一、前述
本文通过一个案例来讲解Q-Learning
二、具体
1、案例
假设我们需要走到5房间。
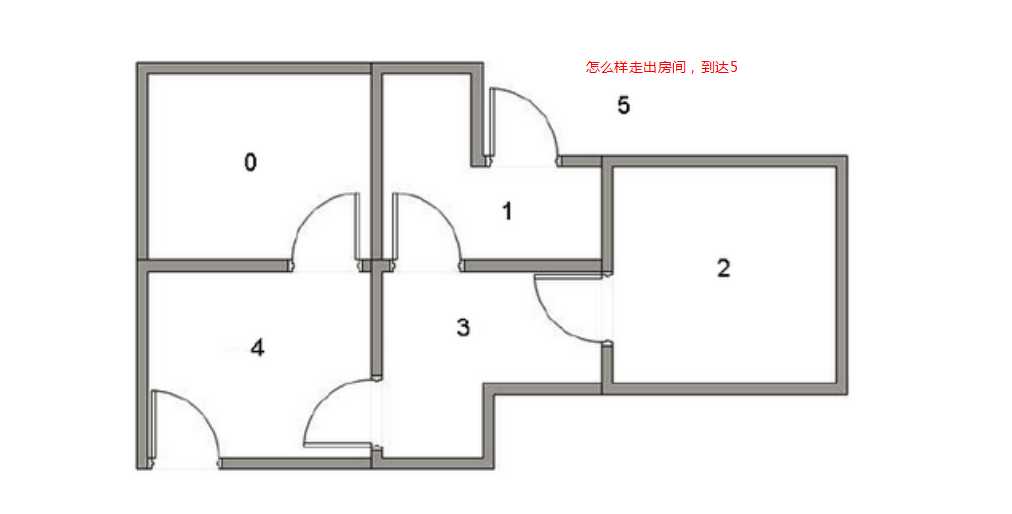
转变为如下图:先构造奖励,达到5,即能够走得5的action则说明奖励比较高设置成100,没有达到5说明奖励比较低,设置成0。
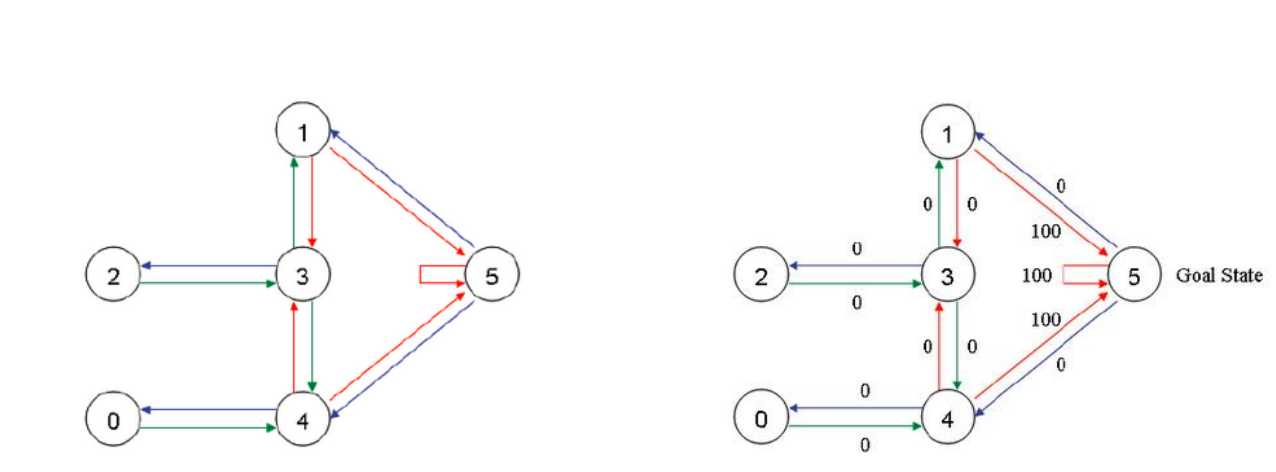
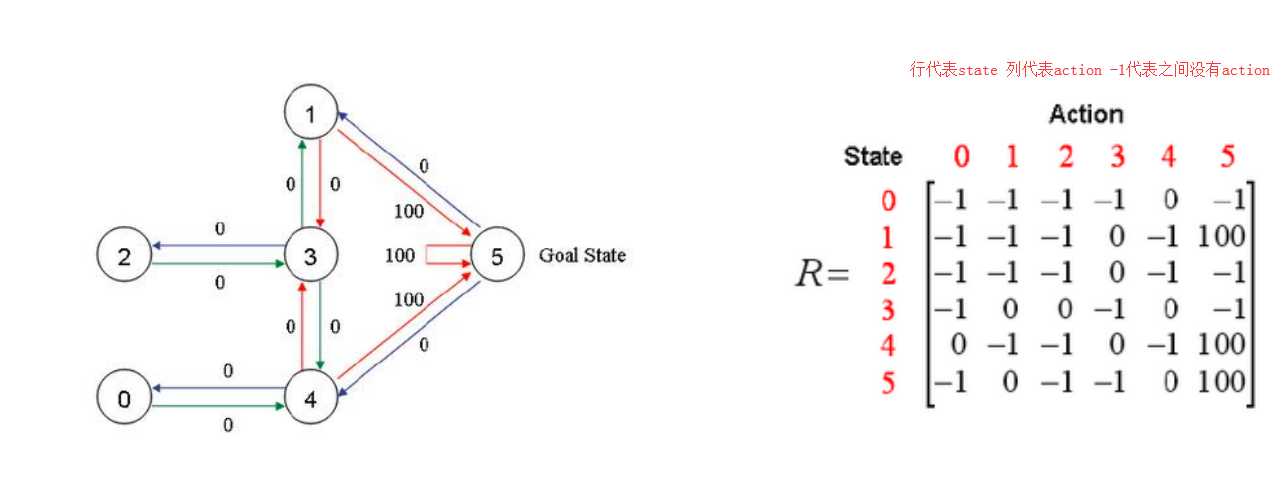
Q-learning实现步骤:

