说明:单机版的Spark的机器上只需要安装Scala和JDK即可,其他诸如Hadoop、Zookeeper之类的东西可以一概不安装
只需下载如下三个包

1.安装jdk

配置环境变量
vim /etc/profile

路径根据自己的解压路径配置
之后将其生效
source /etc/profile
2安装scala
配置环境变量

同样执行命令source /etc/profile
3,最后安装spark

同样配置环境变量,执行命令使其生效,ps,path中的$PATH必须要加,否则bash脚本失效

那么现在看spark是否能成功启动
cd之spark的bin目录,执行./bin/spark-shell
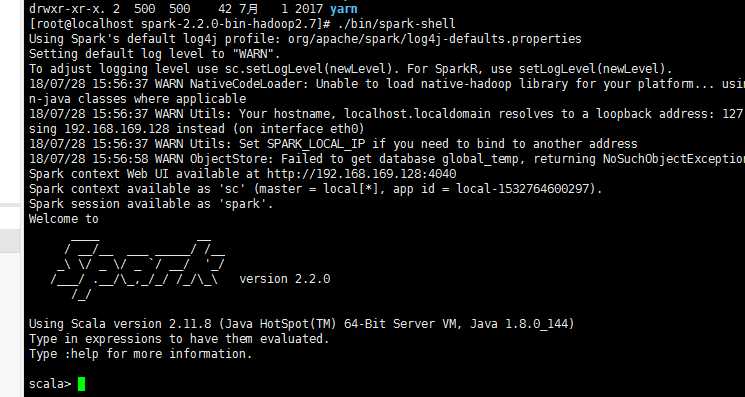
则进入scala交互环境,则成功启动
写个python脚本测试下
# _*_ coding:utf-8 _*_ from __future__ import print_function from pyspark.sql import SparkSession from pyspark.sql import Row def json_dataset_example(spark): sc = spark.sparkContext #读取json串 path = "/home/hadoop/spark-2.2.0-bin-hadoop2.7/mydemo/employees.json" peopleDF = spark.read.json(path) peopleDF.printSchema() peopleDF.createOrReplaceTempView("employees") teenagerNamesDF = spark.sql("SELECT name FROM employees WHERE salary BETWEEN 3500 AND 4500") teenagerNamesDF.show() #直接字符串 jsonStrings = [‘{"name":"Yin","address":{"city":"Columbus","state":"Ohio"}}‘] otherPeopleRDD = sc.parallelize(jsonStrings) otherPeople = spark.read.json(otherPeopleRDD) otherPeople.show() if __name__ == "__main__": spark = SparkSession .builder .appName("myPeople demo") .getOrCreate() json_dataset_example(spark) spark.stop()
提交测试脚本

输出


没毛病,收工
原文:https://www.cnblogs.com/zixilonglong/p/9382343.html