建议先看下面2个网站。
官网地址如下:https://pandas.pydata.org/
官网教程如下(十分钟搞定pandas):https://pandas.pydata.org/pandas-docs/stable/10min.html
NAN (数值数据类型的一类数),全称Not a Number ,表示未定义或者不可表示的值。
Train_A_001.csv文件内容如下:
0.916,4.37,-1.372,0.102,0.041,0.069,0.018 0.892,3.955,-1.277,0.015,-0.099,-0.066,0.018 0.908,3.334,-1.193,0.033,-0.098,-0.059,0.018 1.013,3.022,-1.082,0.151,0.015,0.035,0.018 1.111,2.97,-1.103,-0.048,-0.175,-0.171,0.019 1.302,3.043,-1.089,0.011,-0.085,-0.097,0.018 1.552,3.017,-1.052,0.066,-0.002,-0.036,0.019 1.832,2.796,-0.933,0.002,-0.028,-0.075,0.019 2.127,2.521,-0.749,0.011,0.041,-0.022,0.019 2.354,2.311,-0.623,-0.038,0.012,-0.056,0.019 2.537,2.024,-0.452,0.039,0.089,0.031,0.019 2.639,1.669,-0.277,-0.005,0.036,-0.008,0.019 2.707,1.314,-0.214,0.013,0.031,-0.005,0.019 2.81,0.926,-0.142,0.062,0.046,0.031,0.019
read_csv读取的数据类型为Dataframe,通过obj.dtypes可以查看每列的数据类型
首先说一下,我这段csv文件是没有列索引的,那么我的读取代码如下可以读取到什么呢?
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename) print(data)
结果如下;
0.916 4.37 -1.372 0.102 0.041 0.069 0.018 0 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 1 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018 2 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 3 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019 4 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018 5 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019 6 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019 7 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019 8 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019 9 2.537 2.024 -0.452 0.039 0.089 0.031 0.019 10 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019 11 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019 12 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
大家可以发现,它默认你有列索引,并且把第一行的数据当做列索引,并且从第二行开始设置了行索引,所以说列索引的设置非常重要,起码在这里看来是这样的,那么如何设置呢,下面就具体分析一下。
当加上header=None的时候,表明原始文件没有列索引,这样的话会默认自动加上,除非你给定名称。结果如下:
0 1 2 3 4 5 6 0 0.916 4.370 -1.372 0.102 0.041 0.069 0.018 1 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 2 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018 3 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 4 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019 5 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018 6 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019 7 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019 8 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019 9 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019 10 2.537 2.024 -0.452 0.039 0.089 0.031 0.019 11 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019 12 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019 13 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
当加上header=0的时候,表明原始文件的第0行为列索引。结果如下:
