作业题目链接
队友链接
Fork的同名仓库的Github项目地址
玮哥负责命令参数判断、单词权重统计,我只负责词组词频统计(emmmm)。
| 预估耗时(分钟) | 实际耗时(分钟) | ||
|---|---|---|---|
| Planning | 计划 | ||
| Estimate | 估计这个任务需要多少时间 | 880 | 1170 |
| Development | 开发 | ||
| Analysis | 需求分析 (包括学习新技术) | 100 | 120 |
| Design Spec | 生成设计文档 | 20 | 10 |
| Design Review | 设计复审 | 10 | 10 |
| Coding Standard | 代码规范 | 20 | 60 |
| Design | 具体设计 | 60 | 100 |
| Coding | 具体编码 | 400 | 510 |
| Code Review | 代码复审 | 400 | 510 |
| Test | 测试(自我测试,修改代码,提交修改) | 100 | 180 |
| Reporting | 报告 | ||
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 20 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 60 | 45 |
| 合计 | 880 | 1170 |
队友用Python编辑的爬虫代码。
import requests
from urllib.request import urlopen
from bs4 import BeautifulSoup
txt = open(r'C:\Users\Administrator\Desktop\result.txt','w',encoding='utf-8')
#打开文件
i = 0
def getPaper(newsUrl): #获取相关信息的函数
res = requests.get(newsUrl) #打开链接
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser') #把网页内容存进容器
Title = soup.select('#papertitle')[0].text.strip() #找到标题元素爬取
print("Title:",Title,file=txt)
Abstract = soup.select('#abstract')[0].text.strip() #找到摘要元素爬取
print("Abstract:",Abstract,"\n\n",file=txt)
return
sUrl = 'http://openaccess.thecvf.com/CVPR2018.py'
res1 = requests.get(sUrl)
res1.encoding = 'utf-8'
soup1 = BeautifulSoup(res1.text,'html.parser')
for titles in soup1.select('.ptitle'): #返回每个超链接
t = 'http://openaccess.thecvf.com/'+ titles.select('a')[0]['href']
print(i,file=txt)
getPaper(t) #循环打开每个子页面并进行爬取
