作业链接:https://edu.cnblogs.com/campus/fzu/FZUSoftwareEngineering1816W/homework/2160
github链接:https://github.com/hizxk/PairProject-Java
具体分工
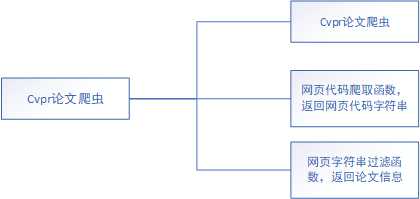
我:论文爬取,行数,字符数,词频统计代码实现
陈顺兴:词组统计代码实现,单元测试
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 20 | 20 |
| ? Estimate | ? 估计这个任务需要多少时间 | 10 | 20 |
| Development | 开发 | 220 | 340 |
| ? Analysis | ? 需求分析 (包括学习新技术) | 20 | 20 |
| ? Design Spec | ? 生成设计文档 | 10 | 10 |
| ? Design Review | ? 设计复审 | 15 | 10 |
| ? Coding Standard | ? 代码规范 (为目前的开发制定合适的规范) | 15 | 20 |
| ? Design | ? 具体设计 | 30 | 45 |
| ? Coding | ? 具体编码 | 210 | 220 |
| ? Code Review | ? 代码复审 | 20 | 25 |
| ? Test | ? 测试(自我测试,修改代码,提交修改) | 30 | 30 |
| Reporting | 报告 | 10 | 20 |
| ? Test Repor | ? 测试报告 | 20 | 20 |
| ? Size Measurement | ? 计算工作量 | 10 | 15 |
| ? Postmortem & Process Improvement Plan | ? 事后总结, 并提出过程改进计划 | 20 | 20 |
| 合计 | 660 | 735 |
本次采用JAVA实现爬虫,运行cvpr文件夹中的Main.class文件,论文自动爬取

