网络要做的步骤:(一个中国人,给中国人教学,为什么要写一堆英语?)
1, sample abatch of data(数据抽样)
2,it through the graph ,get loss(前向传播,得到损失值)
3,backprop to calculate the geadiets(反向传播计算梯度)
4,update the paramenters using the gradient(使用梯度更新参数)
卷积神经网络可以做的事情:
分类 取回(推荐)

检测出(同事有分类和回归) 分割

自动驾驶(推荐利用GPU)

特征提取
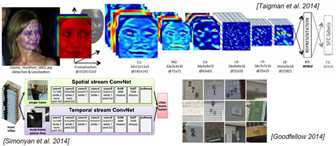
姿势识别(关键点的定位)

癌细胞判别 字体识别 图标识别

图像字幕(让机器读懂世界)CNN+LSTM

style transfer(风格转移)

如何实现?
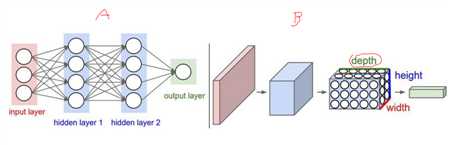
卷积神经网络组成:
[INPUT -CONV -RELU -POOL -FC]
?输入层
?卷积层
?激活函数
?池化层
?全连接层
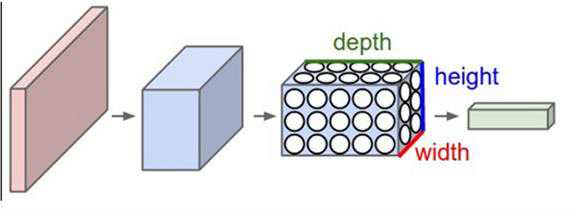
卷积是什么鬼?
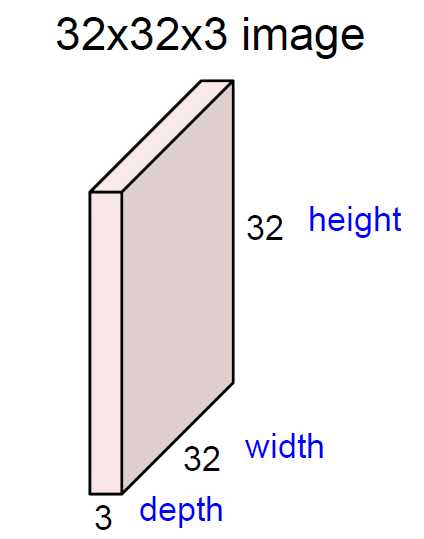
暂时有个小助手,叫做filter,帮我们在32×32×3上提取特征。
如何提取?先从直观上理解卷积到底干了一件什么事,先看二维的:
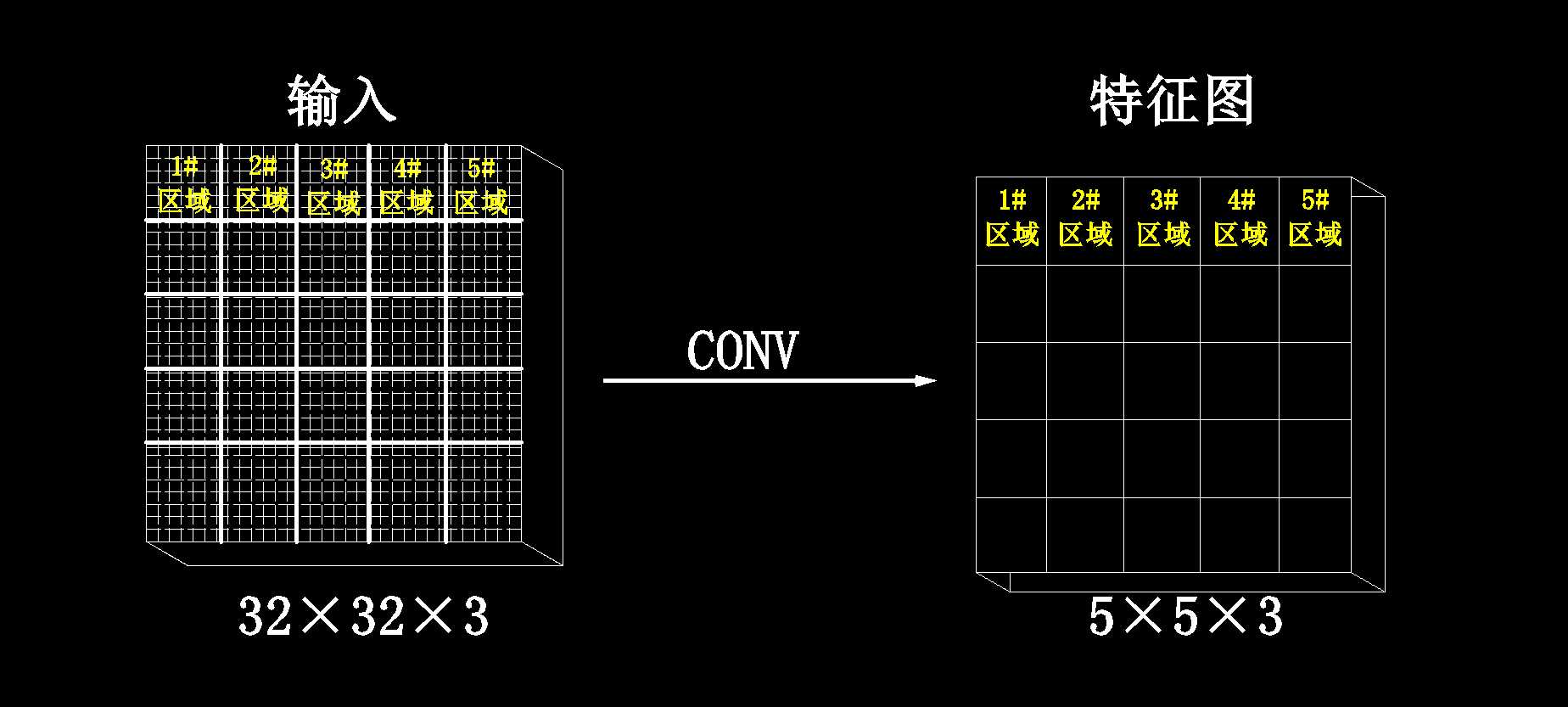
将32×32划分成一些区域,例如划分成好多5×5的区域,那么一个5×5的区域提取出一个特征值
特征值提取出来之后形成5×5的矩阵。
提取出来的叫做特征图