0.916 4.37 -1.372 0.102 0.041 0.069 0.018 0 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 1 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018 2 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 3 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019 4 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018 5 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019 6 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019 7 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019 8 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019 9 2.537 2.024 -0.452 0.039 0.089 0.031 0.019 10 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019 11 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019 12 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
从这段代码我们可以发现,少了一行,所以第一行的代码也被默认为列索引。
当没有列索引的时候,我们也可以自己指定索引名称,方便自己记录,代码如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,header=None,names=(‘a‘,‘b‘,‘c‘,‘d‘,‘e‘,‘f‘,‘g‘)) print(data)
通过上述代码,我们可以指定列索引为a~f,结果如下:
a b c d e f g 0 0.916 4.370 -1.372 0.102 0.041 0.069 0.018 1 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 2 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018 3 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 4 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019 5 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018 6 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019 7 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019 8 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019 9 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019 10 2.537 2.024 -0.452 0.039 0.089 0.031 0.019 11 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019 12 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019 13 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
从上面的代码,我们可以发现,没有行索引,只要设置了列索引就行,但是真的行索引不重要吗,当然不是,有些时候有些需求也是需要列索引为自己定义的名称,这里我们同样看待,并学习一下:
当设置行索引为None的时候,也就是index_col = None,同时设置列索引的时候,代码如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None) print(data)
结果呢,如下:
0 1 2 3 4 5 6 0 0.916 4.370 -1.372 0.102 0.041 0.069 0.018 1 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 2 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018 3 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 4 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019 5 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018 6 1.552 3.017 -1.052 0.066 -0.002 -0.036 0.019 7 1.832 2.796 -0.933 0.002 -0.028 -0.075 0.019 8 2.127 2.521 -0.749 0.011 0.041 -0.022 0.019 9 2.354 2.311 -0.623 -0.038 0.012 -0.056 0.019 10 2.537 2.024 -0.452 0.039 0.089 0.031 0.019 11 2.639 1.669 -0.277 -0.005 0.036 -0.008 0.019 12 2.707 1.314 -0.214 0.013 0.031 -0.005 0.019 13 2.810 0.926 -0.142 0.062 0.046 0.031 0.019
当然了,在做数据分析的许多时候,我们会读取指定的某一列,使用的函数如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None,usecols=[1]) print(data)
上面意思是使用第一列数据(列表默认从0开始的啊),结果如下:
1 0 4.370 1 3.955 2 3.334 3 3.022 4 2.970 5 3.043 6 3.017 7 2.796 8 2.521 9 2.311 10 2.024 11 1.669 12 1.314 13 0.926
要想一起读取三列,则代码如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None,usecols=[1,2,3]) print(data)
结果如下:
1 2 3 0 4.370 -1.372 0.102 1 3.955 -1.277 0.015 2 3.334 -1.193 0.033 3 3.022 -1.082 0.151 4 2.970 -1.103 -0.048 5 3.043 -1.089 0.011 6 3.017 -1.052 0.066 7 2.796 -0.933 0.002 8 2.521 -0.749 0.011 9 2.311 -0.623 -0.038 10 2.024 -0.452 0.039 11 1.669 -0.277 -0.005 12 1.314 -0.214 0.013 13 0.926 -0.142 0.062
