本文转载自:https://zhuanlan.zhihu.com/p/29212896
我来钱庙复知世依,似我心苦难归久,相须莱共游来愁报远。近王只内蓉者征衣同处,规廷去岂无知草木飘。
你可能以为上面的诗句是某个大诗人所作,事实上上面所有的内容都是循环神经网络写的,是不是感觉很神奇呢?其实这里面的原理非常简单,只需要对循环神经网络有个清楚的理解,那么就能够实现上面的效果,在读完本篇文章之后,大家都能够学会如何使用循环神经网络来创作文本。
Char RNN的原理
在之前的文章中介绍过RNN的基本结构,其非常擅长处理序列问题,那么对于文本而言,其相当于也是一个序列,因为每句话都是由单词或汉字按照顺序组成的,所以也能够使用RNN对其进行处理,但是如何使用RNN进行文本生成呢?其实原理非常简单,下面我们就介绍一下Char RNN。
训练过程
一般而言,RNN的输入和输出存在着多种关系,比如1对多,多对多等等,不同的输入输出关系对应着不同的应用,网上也有很多这方面的文章可以去看看,这里我们要讲的Char RNN在训练网络的时候是相同长度的多对多的类型,也就是输入一个序列,输出一个相同的长度的序列。
具体的网络结构就是下面这个样子
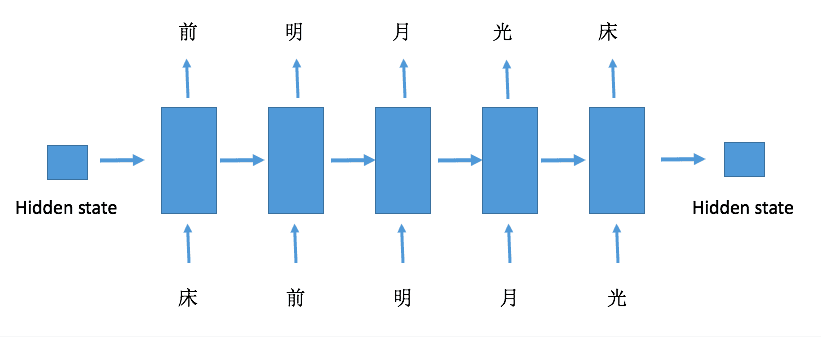
输入一句话作为输入序列,这句话中的每个字符都按照顺序进入RNN,每个字符传入RNN之后都能够得到一个输出,而这个输出就是这个字符在这句话中紧跟其后的一个字符,可以通过上面的图示清晰地看到这一点。这里要注意的是,一个序列最后一个输入对应的输出可以有多种选择,上面的图示是将这个序列的最开始的字符作为其输出,当然也可以将最后一个输入作为输出,以上面的例子说明就是‘光‘的输出就是‘光‘本身。
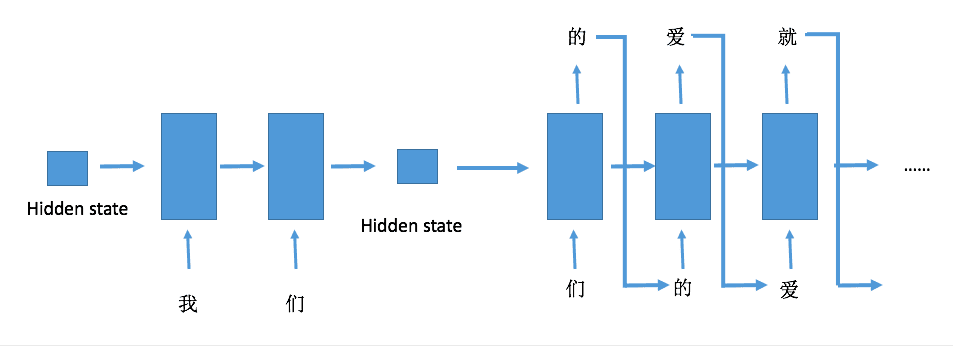
生成文本过程
在预测的时候需要给网络一段初始的序列进行预热,预热的过程并不需要实际的输出结果,只是为了生成具有记忆的隐藏状态,然后将隐藏状态保留,传入之后的网络,不断地更新句子,直到达到要求的输出长度,具体可以看下面的图示
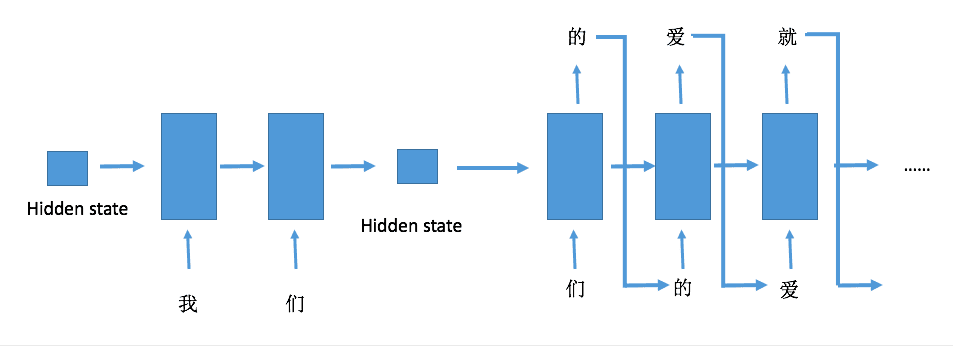
生成文本的过程就是每个字不断输入网络,然后将输出作为下一次的输出,不断循环递归,因为其会不限循环下去,所以可以设置一个长度让其停止。
实现细节
这里我们使用PyToch作为例子进行讲解,同时也提供了MXNet-Gluon的版本,因为他们的语法非常相似,所以实现两个几乎没有太大的区别,如果你不知道Gluon是什么,可以看看之前的一篇文章介绍。同时github也能找到tensorflow的实现。
数据预处理
在进行网络构建之前,需要对数据进行预处理,其实大体的思路很简单,就是建立字符的数字表示,因为字符没有办法直接输入到网络中,所以需要用不同的数字去代表不同的字符,同时可以设定一个最大字符数,如果文本中读取到的所有不重复的字符数超过了这个最大字符数,就按照字符出现的频率截取掉最后的部分。
实现的代码也非常简单
with open(text_path, ‘r‘) as f:
text_file = f.readlines()
word_list = [v for s in text_file for v in s]
vocab = set(word_list)
# 如果单词超过最长限制,则按单词出现频率去掉最小的部分
vocab_count = {}
for word in vocab:
vocab_count[word] = 0
for word in word_list:
vocab_count[word] += 1
vocab_count_list = []
for word in vocab_count:
vocab_count_list.append((word, vocab_count[word]))
vocab_count_list.sort(key=lambda x: x[1], reverse=True)
if len(vocab_count_list) > max_vocab:
vocab_count_list = vocab_count_list[:max_vocab]