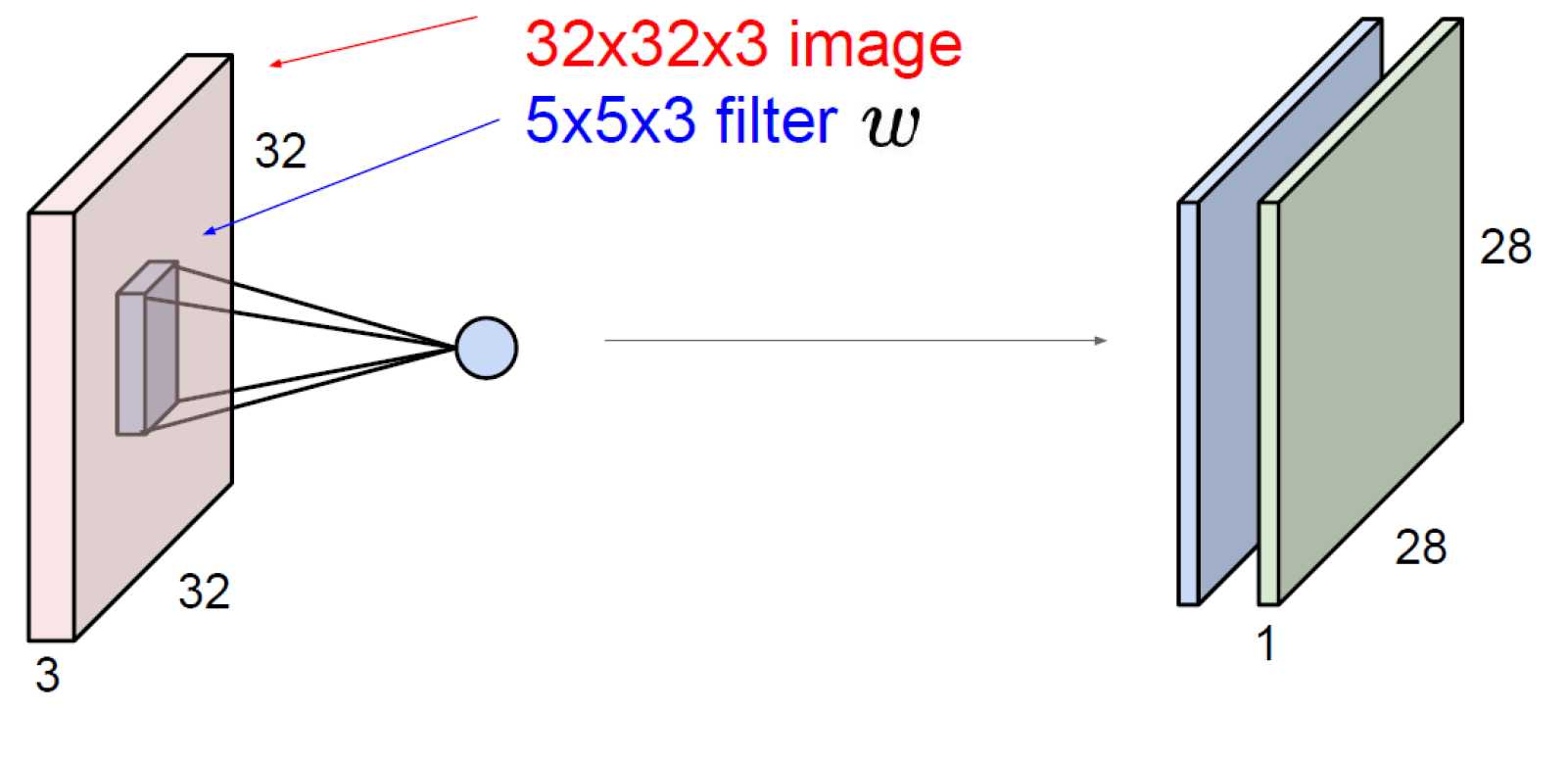
前面少说了一个filter的深度,这里说一下:
filter的深度3,必须要与输入的深度3保持一致才可以。
为什么提取出的特征图是2个?
因为这里设置了filter1和filter2,分别提取出不同的特征,而且这两个特征图没有任何关系。
比如说这个:
有f1,f2,f3,f4,f5,f6
就得到了6层特征图,将这6个特征图堆叠在一起,就会得到卷积的输出结果

多层卷积:
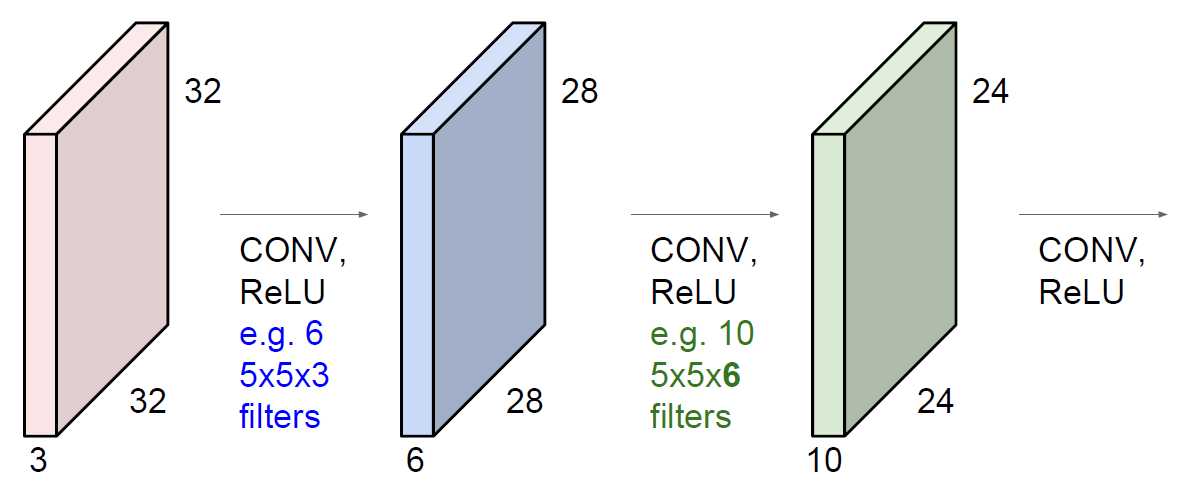
说白了就是将卷积提取完的特征图当做输入,再进行卷积特征提取。
32×32×3用6个5×5×3的filter提取出了28×28×6的特征图,再将这个28×28×6的特征图用10个5×5×6的filter提取出了24×24×10的特征图
卷积提取的结果,大概是怎么样的?