i=i+1
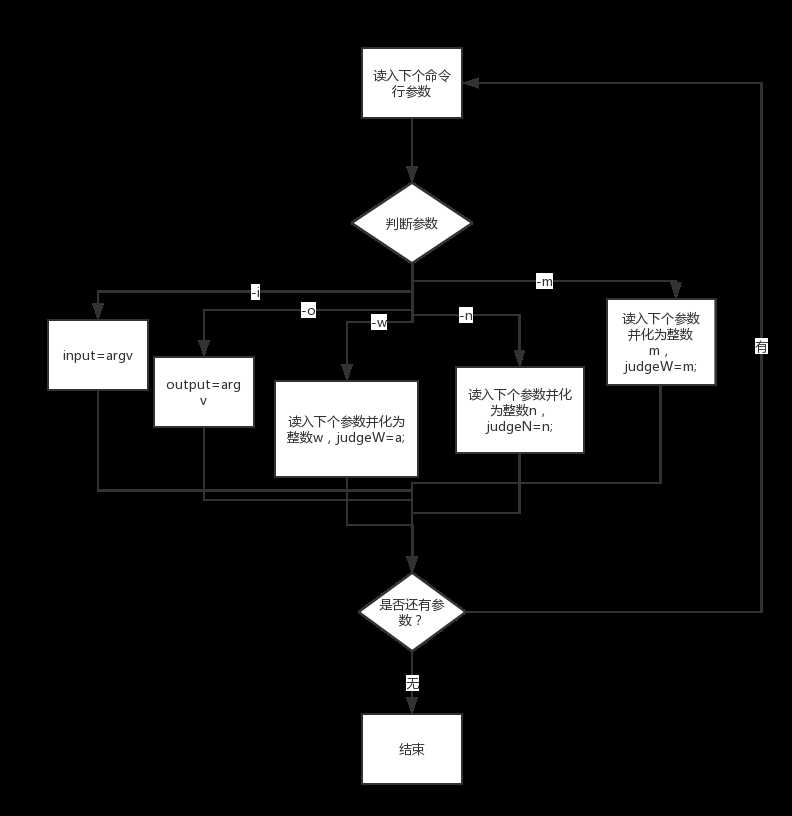
while (1) //循环判断命令行参数
{
i++;
if (i == argc)
break;
if (argv[i][0] == '-') //判断当前参数首字符是否为'-'
{
switch (argv[i][1]) //判断当前参数第二个字符
{
case 'i':
{
i++;
input = argv[i];//第二个字符为i时输入下一个参数赋值给input
break;
}
case 'o':
{
i++;
output = argv[i];//第二个字符为o时输入下一个参数赋值给output
break;
}
case 'w':
{
i++;
judgeW = atoi(argv[i]);//第二个字符为w时judgeW为下一个参数的整数值留作输出判断
break;
}
case 'm':
{
i++;
judgeM = atoi(argv[i]);//第二个字符为m时judgeM为下一个参数的整数值留作输出判断
break;
}
case 'n':
{
i++;
judgeN = atoi(argv[i]);//第二个字符为n时judgeN为下一个参数的整数值留作输出判断
break;
}
default:
cout << "输入参数有误" << endl;
break;
}
}
}
配合命令行参数判断的输出代码如下:
if (judgeW == 0)
{
if (judgeM == 0) //非权重词频统计
{
f1 = f1.countline(input, f1);
f1.Abstract = changeDx(f1.Abstract);
f1.Title = changeDx(f1.Title);//大小写转换
f1 = f1.countword(f1, f1.Title, 1);
f1 = f1.countword(f1, f1.Abstract, 1);
}
else //非权重词组词频统计
{
f1 = f1.outputByLine(input, f1, 1, judgeM);
}
}
else
{
if (judgeM == 0) //权重词频统计
{
f1 = f1.countline(input, f1);
f1.Abstract = changeDx(f1.Abstract);
f1.Title = changeDx(f1.Title);//大小写转换
f1 = f1.countword(f1, f1.Title, 10);
f1 = f1.countword(f1, f1.Abstract, 1);
}
else //权重词组词频统计
{
f1 = f1.outputByLine(input, f1, 10, judgeM);
}
}
if (judgeN == 0)//如果没有定义n那么按默认输出
outCome1(ww, num, output, f1);
else
{
if (judgeN > f1.getwords())
{
cout << "输入的n值超过了文本的所有单词数,将为您按序输出文本的所有单词" << endl;//对于参数过大的错误判断
outCome2(ww, f1.getwords(), output, f1);
}
else
{
outCome2(ww, judgeN, output, f1);//如果定义了n那么输出前n个
