线程的队列:
queue队列,使用import queue,用法与进程Queue一样
queue is especially useful in threaded programming when information must be exchanged safely between multiple threads.
queue.Queue(maxsize=0) #先进先出import queue q=queue.Queue() q.put(‘first‘) q.put(‘second‘) q.put(‘third‘) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 结果(先进先出): first second third ‘‘‘ 先进先出
class queue.LifoQueue(maxsize=0) #last in fisrt out
import queue q=queue.LifoQueue() q.put(‘first‘) q.put(‘second‘) q.put(‘third‘) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 结果(后进先出): third second first ‘‘‘ 后进先出
class queue.PriorityQueue(maxsize=0) #存储数据时可设置优先级的队列
import queue q=queue.PriorityQueue() #put进入一个元组,元组的第一个元素是优先级(通常是数字,也可以是非数字之间的比较),数字越小优先级越高 q.put((20,‘a‘)) q.put((10,‘b‘)) q.put((30,‘c‘)) print(q.get()) print(q.get()) print(q.get()) ‘‘‘ 结果(数字越小优先级越高,优先级高的优先出队): (10, ‘b‘) (20, ‘a‘) (30, ‘c‘) ‘‘‘ 优先级队列
线程池的问题:
#1 介绍 concurrent.futures模块提供了高度封装的异步调用接口 ThreadPoolExecutor:线程池,提供异步调用 ProcessPoolExecutor: 进程池,提供异步调用 Both implement the same interface, which is defined by the abstract Executor class. #2 基本方法 #submit(fn, *args, **kwargs) 异步提交任务 #map(func, *iterables, timeout=None, chunksize=1) 取代for循环submit的操作 #shutdown(wait=True) 相当于进程池的pool.close()+pool.join()操作 wait=True,等待池内所有任务执行完毕回收完资源后才继续 wait=False,立即返回,并不会等待池内的任务执行完毕 但不管wait参数为何值,整个程序都会等到所有任务执行完毕 submit和map必须在shutdown之前 #result(timeout=None) 取得结果 #add_done_callback(fn) 回调函数
mport time
from threading import currentThread,get_ident
from concurrent.futures import ThreadPoolExecutor # 帮助你启动线程池的类
from concurrent.futures import ProcessPoolExecutor # 帮助你启动线程池的类
def func(i):
time.sleep(1)
print(‘in %s %s‘%(i,currentThread()))
return i**2
def back(fn):
print(fn.result(),currentThread())
# map启动多线程任务
# t = ThreadPoolExecutor(5)
# t.map(func,range(20))
# for i in range(20):
# t.submit(func,i)
# submit异步提交任务
# t = ThreadPoolExecutor(5)
# for i in range(20):
# t.submit(fn=func,)
# t.shutdown()
# print(‘main : ‘,currentThread())
# 起多少个线程池
# 5*CPU的个数
# 获取任务结果
# t = ThreadPoolExecutor(20)
# ret_l = []
# for i in range(20):
# ret = t.submit(func,i)
# ret_l.append(ret)
# t.shutdown()
# for ret in ret_l:
# print(ret.result())
# print(‘main : ‘,currentThread())
# 回调函数
t = ThreadPoolExecutor(20)
for i in range(100):
t.submit(func,i).add_done_callback(back)
# 回调函数(进程版)
import os
import time
from concurrent.futures import ProcessPoolExecutor # 帮助你启动线程池的类
def func(i):
time.sleep(1)
print(‘in %s %s‘%(i,os.getpid()))
return i**2
def back(fn):
print(fn.result(),os.getpid())
if __name__ == ‘__main__‘:
print(‘main : ‘,os.getpid())
t = ProcessPoolExecutor(20)
for i in range(100):
t.submit(func,i).add_done_callback(back)
multiprocessing模块自带进程池的
threading 模块是没有线程池的
concurrent.futures 进程池 和 线程池
创建线程池/进程池 ProcessPoolExecutor ThreadPoolExecutor
ret = t.submit(func,arg1,arg2...) 异步提交任务
ret.result() 获取结果,如果要想实现异步效果,应该使用列表
map(func,iterable)
shutdown close+join 同步控制的
add_done_callback 回调函数,在回调函数内接收的参数是一个对象,需要通过result来获取返回值
