
使用Keras训练具有多个GPU的深度神经网络(照片来源:Nor-Tech.com)。
Keras 无疑是我最喜欢的深度学习+ Python框架,尤其适用于图像分类。
我在生产应用程序,个人深度学习项目以及PyImageSearch博客中使用Keras。
我甚至将我的新书“ 深度学习计算机视觉与基于Keras的Python”的三分之二用于我。
然而,我与Keras最大的困难之一是执行多GPU培训可能会很痛苦。在样板代码和配置TensorFlow之间,它可能是一个过程......
......但现在不行了。
随着Keras(v2.0.9)的最新提交和发布,现在使用多个GPU训练深度神经网络非常容易。
事实上,它就像单个函数调用一样简单!
要了解有关使用Keras,Python和多个GPU训练深度神经网络的更多信息,请继续阅读。
当我第一次开始使用Keras时,我爱上了API。它简单而优雅,类似于scikit-learn。然而它非常强大,能够实施和训练最先进的深度神经网络。
然而,我对Keras的最大挫折之一是在多GPU环境中使用它可能有点不重要。
如果您使用Theano,请忘掉它 - 多GPU培训不会发生。
TensorFlow是一种可能性,但它可能需要大量的样板代码和调整才能使您的网络使用多个GPU进行训练。
我更喜欢在执行多GPU培训时使用mxnet后端(甚至是mxnet库直接)到Keras,但这引入了更多的配置来处理。
所有这一切都与改变弗朗索瓦CHOLLET宣布,使用TensorFlow后端多GPU的支持,现在在烤到Keras V2.0.9。大部分功劳归功于@ kuza55和他们的keras-extras回购。
我已经使用并测试了这个多GPU功能已近一年了,我非常高兴看到它作为官方Keras发行版的一部分。
在今天博客文章的剩余部分中,我将演示如何使用Keras,Python和深度学习训练卷积神经网络进行图像分类。
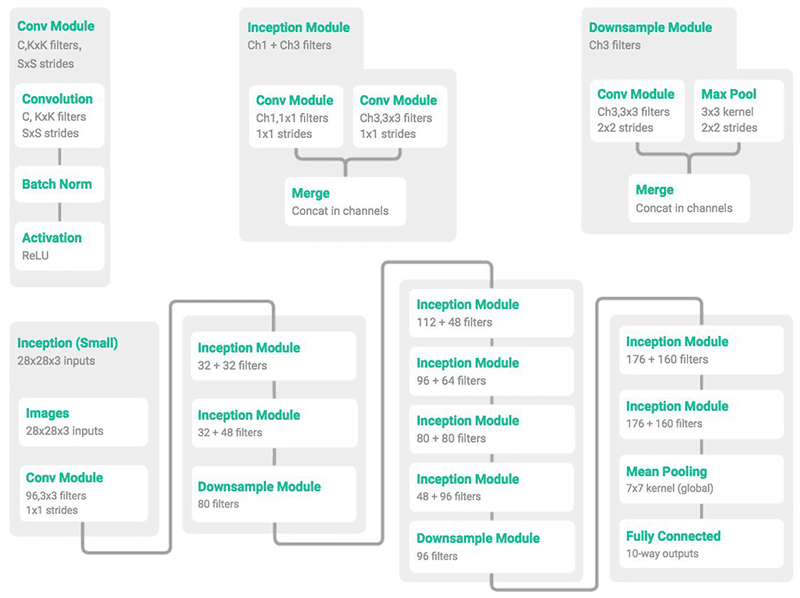
图1: MiniGoogLeNet架构是它的大兄弟GoogLeNet / Inception的一个小版本。图片来自@ ericjang11和@pluskid。
在上面的图1中,我们可以看到单个卷积(左),初始(中)和下采样(右)模块,然后是从这些构建块构建的整体MiniGoogLeNet架构(底部)。我们将在本文后面的多GPU实验中使用MiniGoogLeNet架构。
MiniGoogLenet中的Inception模块是Szegedy等人设计的原始Inception模块的变体。
我首先从@ ericjang11和@pluskid的推文中了解了这个“Miniception”模块,它们可以很好地可视化模块和相关的MiniGoogLeNet架构。
在做了一些研究后,我发现这张图片来自张等人的2017年出版物“ 理解深度学习需要重新思考泛化”。
然后我开始在Keras + Python中实现MiniGoogLeNet架构 - 我甚至将它作为使用Python进行计算机视觉深度学习的一部分。
对MiniGoogLeNet Keras实现的全面审查超出了本博文的范围,因此如果您对网络的工作原理(以及如何编码)感兴趣,请参阅我的书。
否则,您可以使用此博客文章底部的“下载”部分下载源代码。
让我们继续使用Keras和多个GPU开始培训深度学习网络。
首先,您需要确保 在虚拟环境中安装和更新Keras 2.0.9(或更高版本)(我们 在本书中使用名为dl4cv的虚拟环境 ):
1 2 | $ workon dl4cv $ pip install --upgrade keras |
从那里,打开一个新文件,将其命名为 train .py ,并插入以下代码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 | # set the matplotlib backend so figures can be saved in the background # (uncomment the lines below if you are using a headless server) # import matplotlib # matplotlib.use("Agg") # import the necessary packages from pyimagesearch.minigooglenet import MiniGoogLeNet from sklearn.preprocessing import LabelBinarizer from keras.preprocessing.image import ImageDataGenerator from keras.callbacks import LearningRateScheduler from keras.utils.training_utils import multi_gpu_model from keras.optimizers import SGD from keras.datasets import cifar10 import matplotlib.pyplot as plt import tensorflow as tf import numpy as np import argparse |