}
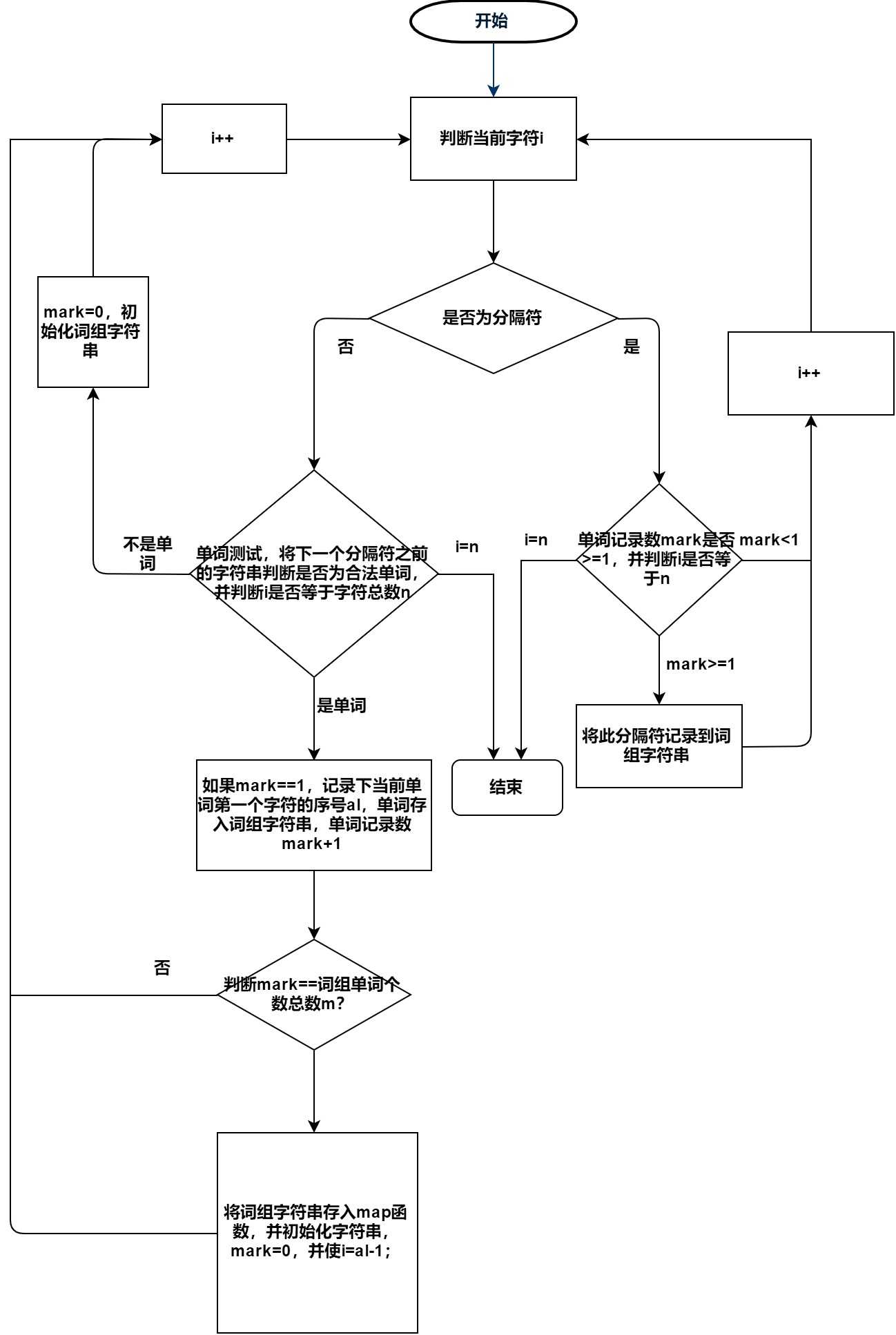
}testfile testfile::phrasecounts(string temp, int t, int quan, testfile f1)
{
int word = 0;
int i = 0;
int j = 0;
long int n = 0;
int m = 0;
string sumwr = "";//初始化一个存放词组的字符串
n = temp.length();
char x[10];
for (j = 0; j < n; j++)
{
if (temp[j] >= 'A'&&temp[j] <= 'Z')
{
temp[j] += 32;
}
}
string phrase;
int flag = 0, k = 0;
int mark = 0, al = 0;//mark用来记录存储的单词数,al用来记录成词组的第二个单词的首字母序号
for (i = 0; i < n; i++)
{
if (!((temp[i] >= 48 && temp[i] <= 57) || (temp[i] >= 97 && temp[i] <= 122)))
{
if (mark > 0)
{
sumwr = sumwr + temp[i];//如果此时已记录一个及以上的单词,将此分隔符也录入词组字符串
}
continue;
}
else
{
for (j = 0; j < 4 && i < n; j++)
{
if (!((temp[i] >= 48 && temp[i] <= 57) || (temp[i] >= 97 && temp[i] <= 122)))
{
mark = 0;
sumwr = "";//检测到非法单词,重新初始化mark和词组字符串
break;
}
else
{
if (j == 0 && mark == 1)
{
al = i;
}
x[j] = temp[i++];//temp中存入四个非空格字符
}
}
if (j == 4)
{
for (m = 0; m < 4; m++)
{
if (x[m] < 97 || x[m]>122)
{
flag = 1;
mark = 0;
sumwr = "";
break;//判断这四个字符是否都是字母,检测到非法单词,重新初始化mark和词组字符串
}
}
if (flag == 0)//判断为一个单词
{
char *w = new char[100];//存放单词
for (m = 0; m < 4; m++)
{
w[k++] = x[m];//temp中字符存入w
}
while (((temp[i] >= 48 && temp[i] <= 57) || (temp[i] >= 97 && temp[i] <= 122)) && i < n)//继续存入单词剩余字符
{
w[k++] = temp[i++];
}
w[k] = '\0';
sumwr = sumwr + w;//将单词存入词组字符串数组
mark++;
delete[]w;
k = 0;
if (mark == t)
{
loadword(sumwr, quan);//如果此时单词存入达到所需数量,将此词组字符串存入map函数,并初始化mark和字符串
word++;
mark = 0;
i = al;//让i等于存入字符串的第二个单词的第一个字母序号,重新开始查询词组