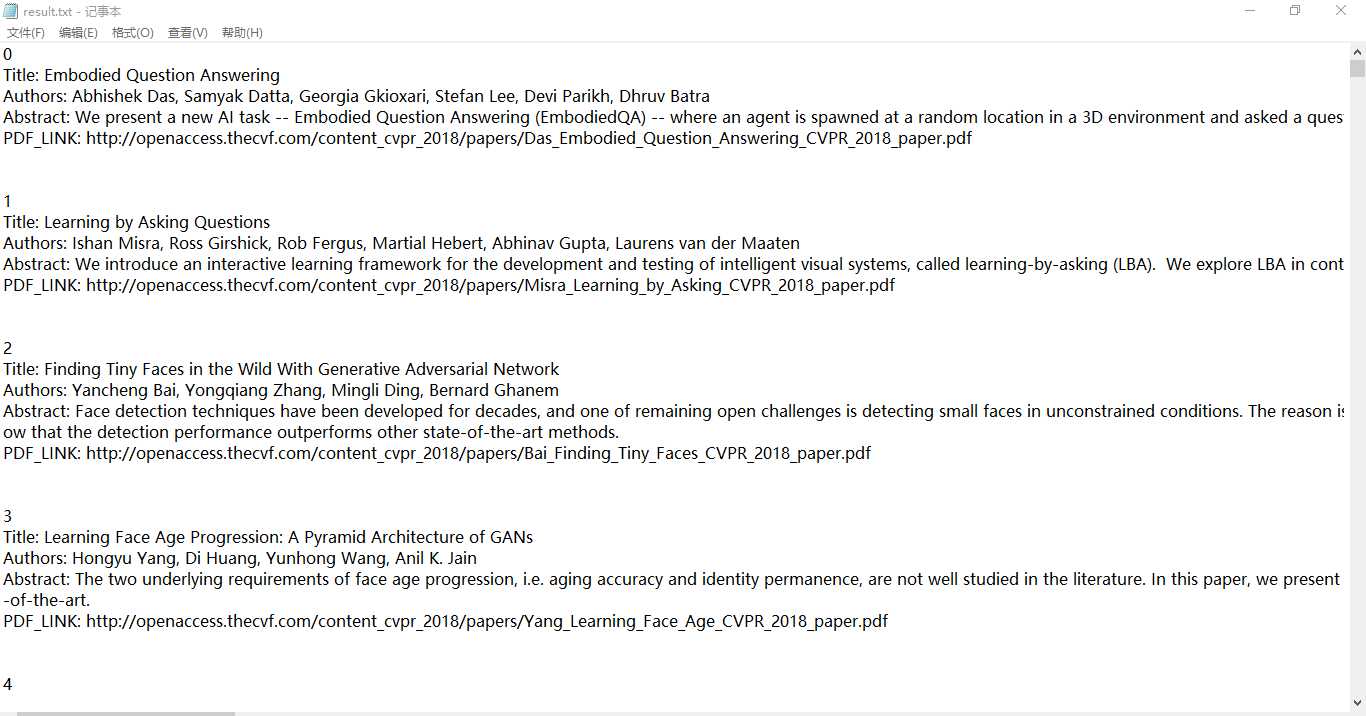
<dt class="ptitle"><br><a href=" ">>Title</a></dt>中,因此构造正则表达式<dt class="ptitle"><br><a href="([^"]*)">([^<]*)截取这两部分,再通过Abstract链接爬取论文网页,论文的Abstract在<div id="abstract" ></div>之间,构造正则表达式<div id="abstract" >(.*?)</div>截取这部分
增加对作者,pdf链接的爬取
构造新的正则表达式,匹配作者和链接
构造正则表达式,用来查找有效Title与Abstract有效字符,统计字符数和有效行数不需要考虑Title与Abstract的权重,因此一并计算
Pattern pattern = Pattern.compile("(Title: |Abstract: )([^\n]*)");
Matcher matcher = pattern.matcher(paper);统计行数
只要查找到匹配向,行数就加一
while (matcher.find()) {
count += 1;
}统计字符数
方法时间查找到的有效字符串,计算长度相加,计算的时候要加上getBytes("utf-8"),如果比较,java默认是以gbk读取,一些特殊字符就无法读取,造成字符数统计错误
while (matcher.find()) {
count += matcher.group(2).getBytes("utf-8").length;
//count+=matcher.group(2).length();
}统计单词数
通过split函数提取字符串中的词组,函数参数是一个正则表达式
过滤完后保存到字符串数组中,再通过matches函数判断单词是否满足条件,同样参数也是一个正则式,[a-zA-Z]{4}[a-zA-Z0-9]表示前四个为英文字符,
while (matcher.find()) {
words = matcher.group(2).split("[^A-Za-z0-9]+");