如果您使用的是无头服务器,则需要通过取消注释行来配置第3行和第4行的matplotlib后端。这样可以将matplotlib图保存到磁盘。如果您没有使用无头服务器(即,您的键盘+鼠标+显示器已插入系统,则可以将线条注释掉)。
从那里我们导入这个脚本所需的包。
第7行从我的pyimagesearch 模块导入MiniGoogLeNet (包含在“下载”部分中提供的下载)。
另一个值得注意的导入是在 第13行,我们导入CIFAR10数据集。这个辅助函数将使我们能够只用一行代码从磁盘加载CIFAR-10数据集。
现在让我们解析命令行参数:
19 20 21 22 23 24 25 26 27 28 | # construct the argument parse and parse the arguments ap = argparse.ArgumentParser() ap.add_argument("-o", "--output", required=True, help="path to output plot") ap.add_argument("-g", "--gpus", type=int, default=1, help="# of GPUs to use for training") args = vars(ap.parse_args()) # grab the number of GPUs and store it in a conveience variable G = args["gpus"] |
我们使用 argparse 解析一个需要和一个可选的参数线20-25:
加载命令行参数后, 为方便起见,我们将GPU的数量存储为 G(第28行)。
从那里,我们初始化用于配置我们的训练过程的两个重要变量,然后定义 poly_decay ,一个等同于Caffe的多项式学习速率衰减的学习速率调度函数:
30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 | # definine the total number of epochs to train for along with the # initial learning rate NUM_EPOCHS = 70 INIT_LR = 5e-3 def poly_decay(epoch): # initialize the maximum number of epochs, base learning rate, # and power of the polynomial maxEpochs = NUM_EPOCHS baseLR = INIT_LR power = 1.0 # compute the new learning rate based on polynomial decay alpha = baseLR * (1 - (epoch / float(maxEpochs))) ** power # return the new learning rate return alpha |
我们设置 NUM _ EPOCHS = 70 - 这是我们的训练数据将通过网络的次数(时期)(第32行)。
我们还初始化学习率 INIT_LR = 5e - 3 ,这是在之前的试验(第33行)中通过实验发现的值。
从那里,我们定义 poly_decay 函数,它相当于Caffe的多项式学习速率衰减(第35-46行)。本质上,此功能可在训练期间更新学习速率,并在每个时期后有效地减少学习速度。设置 功率= 1.0 会将衰减从多项式更改为线性。
接下来我们将加载我们的训练+测试数据并将图像数据从整数转换为浮点数:
48 49 50 51 52 53 | # load the training and testing data, converting the images from # integers to floats print("[INFO] loading CIFAR-10 data...") ((trainX, trainY), (testX, testY)) = cifar10.load_data() trainX = trainX.astype("float") testX = testX.astype("float") |
从那里我们对数据应用平均减法:
55 56 57 58 | # apply mean subtraction to the data mean = np.mean(trainX, axis=0) trainX -= mean testX -= mean |
在 第56行,我们计算所有训练图像的平均值,然后是 第57和58行,其中我们从训练和测试集中的每个图像中减去平均值。
然后,我们执行“one-hot encoding”,这是我在本书中更详细讨论的编码方案:
60 61 62 63 | # convert the labels from integers to vectors lb = LabelBinarizer() trainY = lb.fit_transform(trainY) testY = lb.transform(testY) |