通过输入→卷积→特征→卷积→特征→卷积→特征
相当于一步一步的浓缩,将最后的特征拿来作为分类或者回归的任务。

卷积(特征提取)的具体计算方法:
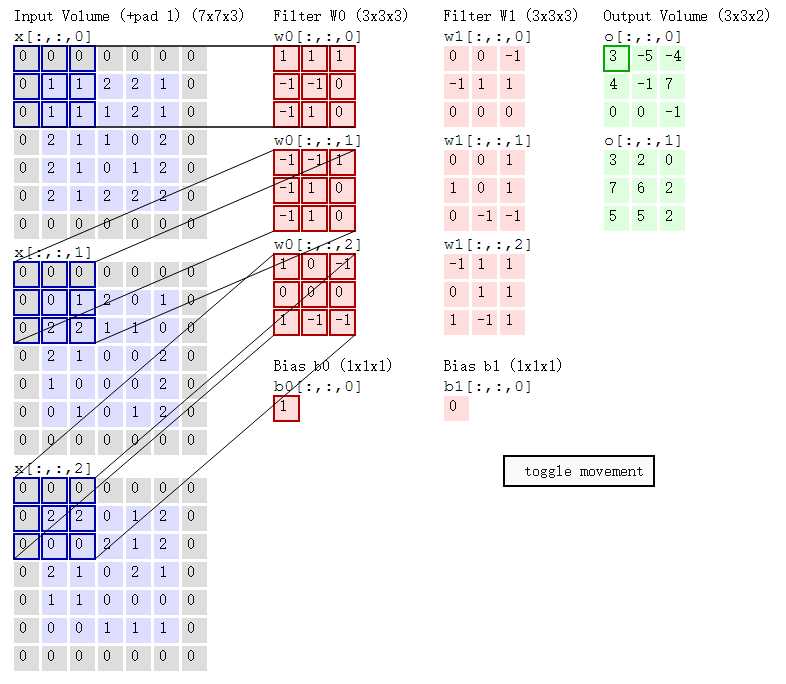
w0与x蓝色区域做内积(对应位置相乘后相加):
f1第1层 = 0×1+ 0×1+ 0×1 + 0×-1+ 1×-1+ 1×0 + 0×-1+1×1+1×0 = 0
f1第2层 = 0×-1+0×-1+0×1 +0×-1+0×1+1×0 +0×-1+2×1+2×0 = 2
f1第3层 = 0×1+0×0+0×-1+ 0×0+2×0+2×0+ 0×1+0×-1+0×-1+ = 0
那么根据神经网络得分函数:f(x,w) = wx+b