for (String word : words) {
if (word.matches("[a-zA-Z]{4}[a-zA-Z0-9]*")) {
count++;
}
}
}词频统计
首先构造两个正则表达式,用来匹配Title或Abstract中的字符串
Pattern titlePattern = Pattern.compile("(Title: )([^\n]*)");
Pattern abstractPattern = Pattern.compile("(Abstract: )([^\n]*)");创造一个变量来设置权重
/* 单词权重设置,默认title单词为1 */
int wordWeight = 1;
if (weight == 1) wordWeight = 10;单词与词频用Map类来保存
while ((matcher.find())) {
content = matcher.group(2);
words = content.split("[^A-Za-z0-9]+");
for (String word : words) {
if (word.matches("[a-zA-Z]{4}[a-zA-Z0-9]*")) {
word = word.toLowerCase();
if (wordFrequency.containsKey(word)) {
int temp = wordFrequency.get(word) / wordWeight;
wordFrequency.put(word, (temp + 1) * wordWeight);
} else {
wordFrequency.put(word, wordWeight);
}
}
}
}Map接口好像没有排序的功能,那就将Map转为List
List<Entry<String, Integer>> wordList =
new ArrayList<Map.Entry<String, Integer>>(words.entrySet());通过构造比较器,用来字典排序
Comparator<Entry<String, Integer>> com = new Comparator<Entry<String, Integer>>() {
@Override
public int compare(Entry<String, Integer> arg0, Entry<String, Integer> arg1) {
// TODO Auto-generated method stub
if (!arg0.getValue().equals(arg1.getValue())) {
return (arg1.getValue().compareTo(arg0.getValue()));
} else {
return (arg0.getKey().compareTo(arg1.getKey()));
}
}
};词组统计
主要思路是将单词与分割符分别保存到数组里,再成对成对的判断
单词字符串保存到wods字符串数组中,分割符字符串保存到signs字符串数组中,主要是考虑到形成词组的条件与单词有关,如果相邻单词都满足条件,再与分隔符字符串进行拼接
单词与分割符通过split函数分割并保存到字符串数组中
words = content.split("[^A-Za-z0-9]+");
signs=content.split("[A-Za-z0-9]+");两层循环,第二层循环依赖第一层
for (int i = 0; (i + m) <= length; i++) {
for (int j = i; j < m + i; j++) {
isPhrase = true;
if (!words[j].matches("[a-zA-Z]{4}[a-zA-Z0-9]*")) {
i = j;
phrase = "";
isPhrase = false;
break;
}
if (j == i + m - 1) {
phrase += words[j];
} else {
phrase += (words[j] + signs[j+1]);
}
}
if (isPhrase) {
phrase = phrase.toLowerCase();