单热编码将分类标签从单个整数转换为向量,因此我们可以应用分类交叉熵损失函数。我们已经在第61-63行处理了这个问题 。
接下来,我们创建一个数据增强器和一组回调:
65 66 67 68 69 70 | # construct the image generator for data augmentation and construct # the set of callbacks aug = ImageDataGenerator(width_shift_range=0.1, height_shift_range=0.1, horizontal_flip=True, fill_mode="nearest") callbacks = [LearningRateScheduler(poly_decay)] |
在67-69行,我们构建了用于数据增强的图像生成器。
数据增强覆盖在里面详细执业捆绑的深度学习计算机视觉与Python ; 然而,暂时理解这是一种在训练过程中使用的方法,我们通过对它们进行随机变换来随机改变训练图像。
由于这些改变,网络不断地看到增强的示例 - 这使得网络能够更好地概括验证数据,同时可能在训练集上表现更差。在大多数情况下,这些权衡是值得的。
我们在第70行创建了一个回调函数, 它允许我们的学习率在每个时代之后衰减 - 注意我们的函数名称 poly_decay 。
我们接下来检查GPU变量:
72 73 74 75 76 | # check to see if we are compiling using just a single GPU if G <= 1: print("[INFO] training with 1 GPU...") model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10) |
如果GPU计数小于或等于1,我们 通过使用 初始化 模型。构建 函数(第73-76行),否则我们将在训练期间并行化模型:
78 79 80 81 82 83 84 85 86 87 88 89 90 | # otherwise, we are compiling using multiple GPUs else: print("[INFO] training with {} GPUs...".format(G)) # we‘ll store a copy of the model on *every* GPU and then combine # the results from the gradient updates on the CPU with tf.device("/cpu:0"): # initialize the model model = MiniGoogLeNet.build(width=32, height=32, depth=3, classes=10) # make the model parallel model = multi_gpu_model(model, gpus=G) |
在Keras中创建一个多GPU模型需要一些额外的代码,但不多!
首先,您将在第84行注意到我们已指定使用CPU(而不是GPU)作为网络上下文。
为什么我们需要CPU?
好吧,CPU负责处理任何开销(例如在GPU内存上移动和移动训练图像),而GPU本身则负担繁重。
在这种情况下,CPU实例化基本模型。
然后我们可以 在第90行调用 multi_gpu_model。此功能将模型从CPU复制到我们所有的GPU,从而获得单机,多GPU数据并行性。
在训练我们的网络时,图像将被批量分配到每个GPU。CPU将从每个GPU获得梯度,然后执行梯度更新步骤。
然后我们可以编译我们的模型并启动培训过程:
92 93 94 95 96 97 98 99 100 101 102 103 104 105 | # initialize the optimizer and model print("[INFO] compiling model...") opt = SGD(lr=INIT_LR, momentum=0.9) model.compile(loss="categorical_crossentropy", optimizer=opt, metrics=["accuracy"]) # train the network print("[INFO] training network...") H = model.fit_generator( aug.flow(trainX, trainY, batch_size=64 * G), validation_data=(testX, testY), steps_per_epoch=len(trainX) // (64 * G), epochs=NUM_EPOCHS, callbacks=callbacks, verbose=2) |
在 第94行,我们构建了一个随机梯度下降(SGD)优化器。
随后,我们使用SGD优化器和分类的交叉熵损失函数编译模型。
我们现在准备训练网络了!
