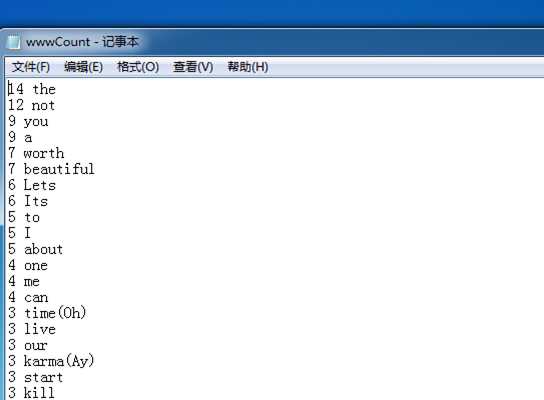
wwwFile = open(‘www.txt‘,mode=‘r‘,encoding=‘utf-8‘) wwwText = wwwFile.read() wwwFile.close() print(wwwText) replaceList=[‘,‘,‘.‘,"‘",‘\n‘] for c in replaceList: wwwText = wwwText.replace(c,‘‘) print(wwwText) print(wwwText.split(‘ ‘)) wwwList=wwwText.split(‘ ‘) print(wwwList.count(‘www‘)) wwwSet = set(wwwList) print(wwwSet) wwwDict ={ } for word in wwwSet: wwwDict[word] = wwwList.count(word) print(wwwDict) for d in wwwDict: print(d,wwwDict[d]) wordCountList = list(wwwDict.items()) print(wordCountList) wordCountList.sort(key=lambda x:x[1],reverse=True) print(wordCountList) for i in range(20): print(wordCountList[i]) wwwCountFile = open(‘wwwCount.txt‘, mode=‘a‘,encoding=‘utf-8‘) for i in range(len(wordCountList)): wwwCountFile.write(str(wordCountList[i][1])+‘ ‘+wordCountList[i][0]+‘\n‘) wwwCountFile.close()
原文:https://www.cnblogs.com/guangzhoushangxueyuan121/p/9206189.html