使用data.head(n)返回文件的前n行内容,示例如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data1 = pd.read_csv(filename,index_col=None,header=None) # print(data1) #读取文件的前5行 headdata = data1.head(5) print(headdata)
运行效果,返回前5行所有数据内容:
0 1 2 3 4 5 6 0 0.916 4.370 -1.372 0.102 0.041 0.069 0.018 1 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 2 0.908 3.334 -1.193 0.033 -0.098 -0.059 0.018 3 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 4 1.111 2.970 -1.103 -0.048 -0.175 -0.171 0.019
下面代码表示了函数loc返回了第一行所有列的数据,也就是说第一行的数据:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None) # print(data1) data1 = data.loc[0,:] print(data1)
由此我们可以推断出,某几行-所有列的数据,代码如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None) # print(data1) # 返回第n行所有列的数据 data1 = data.loc[[1,3,5],:] print(data1)
结果展示一下:
0 1 2 3 4 5 6 1 0.892 3.955 -1.277 0.015 -0.099 -0.066 0.018 3 1.013 3.022 -1.082 0.151 0.015 0.035 0.018 5 1.302 3.043 -1.089 0.011 -0.085 -0.097 0.018
获取所有行所有列,直接看代码:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None) # print(data1) # 返回第n行所有列的数据 data1 = data.loc[:,:] print(data1)
结果就是所有行,所有列,这里就不展示了。
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data = pd.read_csv(filename,index_col=None,header=None) # print(data1) # 返回所有列-某行的数据 data1 = data.loc[:,0] print(data1)
运行效果如下:
0 0.916 1 0.892 2 0.908 3 1.013 4 1.111 5 1.302 6 1.552 7 1.832 8 2.127 9 2.354 10 2.537 11 2.639 12 2.707 13 2.810 Name: 0, dtype: float64
describe()统计下数据量,标准值,平均值,最大值等
data.describe()
就拿上面的csv文件为例,读取结果,解析如下:
import pandas as pd filename = r‘Train_A/Train_A_001.csv‘ data1 = pd.read_csv(filename,index_col=None,header=None) # print(data1) print(data1.describe())
结果如下:
0 1 ... 5 6 count 14.000000 14.000000 ... 14.000000 14.000000 mean 1.764286 2.662286 ... -0.030643 0.018643 std 0.748950 0.957612 ... 0.063172 0.000497 min 0.892000 0.926000 ... -0.171000 0.018000 25% 1.037500 2.095750 ... -0.064250 0.018000 50% 1.692000 2.883000 ... -0.029000 0.019000 75% 2.491250 3.037750 ... 0.022000 0.019000 max 2.810000 4.370000 ... 0.069000 0.019000 [8 rows x 7 columns]
既然了解了pandas,以后也需要使用,那么我就不止想学习读取csv了,我还想学习基本的pandas数据结构,起码以后使用会知道一些,下面学习一下pandas其的基本数据结构。
pandas是基于Numpy的一个非常好用的库,正如名字一样,人见人爱,之所以如下,就在于不论是读取,处理数据,使用它都非常简单。
pandas有两种自己独有的基本数据结构,即使如此,但是它依然只是Python的一个库,所以Python中有的数据类型在这里依然使用,同样还可以使用类自己定义的数据类型,只不过,pandas里面又定义了两种数据类型:Series和DataFrame。
series就如同列表一样,一系列数据,每个数据对应于一个索引值,比如这样一个列表:[9,3,8],如果跟索引值写到一起,就是这样:
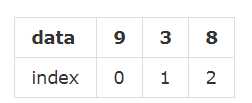
这种样式我们已经熟悉了,不过有些时候,需要将其竖起来表示:
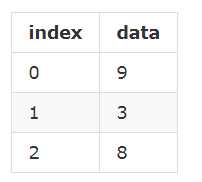
上面两种,只是表现形式上的差别罢了。
Series就是“竖起来”的列表。举个例子:
import pandas as pd s = pd.Series([1,2,3,‘python‘]) s 0 1 1 2 2 3 3 python dtype: object
另外一点也很像列表,就是里面的元素的类型,由我们任意决定。
这里,我们实质上创建了一个Series对象,这个对象当然就有其属性和方法了,比如下面两个属性依次可以显示Series对象的数据值和索引:
s.values array([1, 2, 3, ‘python‘], dtype=object) s.index RangeIndex(start=0, stop=4, step=1)
由于列表的索引只能是从0开始的整数,Series数据类型在默认情况下,其索引也是如次,不过区别于列表的是,Series可以自定义索引:
s = pd.Series([‘java‘,‘python‘],index=[‘1‘,‘2‘]) s 1 java 2 python dtype: object
自定义索引之后,我们就可以根据索引操作元素,series也可以学习list操作:
s[‘1‘] ‘java‘
当然了,前面定义Series对象的是,用的是列表,即 Series() 方法的参数中,第一个列表就是其数据值,如果需要定义 index,放在后面,依然是一个列表。除了这种方法之外,还可以用下面的方法定义 Series 对象:
s = {‘python‘:800,‘java‘:600,‘c++‘:1000}
s = pd.Series(s)
s
python 800
java 600
c++ 1000
dtype: int64
这样的话,索引依然可以自定义,pandas的优势就在这里体现出来,如果自定义了索引,自定的索引会自动寻找原来的索引,如果一样的话,就取代原来索引对应的值,这个可以简称为“自动对齐”,我们举例说明:
s = pd.Series(s,index=[‘python‘,‘java‘,‘c‘,‘c++‘]) s python 800.0 java 600.0 c NaN c++ 1000.0 dtype: float64
在里面,没有c,但是索引参数中有,于是其他能够“自动对齐”的照搬原值,依然可以在新的Series对象的索引中存在,并且可以自动为其赋值NaN,如果pandas中没有值,都对齐赋值给NaN,下面来一个更特殊的:
ilist = [‘a‘,‘b‘,‘c‘] s = pd.Series(s,index=ilist) s a NaN b NaN c NaN dtype: float64
这样的话,新得到的Series对象索引与s对象的值一个也不对应,所以都是NaN。pandas有专门的方法来判断值是否为空。
pd.isnull(s) a True b True c True dtype: bool
也可以判断不为空:
pd.notnull(s) a False b False c False dtype: bool
当然了,也可以对索引的名字,重新定义:
s = [1,2,3,4] s = pd.Series(s,index=[‘python‘,‘java‘,‘c‘,‘c++‘]) s python 1 java 2 c 3 c++ 4 dtype: int64 s.index = [‘a‘,‘b‘,‘c‘,‘d‘] s a 1 b 2 c 3 d 4 dtype: int64
DataFrame是一个表格型的数据结构,它含有一组有序的列,每类可以是不同的值类型(数值,字符串,布尔值)。DataFrame既有行索引也有列索引,它可以被看做由Series组成的字典(共同使用同一个索引)。跟其他类似的数据结构相比(如R的data.frame)DataFrame中面向行和面向列的操作基本上是平衡的,其实DataFrame中的数据是以一个或者多个二维块存放的(而不是列表,字典或者其他一维数据结构)。
DataFrame 是一种二维的数据结构,非常接近于电子表格或者类似 mysql 数据库的形式。它的竖行称之为 columns,横行跟前面的 Series 一样,称之为 index,也就是说可以通过 columns 和 index 来确定一个主句的位置。(有人把 DataFrame 翻译为“数据框”,是不是还可以称之为“筐”呢?向里面装数据嘛。)

首先给一个例子:
>>> import pandas as pd
>>> from pandas import Series, DataFrame
>>> data = {"name":["yahoo","google","facebook"], "marks":
[200,400,800], "price":[9, 3, 7]}
>>> f1 = DataFrame(data)
>>> f1
marks name price
0 200 yahoo 9
1 400 google 3
2 800 facebook 7
这是定义一个 DataFrame 对象的常用方法——使用 dict 定义。字典的“键”("name","marks","price")就是 DataFrame 的 columns 的值(名称),字典中每个“键”的“值”是一个列表,它们就是那一竖列中的具体填充数据。上面的定义中没有确定索引,所以,按照惯例(Series 中已经形成的惯例)就是从 0 开始的整数。从上面的结果中很明显表示出来,这就是一个二维的数据结构(类似 excel 或者 mysql 中的查看效果)。
上面的数据显示中,columns 的顺序没有规定,就如同字典中键的顺序一样,但是在 DataFrame 中,columns 跟字典键相比,有一个明显不同,就是其顺序可以被规定,向下面这样做:
>>> f2 = DataFrame(data, columns=[‘name‘,‘price‘,‘marks‘])
>>> f2
name price marks
0 yahoo 9 200
1 google 3 400
2 facebook 7 800
跟Series类似的,DataFrame数据的索引也可以自定义:
>>> f3 = DataFrame(data, columns=[‘name‘, ‘price‘, ‘marks‘, ‘debt‘], index=[‘a‘,‘b‘,‘c‘])
>>> f3
name price marks debt
a yahoo 9 200 NaN
b google 3 400 NaN
c facebook 7 800 NaN
大家还要注意观察上面的显示结果。因为在定义 f3 的时候,columns 的参数中,比以往多了一项(‘debt‘),但是这项在 data 这个字典中并没有,所以 debt 这一竖列的值都是空的,在 Pandas 中,空就用 NaN 来代表了。
定义 DataFrame 的方法,除了上面的之外,还可以使用“字典套字典”的方式。
>>> newdata = {"lang":{"firstline":"python","secondline":"java"}, "price":{"firstline":8000}}
>>> f4 = DataFrame(newdata)
>>> f4
lang price
firstline python 8000
secondline java NaN
在字典中就规定好数列名称(第一层键)和每横行索引(第二层字典键)以及对应的数据(第二层字典值),也就是在字典中规定好了每个数据格子中的数据,没有规定的都是空。
>>> DataFrame(newdata, index=["firstline","secondline","thirdline"])
lang price
firstline python 8000
secondline java NaN
thirdline NaN NaN
如果额外确定了索引,就如同上面显示一样,除非在字典中有相应的索引内容,否则都是 NaN。