这里的b =1
那么输出的得分值就为f1+f2+f3+b = 0+2+0+1 =3
最右边绿色的矩阵第1行,第1列,就是3
第二步:同理计算出特征值的第1行,第2列,得到-5
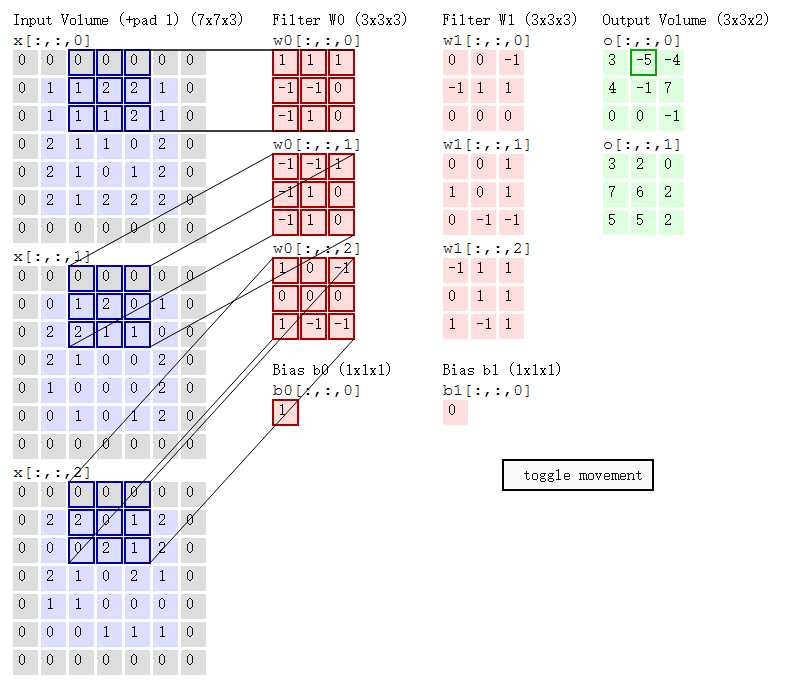
第三部,同理计算出特征值的第1行,第3列,得到-4
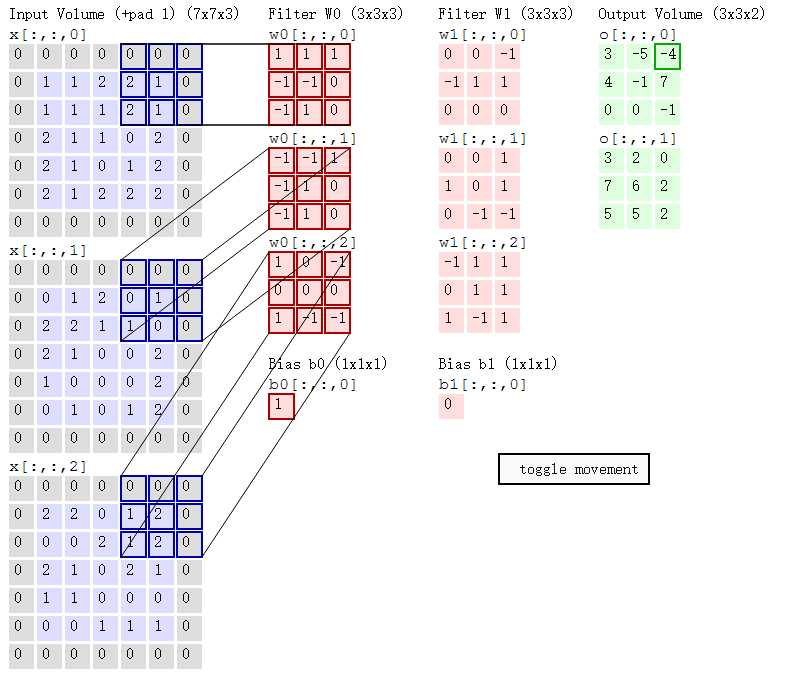
同样大小的filter在输入上向下挪2行,按照1,2,3的步骤继续计算,得到特征矩阵的第2行
再向下挪2行,得到特征矩阵的第3行
同理再得出f2(w1)的特征矩阵,也就是下面绿色的矩阵
卷积核的参数分析:
为什么是挪2格呢?为什么要按照这种方法滑动?
