来自:中国大学mooc-山东大学 生物信息学 课程
序列就是字符串。
![]()
s就是一个序列。(原来序列是这么简单的,听着太高大上了)
蛋白质序列:由20个不同的字母(氨基酸)排列组合而成。
核酸序列:由4个不同的字母(碱基,ATCGU)排列组合而成,包括DNA序列和RNA序列。
FASTA格式:第一行>表示注释;第二行及以后:每行60个字母或80,不一定。
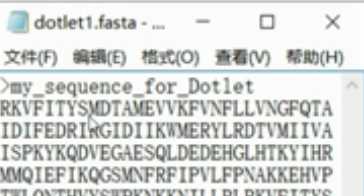
图1.数据格式

图2.相似比较
图中显示了序列的相似性比较,对于序列长度是非常非常长的,肉眼根本无法识别,所以就需要技术来进行识别。
那么有序列一致度identity与相似度similarity两个概念:

图3.一致度和相似度定义

图4.例子
那么这两个序列的一致度就是50%,很好计算。
但是相似度是怎么计算的呢?哪个残基和哪个残基算作相似?
答:残基两两相似关系被 替换积分矩阵 所定义。

图5.蛋白质替换积分矩阵长这个样子
描述了残基两两相似性的量化关系。
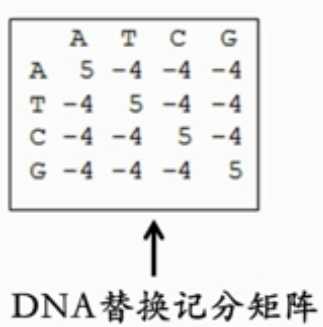
图6.DNA
3种常见的替分矩阵:
原文:https://www.cnblogs.com/BlueBlueSea/p/9746254.html