为了启动培训过程,我们打电话给 模型。fit_generator 并提供必要的参数。
我们希望每个GPU上的批量大小为64,因此由batch_size = 64 * G 指定 。
我们的培训将持续70个时期(我们之前指定)。
梯度更新的结果将在CPU上组合,然后在整个训练过程中应用于每个GPU。
现在培训和测试已经完成,让我们绘制损失/准确度,以便我们可以看到培训过程:
107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 | # grab the history object dictionary H = H.history # plot the training loss and accuracy N = np.arange(0, len(H["loss"])) plt.style.use("ggplot") plt.figure() plt.plot(N, H["loss"], label="train_loss") plt.plot(N, H["val_loss"], label="test_loss") plt.plot(N, H["acc"], label="train_acc") plt.plot(N, H["val_acc"], label="test_acc") plt.title("MiniGoogLeNet on CIFAR-10") plt.xlabel("Epoch #") plt.ylabel("Loss/Accuracy") plt.legend() # save the figure plt.savefig(args["output"]) plt.close() |
最后一个块仅使用matplotlib绘制训练/测试损失和准确度(第112-121行),然后将数字保存到磁盘(第124行)。
如果您想了解有关培训过程(以及内部工作原理)的更多信息,请参阅使用Python进行计算机视觉深度学习。
让我们检查一下我们辛勤工作的结果。
首先,使用本文底部的“下载”部分从本课程中获取代码。然后,您就可以按照结果进行操作
让我们在单个GPU上训练以获得基线:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | $ python train.py --output single_gpu.png [INFO] loading CIFAR-10 data... [INFO] training with 1 GPU... [INFO] compiling model... [INFO] training network... Epoch 1/70 - 64s - loss: 1.4323 - acc: 0.4787 - val_loss: 1.1319 - val_acc: 0.5983 Epoch 2/70 - 63s - loss: 1.0279 - acc: 0.6361 - val_loss: 0.9844 - val_acc: 0.6472 Epoch 3/70 - 63s - loss: 0.8554 - acc: 0.6997 - val_loss: 1.5473 - val_acc: 0.5592 ... Epoch 68/70 - 63s - loss: 0.0343 - acc: 0.9898 - val_loss: 0.3637 - val_acc: 0.9069 Epoch 69/70 - 63s - loss: 0.0348 - acc: 0.9898 - val_loss: 0.3593 - val_acc: 0.9080 Epoch 70/70 - 63s - loss: 0.0340 - acc: 0.9900 - val_loss: 0.3583 - val_acc: 0.9065 Using TensorFlow backend. real 74m10.603s user 131m24.035s sys 11m52.143s |