滑动的步长叫做stride
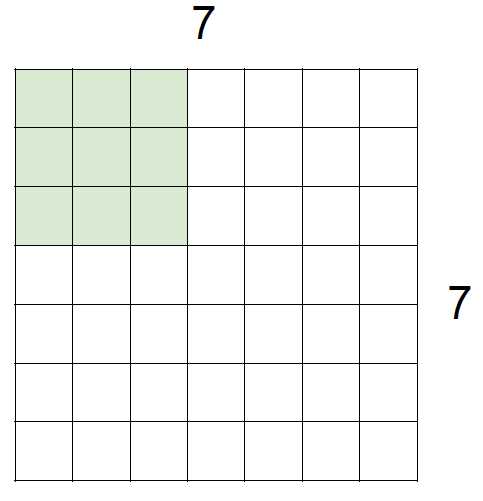
如果输入是7×7的矩阵,stride = 1的时候,每次滑动1格,filter = 3×3
那么最终得到的矩阵是5×5
如果stride = 2,每次滑动2格,filter = 3×3
最终的矩阵是3×3
可见,stride越大,得到的特征图就越小。
我们希望stride比较小,那么我们得到的特征矩阵就会大一些,这样得到的特征就会多一些,
但是,效率与精度之间成反比关系,所以stride不能太大,也不能太小。
pad:
在用卷积提取特征值的时候,里面有一个+pad 1 是个什么东西?
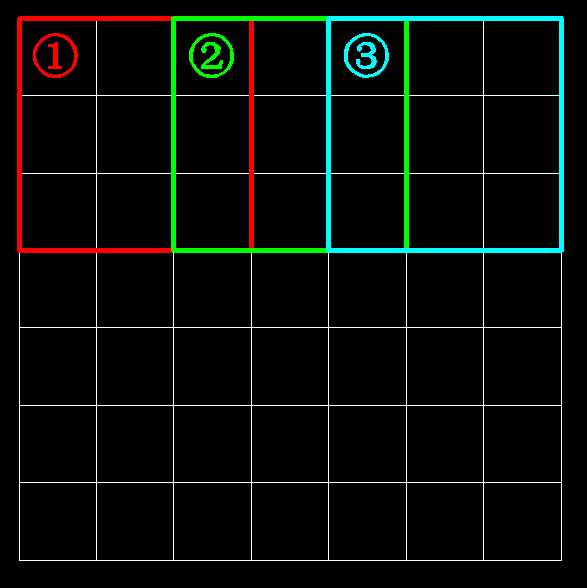
先说一下在7×7用3×3,stride = 2 的卷积核提取特征的时候,
①,②,③号窗口中的①被利用了1次,②被利用了2次,③被利用了2次
也就是说,边缘上元素的利用率低于中间元素的利用率
那么②和③对最终的结果贡献要超过①,如何让①(边缘上的元素)也对最终结果贡献大一些呢?