前面定义了 DataFrame 数据(可以通过两种方法),它也是一种对象类型,比如变量 f3 引用了一个对象,它的类型是 DataFrame。承接以前的思维方法:对象有属性和方法。
>>> f3.columns Index([‘name‘, ‘price‘, ‘marks‘, ‘debt‘], dtype=object)
DataFrame 对象的 columns 属性,能够显示素有的 columns 名称。并且,还能用下面类似字典的方式,得到某竖列的全部内容(当然包含索引):
>>> f3[‘name‘] a yahoo b google c facebook Name: name
这是什么?这其实就是一个 Series,或者说,可以将 DataFrame 理解为是有一个一个的 Series 组成的。
一直耿耿于怀没有数值的那一列,下面的操作是统一给那一列赋值:
>>> f3[‘debt‘] = 89.2
>>> f3
name price marks debt
a yahoo 9 200 89.2
b google 3 400 89.2
c facebook 7 800 89.2
除了能够统一赋值之外,还能够“点对点”添加数值,结合前面的 Series,既然 DataFrame 对象的每竖列都是一个 Series 对象,那么可以先定义一个 Series 对象,然后把它放到 DataFrame 对象中。如下:
>>> sdebt = Series([2.2, 3.3], index=["a","c"]) #注意索引 >>> f3[‘debt‘] = sdebt
将 Series 对象(sdebt 变量所引用) 赋给 f3[‘debt‘]列,Pandas 的一个重要特性——自动对齐——在这里起做用了,在 Series 中,只有两个索引("a","c"),它们将和 DataFrame 中的索引自动对齐。于是乎:
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 7 800 3.3
自动对齐之后,没有被复制的依然保持 NaN。
还可以更精准的修改数据吗?当然可以,完全仿照字典的操作:
>>> f3["price"]["c"]= 300
>>> f3
name price marks debt
a yahoo 9 200 2.2
b google 3 400 NaN
c facebook 300 800 3.3
此外,在学习的时候,我参考了别人的知乎内容,并查看官网,然后汇总了pandas官网中比较常用的函数和方法,以方便自己记忆。其实这个比较全面的概括了pandas的所有知识点,只不过没有举例子,但是要是认真看了我上面的两个大的例子,学习下面的知识点,根本不费吹灰之力。
首先,我们使用如下的缩写:
df:任意的Pandas DataFrame对象 s:任意的Pandas Series对象
同时导入pandas包和numpy包
import pandas as pd import numpy as np
当看到np和pd的时候,我们就知道其是什么含义(这些缩写都是大家默认的)。
原文:
pd.read_csv(filename) | From a CSV file pd.read_table(filename) | From a delimited text file (like TSV) pd.read_excel(filename) | From an Excel file pd.read_sql(query, connection_object) | Read from a SQL table/database pd.read_json(json_string) | Read from a JSON formatted string, URL or file. pd.read_html(url) | Parses an html URL, string or file and extracts tables to a list of dataframes pd.read_clipboard() | Takes the contents of your clipboard and passes it to read_table() pd.DataFrame(dict) | From a dict, keys for columns names, values for data as lists
原文:
df.to_csv(filename) | Write to a CSV file df.to_excel(filename) | Write to an Excel file df.to_sql(table_name, connection_object) | Write to a SQL table df.to_json(filename) | Write to a file in JSON format
原文:
pd.DataFrame(np.random.rand(20,5)) | 5 columns and 20 rows of random floats pd.Series(my_list) | Create a series from an iterable my_list df.index = pd.date_range(‘1900/1/30‘, periods=df.shape[0]) | Add a date index
原文:
df.head(n) | First n rows of the DataFrame df.tail(n) | Last n rows of the DataFrame df.shape | Number of rows and columns df.info() | Index, Datatype and Memory information df.describe() | Summary statistics for numerical columns s.value_counts(dropna=False) | View unique values and counts df.apply(pd.Series.value_counts) | Unique values and counts for all columns
原文:
df[col] | Returns column with label col as Series df[[col1, col2]] | Returns columns as a new DataFrame s.iloc[0] | Selection by position s.loc[‘index_one‘] | Selection by index df.iloc[0,:] | First row df.iloc[0,0] | First element of first column
原文:
df.columns = [‘a‘,‘b‘,‘c‘] | Rename columns