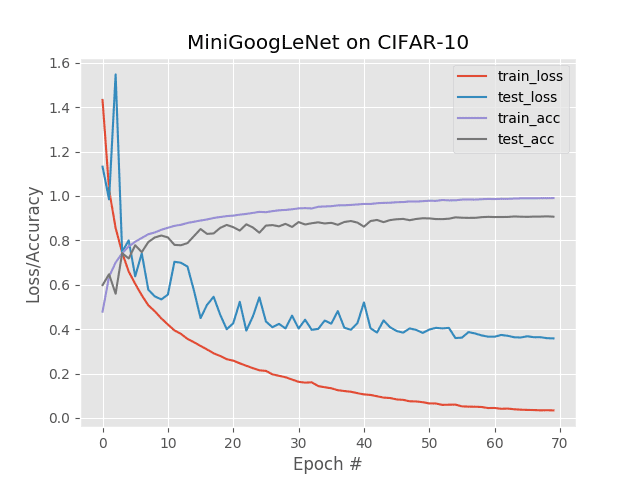
图2:在单个GPU上使用Keras在CIFAR-10上训练和测试MiniGoogLeNet网络架构的实验结果。
对于这个实验,我在我的NVIDIA DevBox上使用单个Titan X GPU进行了训练。每个时期花费约63秒,总训练时间为74分10秒。
然后我执行以下命令来训练 我的所有四个Titan X GPU:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 | $ python train.py --output multi_gpu.png --gpus 4 [INFO] loading CIFAR-10 data... [INFO] training with 4 GPUs... [INFO] compiling model... [INFO] training network... Epoch 1/70 - 21s - loss: 1.6793 - acc: 0.3793 - val_loss: 1.3692 - val_acc: 0.5026 Epoch 2/70 - 16s - loss: 1.2814 - acc: 0.5356 - val_loss: 1.1252 - val_acc: 0.5998 Epoch 3/70 - 16s - loss: 1.1109 - acc: 0.6019 - val_loss: 1.0074 - val_acc: 0.6465 ... Epoch 68/70 - 16s - loss: 0.1615 - acc: 0.9469 - val_loss: 0.3654 - val_acc: 0.8852 Epoch 69/70 - 16s - loss: 0.1605 - acc: 0.9466 - val_loss: 0.3604 - val_acc: 0.8863 Epoch 70/70 - 16s - loss: 0.1569 - acc: 0.9487 - val_loss: 0.3603 - val_acc: 0.8877 Using TensorFlow backend. real 19m3.318s user 104m3.270s sys 7m48.890s |
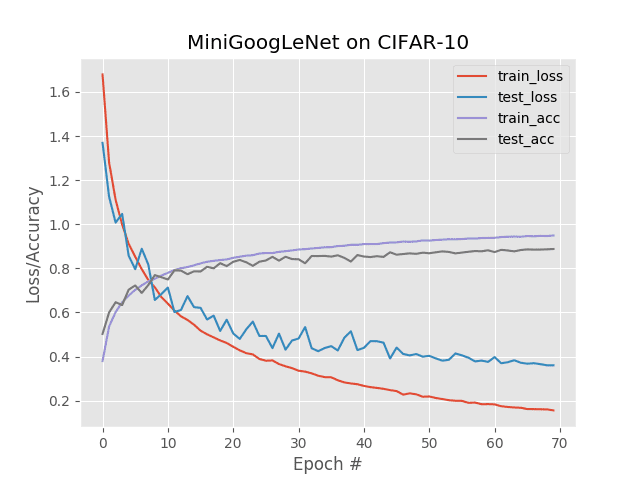
图3:在CIFAR10数据集上使用Keras和MiniGoogLeNet的多GPU培训结果(4个Titan X GPU)。训练结果类似于单GPU实验,而训练时间减少了约75%。
在这里你可以看到训练中的准线性加速:使用四个GPU,我能够将每个时期减少到只有 16秒。整个网络在19分3秒内完成了培训 。
正如您所看到的,不仅可以轻松地训练具有Keras和多个GPU的深度神经网络 ,它也是 高效的!
注意:在这种情况下,单GPU实验获得的精度略高于多GPU实验。在训练任何随机机器学习模型时,会有一些差异。如果你要在数百次运行中平均这些结果,它们将(大致)相同。
在今天的博客文章中,我们学习了如何使用多个GPU来训练基于Keras的深度神经网络。
使用多个GPU使我们能够获得准线性加速。
为了验证这一点,我们在CIFAR-10数据集上训练了MiniGoogLeNet。
使用单个GPU,我们能够获得63秒的时间段,总训练时间为74分10秒。
然而,通过使用Keras和Python的多GPU训练,我们将训练时间减少到16秒,总训练时间为19m3s。
使用Keras启用多GPU培训就像单个函数调用一样简单 - 我建议您尽可能使用多GPU培训。在未来,我想象 multi_gpu_model 将演变,让我们进一步定制专门其中的GPU应该用于训练,最终实现多系统的训练也是如此。
使用Keras进行多GPU训练 multi_gpu_model
原文:https://www.cnblogs.com/jins-note/p/10061694.html