关于python爬虫多个库的选择反反复复,总是不知道选择哪个,通过试过多个晚上的选择
- reques
- Beautifulsoup
以上两个库足够爬虫,已反爬虫网站数据的爬取。先上代码:
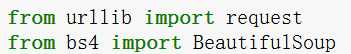
url=‘**********************‘
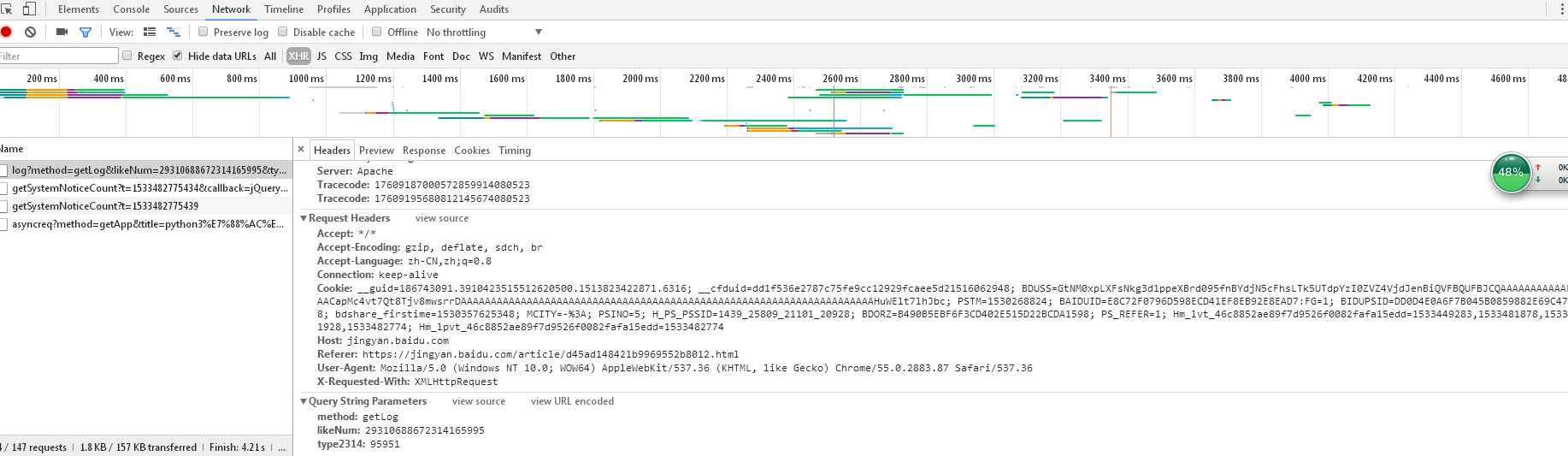
- 网页reques headers构建,主要是反爬虫网站的伪装,获取地址在network中的XHR中的request headers的User-Agent,如下所示:(任何一个json文件都可以)
- 具体代码自己根据css或者是HTML格式去获取,正则表达式后面更新,个人具体代码如下所示:

python 爬虫新解
原文:https://www.cnblogs.com/yxxblog/p/9427907.html