2、案例详解:
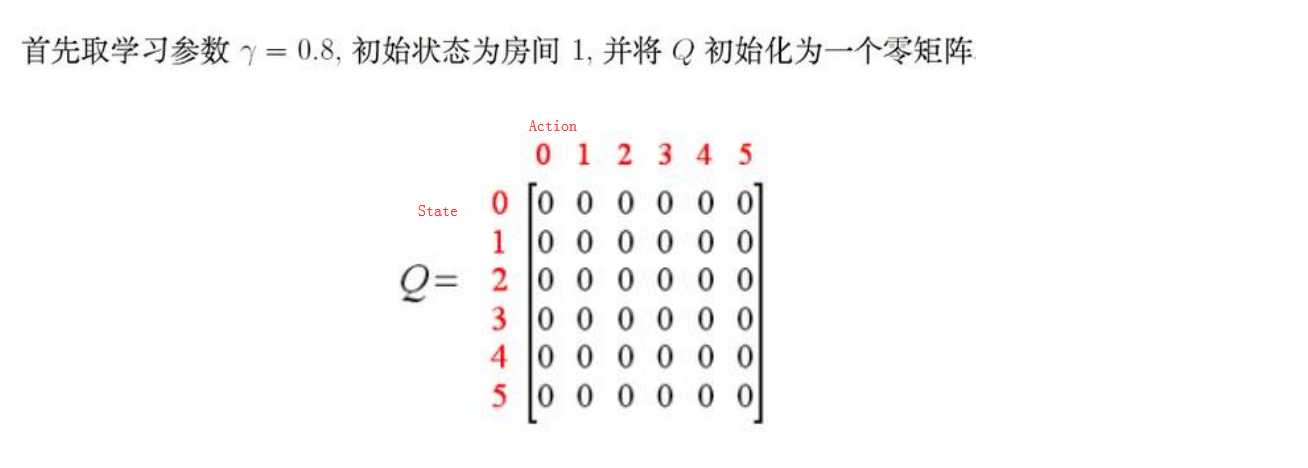

第一步的Q(1,5):最开始的Q矩阵都是零矩阵,迭代完之后Q(1,5)是100

第二次迭代:依旧是随机

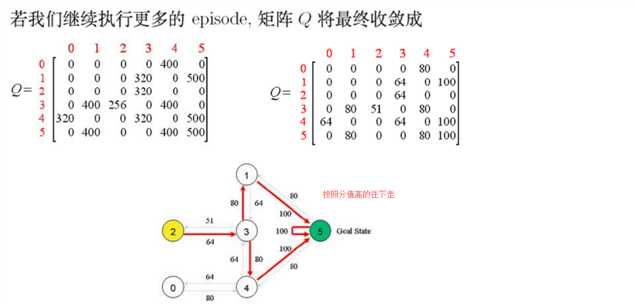
收敛的意思是最后Q基本不变了,然后归一化操作,所有值都除以500,然后计算百分比。
则最后的分值填充如下:
原文:https://www.cnblogs.com/LHWorldBlog/p/9249011.html