其实,最初的图像是5×5大小的就像下图 黄色部分
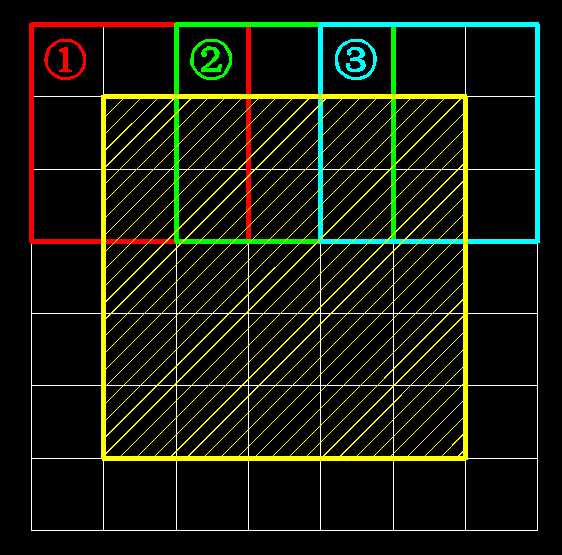
pad的意思就是在原始输入图像的边缘上,加上一圈0
使得边缘上的元素利用率提高一些。
为什么要加0,因为这一圈,不是我们的原始输入,只是让他帮我们把边缘点都利用上,
这些0对网络来说,是一点用都没有的。
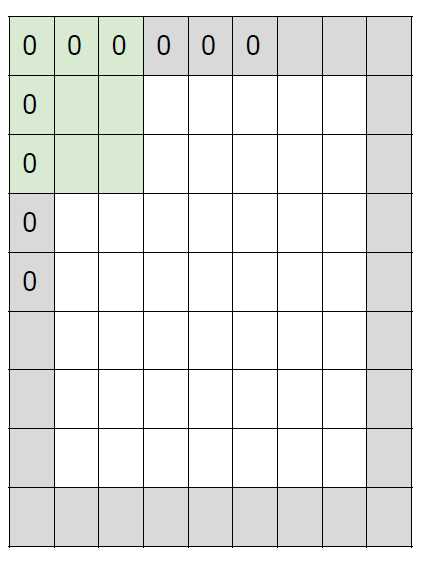
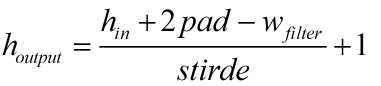
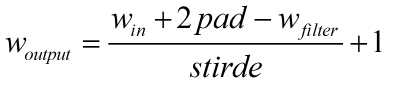
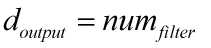
输入= 7 x 7
Filter = 3 x 3
Pad = 1
stride = 1
Output =7×7
举个例子:
所有filter的大小必须一致。
参数共享:
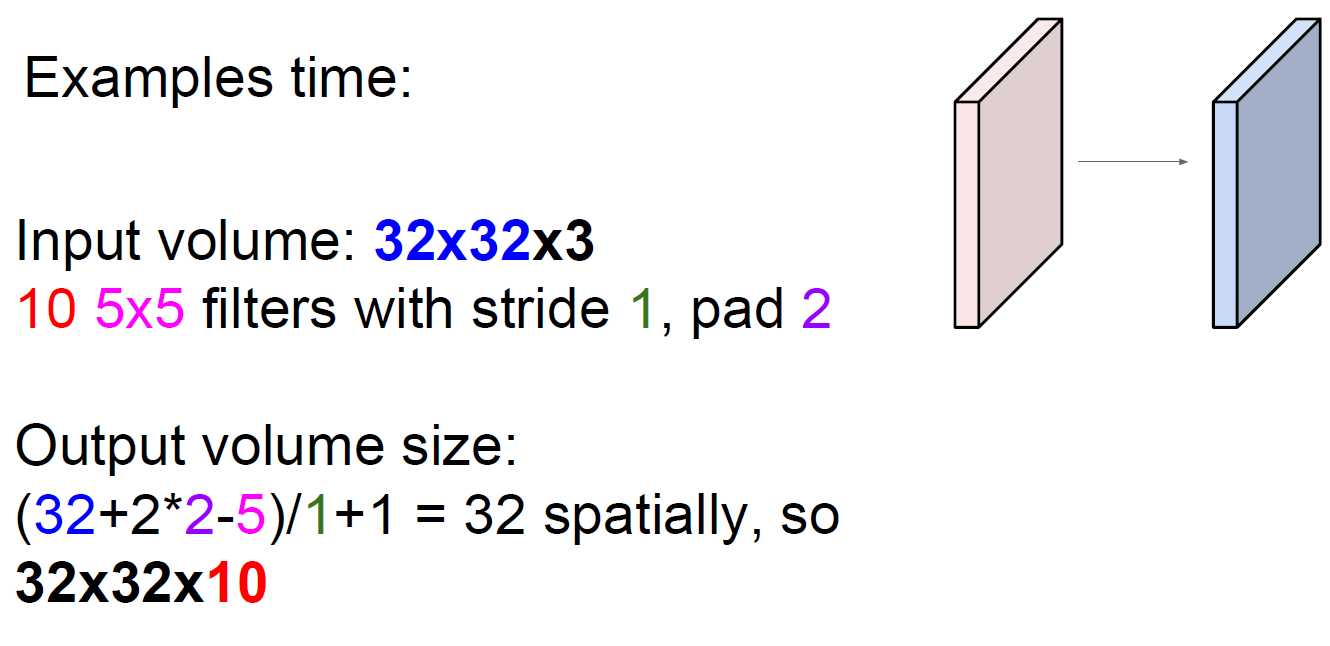
试想一下,如果讲一个输入为32×32×3的矩阵进行卷积特征提取
