转载:https://www.cnblogs.com/jasonfreak/p/5448385.html
特征选择主要从两个方面入手:
1.过滤法:按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数选择特征
方差选择法:建议作为数值特征的筛选方法
计算各个特征的方差,然后根据阈值,选择方差大于阈值的特征
from sklearn.feature_selection import VarianceThreshold from sklearn.datasets import load_iris import pandas as pd X,y = load_iris(return_X_y=True) X_df = pd.DataFrame(X,columns=list("ABCD")) #建议作为数值特征的筛选方法,对于分类特征可以考虑每个类别的占比问题 ts = 0.5 vt = VarianceThreshold(threshold=ts) vt.fit(X_df) #查看各个特征的方差 dict_variance = {} for i,j in zip(X_df.columns.values,vt.variances_): dict_variance[i] = j
#获取保留了的特征的特征名 ls = list() for i,j in dict_variance.items(): if j >= ts: ls.append(i) X_new = pd.DataFrame(vt.fit_transform(X_df),columns=ls)
经典的卡方检验是检验定性自变量对定性因变量的相关性。假设自变量有N种取值,因变量有M种取值,考虑自变量等于i且因变量等于j的样本频数的观察值与期望的差距,构建统计量:
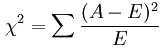
from sklearn.feature_selection import VarianceThreshold,SelectKBest,chi2 from sklearn.datasets import load_iris import pandas as pd X,y = load_iris(return_X_y=True) X_df = pd.DataFrame(X,columns=list("ABCD")) (chi2,pval) = chi2(X_df,y) dict_feature = {} for i,j in zip(X_df.columns.values,chi2): dict_feature[i]=j #对字典按照values排序 ls = sorted(dict_feature.items(),key=lambda item:item[1],reverse=True) #特征选取数量 k =2 ls_new_feature=[] for i in range(k): ls_new_feature.append(ls[i][0]) X_new = X_df[ls_new_feature]
互信息法:建议作为分类问题的分类变量的筛选方法
经典的互信息也是评价定性自变量对定性因变量的相关性的,为了处理定量数据,最大信息系数法被提出,互信息计算公式如下:
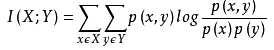
from sklearn.feature_selection import VarianceThreshold,SelectKBest,chi2 from sklearn.datasets import load_iris import pandas as pd from sklearn.feature_selection import mutual_info_classif #用于度量特征和离散目标的互信息 X,y = load_iris(return_X_y=True) X_df = pd.DataFrame(X,columns=list("ABCD")) feature_cat = ["A","D"] discrete_features = [] feature = X_df.columns.values.tolist() for k in feature_cat: if k in feature: discrete_features.append(feature.index(k)) mu = mutual_info_classif(X_df,y,discrete_features=discrete_features, n_neighbors=3, copy=True, random_state=None) dict_feature = {} for i,j in zip(X_df.columns.values,mu): dict_feature[i]=j #对字典按照values排序 ls = sorted(dict_feature.items(),key=lambda item:item[1],reverse=True) #特征选取数量 k =2 ls_new_feature=[] for i in range(k): ls_new_feature.append(ls[i][0]) X_new = X_df[ls_new_feature]
from sklearn.feature_selection import VarianceThreshold,SelectKBest,chi2 from sklearn.datasets import load_iris import pandas as pd from sklearn.feature_selection import mutual_info_classif,mutual_info_regression #用于度量特征和连续目标的互信息 X,y = load_iris(return_X_y=True) X_df = pd.DataFrame(X,columns=list("ABCD")) feature_cat = ["A","D"] discrete_features = [] feature = X_df.columns.values.tolist() for k in feature_cat: if k in feature: discrete_features.append(feature.index(k)) mu = mutual_info_regression(X_df,y,discrete_features=discrete_features, n_neighbors=3, copy=True, random_state=None) dict_feature = {} for i,j in zip(X_df.columns.values,mu): dict_feature[i]=j #对字典按照values排序 ls = sorted(dict_feature.items(),key=lambda item:item[1],reverse=True) #特征选取数量 k =2 ls_new_feature=[] for i in range(k): ls_new_feature.append(ls[i][0]) X_new = X_df[ls_new_feature]
from sklearn.datasets import load_iris import pandas as pd from sklearn.feature_selection import RFE,RFECV from sklearn.ensemble import RandomForestClassifier X,y = load_iris(return_X_y=True) X_df = pd.DataFrame(X,columns=list("ABCD")) refCV = RFECV(estimator=RandomForestClassifier(), step=0.5, cv =5, scoring=None, n_jobs=-1) refCV.fit(X_df,y) #保留特征的数量 refCV.n_features_ #保留特征的False、True标记 refCV.support_ feature_new = X_df.columns.values[refCV.support_] #交叉验证分数 refCV.grid_scores_
原文:https://www.cnblogs.com/wzdLY/p/9689547.html