回调函数仍然在主进程中执行
协程:
之前我们学习了线程、进程的概念,了解了在操作系统中进程是资源分配的最小单位,线程是CPU调度的最小单位。按道理来说我们已经算是把cpu的利用率提高很多了。但是我们知道无论是创建多进程还是创建多线程来解决问题,都要消耗一定的时间来创建进程、创建线程、以及管理他们之间的切换。
随着我们对于效率的追求不断提高,基于单线程来实现并发又成为一个新的课题,即只用一个主线程(很明显可利用的cpu只有一个)情况下实现并发。这样就可以节省创建线进程所消耗的时间。
为此我们需要先回顾下并发的本质:切换+保存状态
cpu正在运行一个任务,会在两种情况下切走去执行其他的任务(切换由操作系统强制控制),一种情况是该任务发生了阻塞,另外一种情况是该任务计算的时间过长
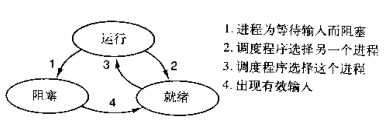
ps:在介绍进程理论时,提及进程的三种执行状态,而线程才是执行单位,所以也可以将上图理解为线程的三种状态
一:其中第二种情况并不能提升效率,只是为了让cpu能够雨露均沾,实现看起来所有任务都被“同时”执行的效果,如果多个任务都是纯计算的,这种切换反而会降低效率。
为此我们可以基于yield来验证。yield本身就是一种在单线程下可以保存任务运行状态的方法,我们来简单复习一下:
#1 yiled可以保存状态,yield的状态保存与操作系统的保存线程状态很像,但是yield是代码级别控制的,更轻量级 #2 send可以把一个函数的结果传给另外一个函数,以此实现单线程内程序之间的切换
进程:资源分配的最小单位,班级
线程:cpu调度最小单位,人
什么是协程:能在一条线程的基础上,在多个任务之间互相切换
节省了线程开启的消耗
是从python代码级别调度的
正常的线程是cpu调度的最小单位
协程的调度并不是由操作系统来完成的
所学的协程:
# 你学过协程 # 在两个任务之间互相切换 # def func(): # print(1) # x = yield ‘aaa‘ # print(x) # yield ‘bbb‘ # # g = func() # print(next(g)) # print(g.send(‘****‘)) # 在多个函数之间互相切换的功能 - 协程 # def consumer(): # while True: # x = yield # print(x) # def producer(): # g = consumer() # next(g) # 预激 # for i in range(10): # g.send(i) # producer() # yeild 只有程序之间的切换,没有重利用任何IO操作的时间
协程:是单线程下的并发,又称微线程,纤程。英文名Coroutine。一句话说明什么是线程:协程是一种用户态的轻量级线程,即协程是由用户程序自己控制调度的。、
需要强调的是:
#1. python的线程属于内核级别的,即由操作系统控制调度(如单线程遇到io或执行时间过长就会被迫交出cpu执行权限,切换其他线程运行) #2. 单线程内开启协程,一旦遇到io,就会从应用程序级别(而非操作系统)控制切换,以此来提升效率(!!!非io操作的切换与效率无关)
对比操作系统控制线程的切换,用户在单线程内控制协程的切换
优点如下:
#1. 协程的切换开销更小,属于程序级别的切换,操作系统完全感知不到,因而更加轻量级 #2. 单线程内就可以实现并发的效果,最大限度地利用cpu
缺点如下:
#1. 协程的本质是单线程下,无法利用多核,可以是一个程序开启多个进程,每个进程内开启多个线程,每个线程内开启协程 #2. 协程指的是单个线程,因而一旦协程出现阻塞,将会阻塞整个线程
总结协程特点:
使用pip3 install greenlet来安装greenlet模块
greenlet:
def eat(): # print(‘吃‘) # time.sleep(1) # g2.switch() # 切换 # print(‘吃完了‘) # time.sleep(1) # g2.switch() # # def play(): # print(‘玩儿‘) # time.sleep(1) # g1.switch() # print(‘玩儿美了‘) # time.sleep(1) # # g1 = greenlet(eat) # g2 = greenlet(play) # g1.switch() # 切换 # 遇到IO就切换 # gevent pip3 install gevent # greenlet是gevent的底层 # gevent是基于greenlet实现的 # python代码在控制程序的切换
greenlet只是提供了一种比generator更加便捷的切换方式,当切到一个任务执行时如果遇到io,那就原地阻塞,仍然是没有解决遇到IO自动切换来提升效率的问题。
单线程里的这20个任务的代码通常会既有计算操作又有阻塞操作,我们完全可以在执行任务1时遇到阻塞,就利用阻塞的时间去执行任务2。。。。如此,才能提高效率,这就用到了Gevent模块。
比较:
#顺序执行
import time
def f1():
res=1
for i in range(100000000):
res+=i
def f2():
res=1
for i in range(100000000):
res*=i
start=time.time()
f1()
f2()
stop=time.time()
print(‘run time is %s‘ %(stop-start)) #10.985628366470337
#切换
from greenlet import greenlet
import time
def f1():
res=1
for i in range(100000000):
res+=i
g2.switch()
def f2():
res=1
for i in range(100000000):
res*=i
g1.switch()
start=time.time()
g1=greenlet(f1)
g2=greenlet(f2)
g1.switch()
stop=time.time()
print(‘run time is %s‘ %(stop-start)) # 52.763017892837524
效率对比
安装:pip3 install gevent
Gevent 是一个第三方库,可以轻松通过gevent实现并发同步或异步编程,在gevent中用到的主要模式是Greenlet, 它是以C扩展模块形式接入Python的轻量级协程。 Greenlet全部运行在主程序操作系统进程的内部,但它们被协作式地调度。