if (list.containsKey(phrase)) {
list.put(phrase, list.get(phrase) + 1);
} else {
list.put(phrase, 1);
}
phrase = "";
}
}改进的思路
对字符串的组合采用StringBuilder类实现,取缔String类,String类每加一次就会创建一个新的String对象,会增加内存和运算速度
性能分析图和程序中消耗最大的函数
使用Jprofiler查看性能
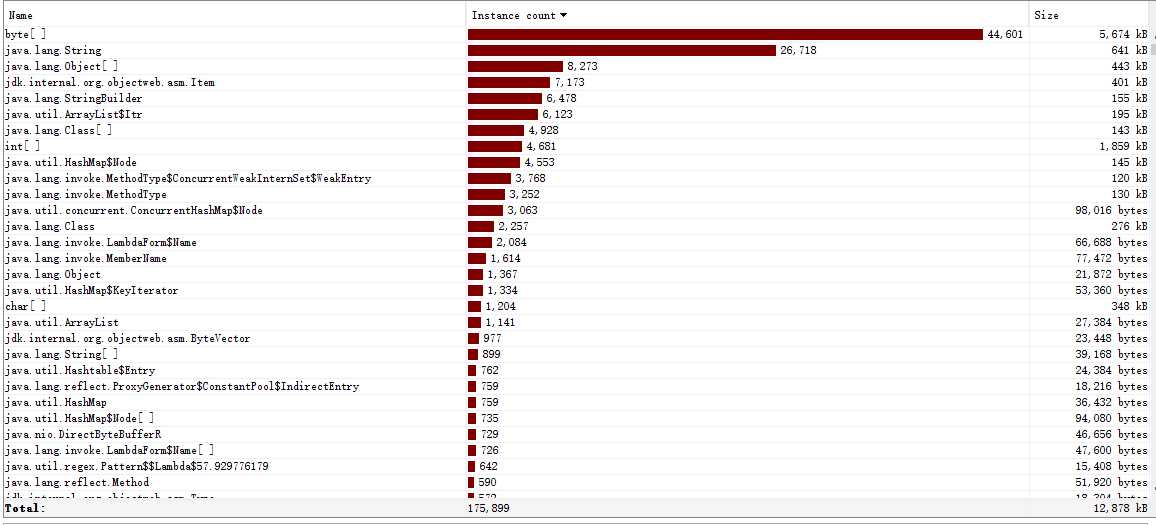
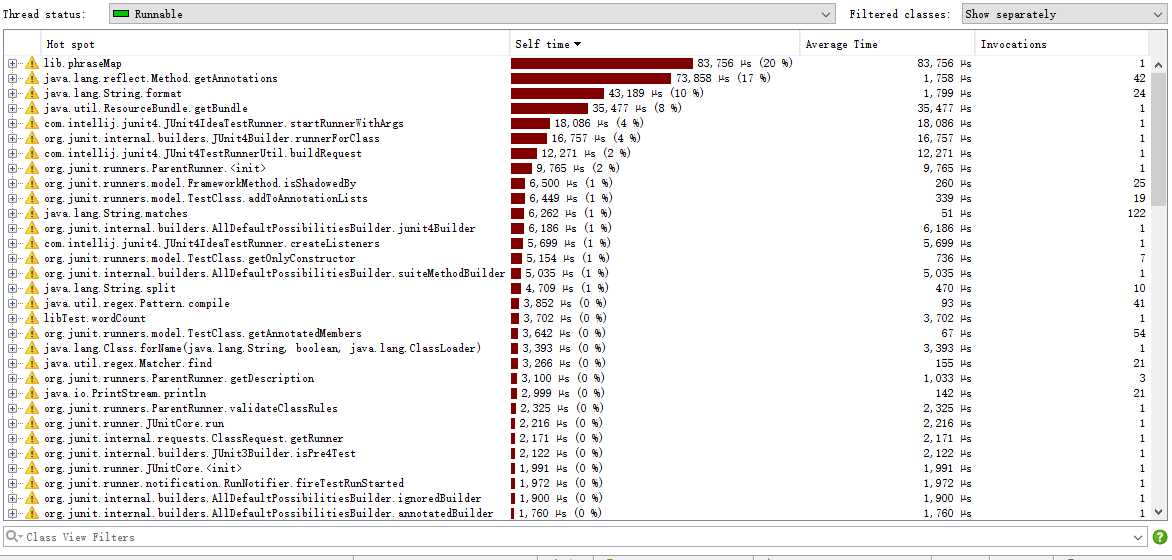
可以看出消耗最大的是phraseMap函数,这个函数是用来统计词组词频的
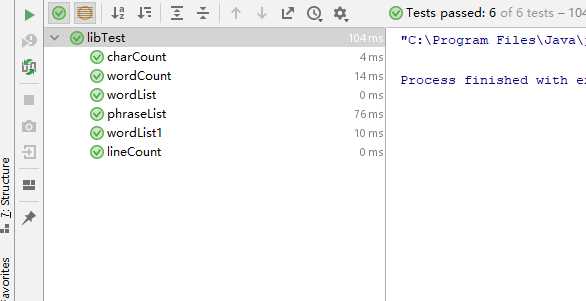
使用junit4中的assertEquals()函数进行测试
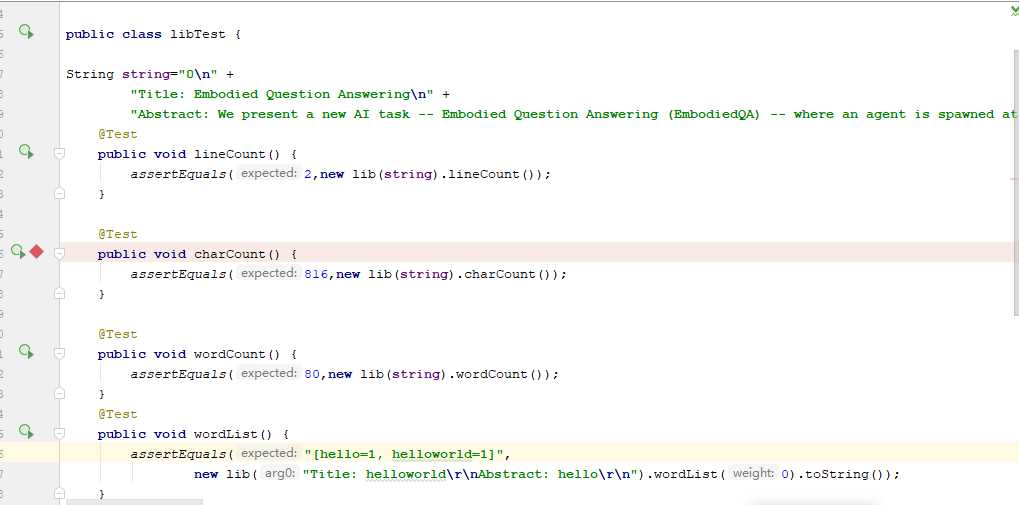
测试结果
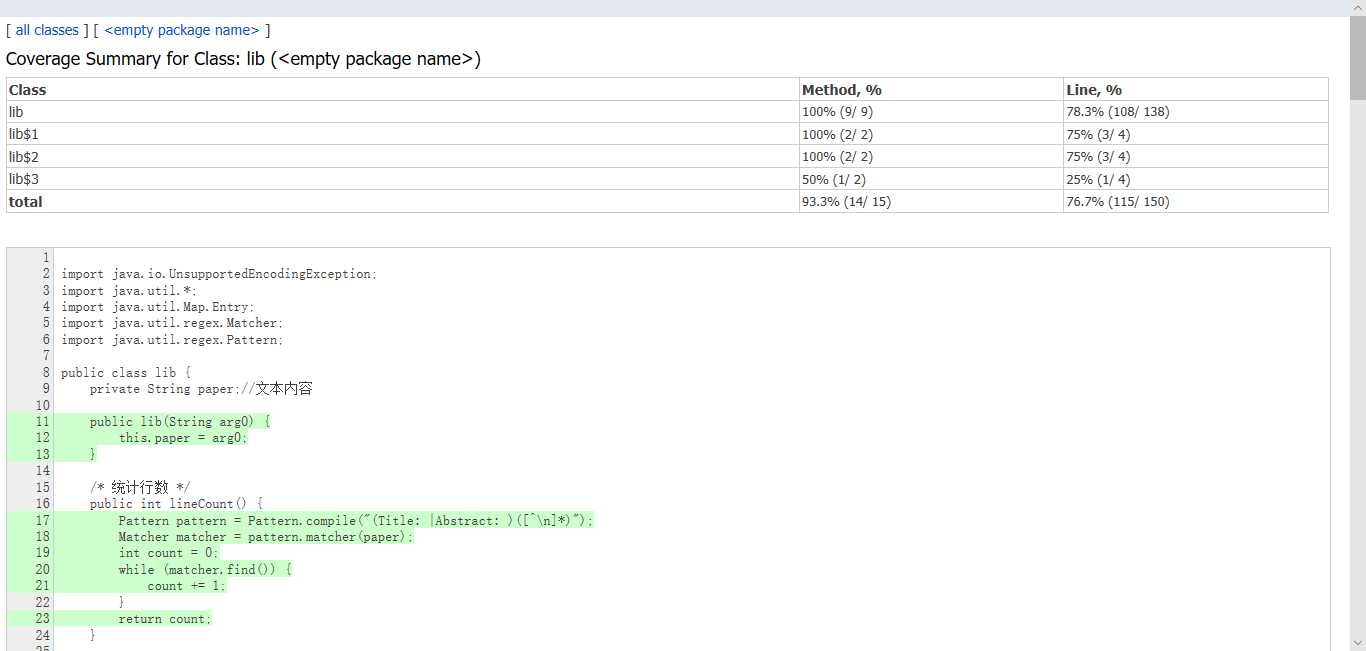
遇到的困难:对java文件或者字符输入流读取原理不是很理解,导致在计算字符数不正确
解决方法:考虑文件及字符串编码,读取文件采用字符流方式,同时设置编码为"utf-8",在统计字符个数时,设置getBytes("utf-8"),发现这样可以解决字符统计不正确的问题
在这次结对过程中,提供一些提高单词,词组统计的想法和建议,很有上进心,敲代码能力很强,想法丰富,是一个很好的队友
| 代码行数(新增/累计) | 学习时间(分钟) | 重要成长 | |
|---|---|---|---|
| 10月1日 | 102/102 | 240 | 爬虫 |
| 10月4日 | 220/322 | 120 | |
| 10月6日 | 104/326 | 120 | |
| 10月7日 | 107/333 | 140 |
原文:https://www.cnblogs.com/hizxk/p/9740018.html