filter = 5×5,共有10个filter,stride = 1 pad =2那么特征矩阵就是一个
28×28×10的矩阵
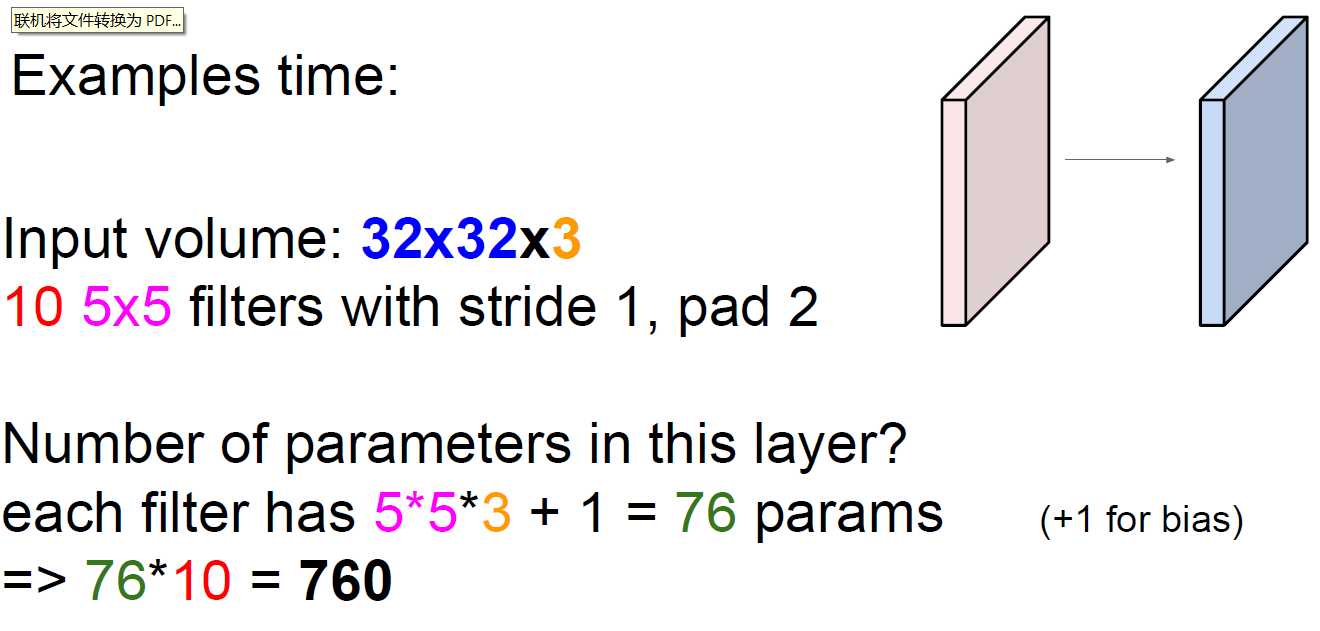
输入一共有32×32×3 = 3072个权重参数,
filter提取特征一共有5×5×10 = 250个权重参数
如果输入层与卷积层全连接的话那么将会有76万个权重参数
对于计算和效率都是一件非常恐怖的事,
如果在输出层上将多有的参数进行共享(相等)的话,
28×28的每一个格子对应32×32中的5×5的一个区域的权重参数都相同的话,那么只需要5×5×3 = 750个参数
在加10个b参数,那么只需要760个参数就可以了。
个人理解:filter在整个提取过程中不变,所以filter的w权重参数也不变,那么特征矩阵对应于输入的w参数就不会变,特征矩阵的所有点都是用同一个权重参数提取的。
总结:
卷积层主要干了一件什么事?说白了就是特征提取,用权重参数提取输入的特征,得到特征矩阵。
原文:https://www.cnblogs.com/Mjerry/p/9796843.html