g1=gevent.spawn(func,1,,2,3,x=4,y=5)创建一个协程对象g1,spawn括号内第一个参数是函数名,如eat,后面可以有多个参数,可以是位置实参或关键字实参,都是传给函数eat的 g2=gevent.spawn(func2) g1.join() #等待g1结束 g2.join() #等待g2结束 #或者上述两步合作一步:gevent.joinall([g1,g2]) g1.value#拿到func1的返回值 用法介绍
import gevent
def eat(name):
print(‘%s eat 1‘ %name)
gevent.sleep(2)
print(‘%s eat 2‘ %name)
def play(name):
print(‘%s play 1‘ %name)
gevent.sleep(1)
print(‘%s play 2‘ %name)
g1=gevent.spawn(eat,‘egon‘)
g2=gevent.spawn(play,name=‘egon‘)
g1.join()
g2.join()
#或者gevent.joinall([g1,g2])
print(‘主‘)
例:遇到io主动切换
例gevent.sleep(2)模拟的是gevent可以识别的io阻塞,而time.sleep(2)或其他的阻塞,gevent是不能直接识别的需要用下面一行代码,打补丁,就可以识别了
from gevent import monkey;monkey.patch_all()必须放到被打补丁者的前面,如time,socket模块之前
或者我们干脆记忆成:要用gevent,需要将from gevent import monkey;monkey.patch_all()放到文件的开头
# 使用协程减少IO操作带来的时间消耗
from gevent import monkey;monkey.patch_all()
import gevent
import time
def eat():
print(‘吃‘)
time.sleep(2)
print(‘吃完了‘)
def play():
print(‘玩儿‘)
time.sleep(1)
print(‘玩儿美了‘)
g1 = gevent.spawn(eat)
g2 = gevent.spawn(play)
gevent.joinall([g1,g2])
# g1.join()
# g2.join()
# 没执行
# 为什么没执行???是需要开启么?
# 没有开启但是切换了
# gevent帮你做了切换,做切换是有条件的,遇到IO才切换
# gevent不认识除了gevent这个模块内以外的IO操作
# 使用join可以一直阻塞直到协程任务完成
# 帮助gevent来认识其他模块中的阻塞
# from gevent import monkey;monkey.patch_all()写在其他模块导入之前
import threading
import gevent
import time
def eat():
print(threading.current_thread().getName())
print(‘eat food 1‘)
time.sleep(2)
print(‘eat food 2‘)
def play():
print(threading.current_thread().getName())
print(‘play 1‘)
time.sleep(1)
print(‘play 2‘)
g1=gevent.spawn(eat)
g2=gevent.spawn(play)
gevent.joinall([g1,g2])
print(‘主‘)
查看threading.current_thread().getName()我们可以用threading.current_thread().getName()来查看每个g1和g2,查看的结果为DummyThread-n,即假线程
Gevent之同步与异步
from gevent import spawn,joinall,monkey;monkey.patch_all()
import time
def task(pid):
"""
Some non-deterministic task
"""
time.sleep(0.5)
print(‘Task %s done‘ % pid)
def synchronous(): # 同步
for i in range(10):
task(i)
def asynchronous(): # 异步
g_l=[spawn(task,i) for i in range(10)]
joinall(g_l)
print(‘DONE‘)
if __name__ == ‘__main__‘:
print(‘Synchronous:‘)
synchronous()
print(‘Asynchronous:‘)
asynchronous()
# 上面程序的重要部分是将task函数封装到Greenlet内部线程的gevent.spawn。
# 初始化的greenlet列表存放在数组threads中,此数组被传给gevent.joinall 函数,
# 后者阻塞当前流程,并执行所有给定的greenlet任务。执行流程只会在 所有greenlet执行完后才会继续向下走。
协程来实现socket()
from gevent import monkey;monkey.patch_all()
import socket
import gevent
def talk(conn):
while True:
conn.send(b‘hello‘)
print(conn.recv(1024))
sk = socket.socket()
sk.bind((‘127.0.0.1‘,9090))
sk.listen()
while True:
conn,addr = sk.accept()
gevent.spawn(talk,conn)
server
import socket
from threading import Thread
def client():
sk = socket.socket()
sk.connect((‘127.0.0.1‘,9090))
while True:
print(sk.recv(1024))
sk.send(b‘bye‘)
for i in range(500):
Thread(target=client).start()
client
# 4C 并发50000 qps
# 5个进程
# 20个线程
# 500个协程
协程: 能够在单核情况下 极大地提高cpu的利用率
不存在数据不安全的问题
也不存在线程切换\创造的时间开销
切换时用户级别的,程序不会因为协程中某一个任务进入阻塞状态而使整个线程阻塞
线程的切换
时间片到了 降低cpu的效率
io会切 提高了cpu效率
python 线程(队列,线程池),协程(理论greenlet,gevent模块,)
原文:https://www.cnblogs.com/lnrick/p/9397726.html