pd.isnull() | Checks for null Values, Returns Boolean Arrray
pd.notnull() | Opposite of pd.isnull()
df.dropna() | Drop all rows that contain null values
df.dropna(axis=1) | Drop all columns that contain null values
df.dropna(axis=1,thresh=n) | Drop all rows have have less than n non null values
df.fillna(x) | Replace all null values with x
s.fillna(s.mean()) | Replace all null values with the mean (mean can be replaced with almost any function from the statistics section)
s.astype(float) | Convert the datatype of the series to float
s.replace(1,‘one‘) | Replace all values equal to 1 with ‘one‘
s.replace([1,3],[‘one‘,‘three‘]) | Replace all 1 with ‘one‘ and 3 with ‘three‘
df.rename(columns=lambda x: x + 1) | Mass renaming of columns
df.rename(columns={‘old_name‘: ‘new_ name‘}) | Selective renaming
df.set_index(‘column_one‘) | Change the index
df.rename(index=lambda x: x + 1) | Mass renaming of index
原文:
df[df[col] > 0.5] | Rows where the column col is greater than 0.5 df[(df[col] > 0.5) & (df[col] < 0.7)] | Rows where 0.7 > col > 0.5 df.sort_values(col1) | Sort values by col1 in ascending order df.sort_values(col2,ascending=False) | Sort values by col2 in descending order df.sort_values([col1,col2],ascending=[True,False]) | Sort values by col1 in ascending order then col2 in descending order df.groupby(col) | Returns a groupby object for values from one column df.groupby([col1,col2]) | Returns groupby object for values from multiple columns df.groupby(col1)[col2] | Returns the mean of the values in col2, grouped by the values in col1 (mean can be replaced with almost any function from the statistics section) df.pivot_table(index=col1,values=[col2,col3],aggfunc=mean) | Create a pivot table that groups by col1 and calculates the mean of col2 and col3 df.groupby(col1).agg(np.mean) | Find the average across all columns for every unique col1 group df.apply(np.mean) | Apply the function np.mean() across each column nf.apply(np.max,axis=1) | Apply the function np.max() across each row
原文:
df1.append(df2) | Add the rows in df1 to the end of df2 (columns should be identical) pd.concat([df1, df2],axis=1) | Add the columns in df1 to the end of df2 (rows should be identical) df1.join(df2,on=col1,how=‘inner‘) | SQL-style join the columns in df1 with the columns on df2 where the rows for col have identical values. how can be one of ‘left‘, ‘right‘, ‘outer‘, ‘inner‘
原文:
df.describe() | Summary statistics for numerical columns df.mean() | Returns the mean of all columns df.corr() | Returns the correlation between columns in a DataFrame df.count() | Returns the number of non-null values in each DataFrame column df.max() | Returns the highest value in each column df.min() | Returns the lowest value in each column df.median() | Returns the median of each column df.std() | Returns the standard deviation of each column
参考http://wiki.jikexueyuan.com/project/start-learning-python/311.html
https://zhuanlan.zhihu.com/p/25630700
https://www.dataquest.io/blog/pandas-cheat-sheet/
原文:https://www.cnblogs.com/wj-1314/p/9997131.html