vocab = [x[0] for x in vocab_count_list]
self.vocab = vocab
self.word_to_int_table = {c: i for i, c in enumerate(self.vocab)}
self.int_to_word_table = dict(enumerate(self.vocab))
建立好一个字典用于字符和数字的相互转换之后,我们可以使用PyTorch中的Dataset类进行自定义我们的数据集合,只需要重载__getitem__和__len__这两个函数就可以了。
class TextData(data.Dataset):
def __init__(self, text_path, n_step, arr_to_idx):
self.n_step = n_step
with open(text_path, ‘r‘) as f:
data = f.readlines()
text = [v for s in data for v in s]
num_seq = int(len(text) / n_step)
self.num_seq = num_seq
text = text[:num_seq * n_step] # 截去最后不够长的部分
arr = arr_to_idx(text)
arr = arr.reshape((num_seq, -1))
self.arr = torch.from_numpy(arr)
def __getitem__(self, index):
x = self.arr[index, :]
y = torch.zeros(x.size())
y[:-1], y[-1] = x[1:], x[0]
return x, y
def __len__(self):
return self.num_seq
网络定义
处理好数据之后,就可以进行网络的定义了,非常简单,网络只需要定义三层就可以了,第一层是word embedding,也就是词嵌入层,第二层是RNN层,第三层是线性映射,因为最后是一个分类问题,所以将结果的位数隐射到类别数目。
class CharRNN(nn.Module):
def __init__(self, num_classes, embed_dim, hidden_size, num_layers,
dropout):
super(CharRNN, self).__init__()
self.num_layers = num_layers
self.hidden_size = hidden_size
self.word_to_vec = nn.Embedding(num_classes, embed_dim)
self.rnn = nn.GRU(embed_dim, hidden_size, num_layers, dropout)
self.proj = nn.Linear(hidden_size, num_classes)
def forward(self, x, hs=None):
batch = x.size(0)
if hs is None:
hs = Variable(
torch.zeros(self.num_layers, batch, self.hidden_size))
if torch.cuda.is_available():
hs = hs.cuda()
word_embed = self.word_to_vec(x) # batch x len x embed
word_embed = word_embed.permute(1, 0, 2) # len x batch x embed
out, h0 = self.rnn(word_embed, hs) # len x batch x hidden
le, mb, hd = out.size()
out = out.view(le * mb, hd)
out = self.proj(out)
out = out.view(le, mb, -1)
out = out.permute(1, 0, 2).contiguous() # batch x len x hidden
return out.view(-1, out.size(2)),