今天学习了梯度提升决策树(Gradient Boosting Decision Tree, GBDT),准备写点东西作为记录。后续,我会用python 实现GBDT, 发布到我的Github上,敬请Star。
梯度提升算法是一种通用的学习算法,除了决策树,还可以使用其它模型作为基学习器。梯度提升算法的思想是通过调整模型,让损失函数的值不断减小, 然后将各个模型加起来作为最终的预测模型。而梯度提升决策树则是以决策树为基学习器。通常,我们认为决策树是没有参数的模型,可以用if-else规则来表达。因此,在理解梯度提升决策树的一个关键点和难点便是梯度!梯度提升体现在哪?决策树不是没有参数吗,如何求梯度?这是我在学习过程中遇到的两个问题。下面会一一解答。
首先,我们来回顾一下机器学习的基础知识。
机器学习算法一个基础知识是损失函数(loss function),损失函数用于指导模型的训练。
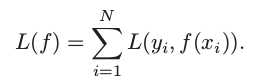
其中的 f 就是我们的模型,梯度提升算法就是根据损失函数对模型的一阶导数(梯度)来对模型进行更新。什么,可以对模型求导数???,等等,别急,没有想像的那么难。
梯度提升决策树(Gradient Boosting Decision Tree),用于分类或回归。
原文:https://www.cnblogs.com/yangkang77/p/9966167.html