sumwr = "";
}
i--;
}
else
{
flag = 0;
j = 0;
mark = 0;
sumwr = "";
}
}
}
}
i = 0;
f1.words += word;
return f1;
}
#include "stdafx.h"
#include "CppUnitTest.h"
#include "C:\Users\Administrator\Desktop\软工实践\结对作业2\单元测试\WordCount2\WordCount2\WordCount2\WordCount2.h"
#include <iostream>
using namespace Microsoft::VisualStudio::CppUnitTestFramework;
namespace WordCountTest1
{
TEST_CLASS(UnitTest1)
{
public:
TEST_METHOD(phraseCount)
{
testfile f1;
f1=f1.outputByLine("C:\\Users\\Administrator\\Desktop\\result.txt", f1, 1, 3);//按行输出后进行词组词频统计
}
TEST_METHOD(wordCount)
{
testfile f1;
f1 = f1.countline("C:\\Users\\Administrator\\Desktop\\result.txt", f1);
f1 = f1.countword(f1, f1.Abstract, 1);
f1 = f1.countword(f1, f1.Title, 1);
}
TEST_METHOD(countCharacters)
{
testfile f1;
string a;
f1 = f1.countcha("C:\\Users\\Administrator\\Desktop\\result.txt", f1);
Assert::AreEqual(f1.getcharacters(), (int)1220332);
}
TEST_METHOD(countLine)
{
testfile f1;
f1 = f1.countline("C:\\Users\\Administrator\\Desktop\\result.txt", f1);
Assert::AreEqual(f1.getlines(), (int)2937);
}
};
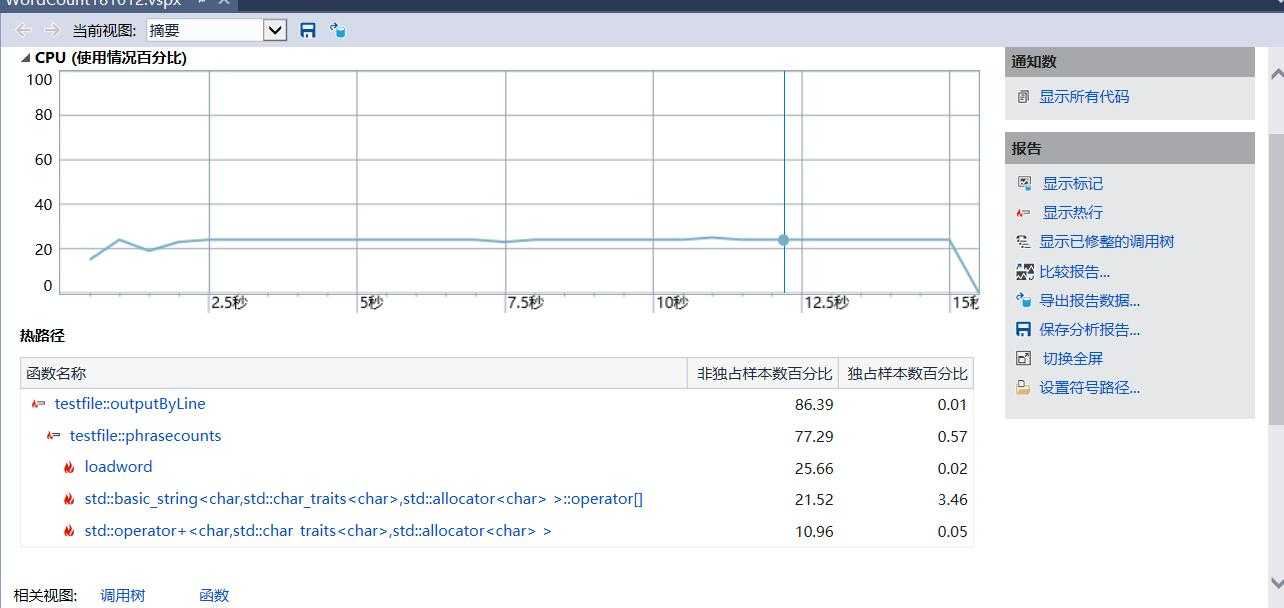
}单元测试通过
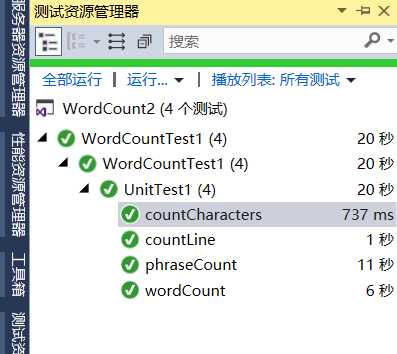
观察单元测试图可以看到,在对一百万字符数的文本文档进行统计时,总执行时间要20秒,其中词组分割花费11秒最多,再者就是单词分割,需要6秒。还有很大的优化空间啊。
玮哥是我大腿,除了词组词频统计的代码,其他的像是什么代码整合,单元测试七七八八的都是由他一个人完成,中途还因为我的失误浪费了一天的时间(有点小愧疚)。下次合作任务时,争取做到细心再细心,像玮哥一样多帮队友分担一些的任务。| 第n周 | 新增代码 | 本周学习耗时 | 重要成果 |
|---|---|---|---|
| 3 | 400 | 12h | 对于字符串的处理更加精进了 |
原文:https://www.cnblogs.com/czhasd/p/9780836.html