from selenium import webdriver
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import csv
#设置UA标识
dcap = dict(DesiredCapabilities.PHANTOMJS)
dcap["phantomjs.page.settings.userAgent"] = (
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.87 Safari/537.36 "
)
driver = webdriver.PhantomJS(executable_path=‘phantomjs‘, desired_capabilities=dcap)
#构造百度音乐歌单首页
pageNum = 1
url = ‘%s%d%s‘ % (‘http://music.baidu.com/songlist/tag/%E5%85%A8%E9%83%A8?orderType=1&offset=‘, 20*pageNum, ‘&third_type=‘)
#创建歌单csv文件
csv_file = open("songlist.csv", "w", newline=‘‘, encoding=‘utf_8_sig‘)
write = csv.writer(csv_file)
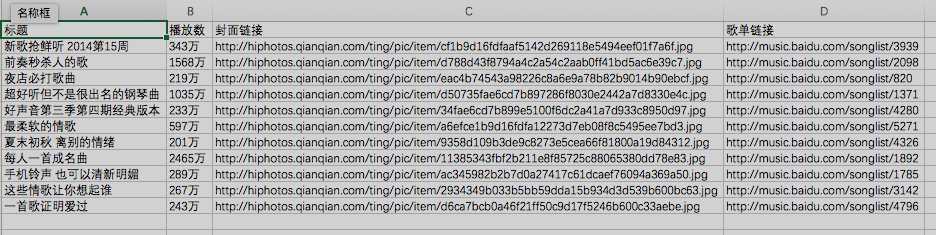
write.writerow([‘标题‘, ‘播放数‘, ‘封面链接‘, ‘歌单链接‘])
while 1:
#找到歌单内容存放位置
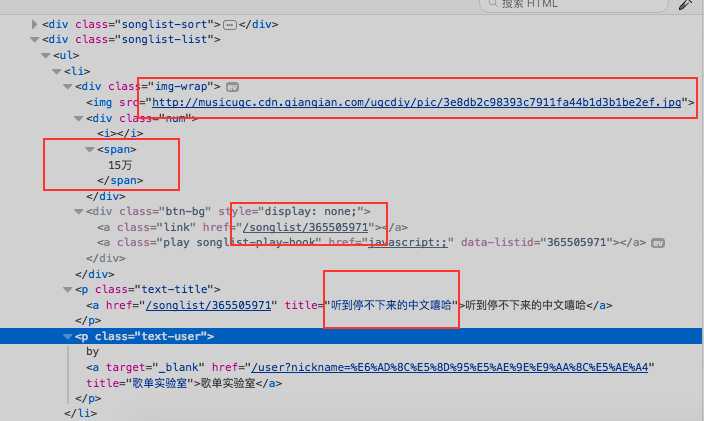
driver.get(url)
data = driver.find_element_by_class_name("songlist-list").find_element_by_tag_name("ul"). find_elements_by_tag_name("li")
#最后一页跳出循环
if len(data) == 0:
break
#解析当前页歌单列表
for i in range(len(data)):
num = data[i].find_element_by_class_name("num").text
#获取播放数大于500万的歌单
if ‘万‘ in num and int(num.split("万")[0]) > 200:
wrap = data[i].find_element_by_class_name("img-wrap"). find_element_by_tag_name("img")
songListTitle = data[i].find_element_by_class_name("text-title"). find_element_by_tag_name("a")
#输出歌单名等信息
print(songListTitle.get_attribute(‘title‘),
num, wrap.get_attribute(‘src‘),
songListTitle.get_attribute(‘href‘))
#写入csv文件
write.writerow([songListTitle.get_attribute(‘title‘),
num, wrap.get_attribute(‘src‘),
songListTitle.get_attribute(‘href‘)])
#构造下一页url
pageNum += 1
url = ‘%s%d%s‘ % (‘http://music.baidu.com/songlist/tag/%E5%85%A8%E9%83%A8?orderType=1&offset=‘, 20*pageNum, ‘&third_type=‘)
csv_file.close()
1 加载浏览器驱动: webdriver.PhantomJS() 2 打开页面:get() 3 关闭浏览器:quit() 4 最大化窗口: maximize_window() 5 设置窗口参数:set_window_size(600,800) 6 后退到前一页: back() 7 前进到后一页: forward() 8 刷新页面: refresh()
id定位:find_element_by_id()
name定位:find_element_by_name()
class定位:find_element_by_class()
tag定位:find_element_by_tag_name()
link定位:find_element_by_link_text()
partial link 定位: find_element_by_partial_link_text()
绝对路径:find_element_by_xpath("绝对路径")
元素属性:find_element_by_xpath("//unput[@id=‘kw‘]")
层级与属性结合:find_element_by_xpath("//form[@id=‘loginForm‘]/ul/input[1]")
逻辑运算符:find_element_by_xpath("//input[@id=‘kw‘ and@class=‘s_ipt‘]")
find_element_by_css_selector()
find_elements_by_id()
find_elements_by_name()
find_elements_by_class()
find_elements_by_tag_name()
find_elements_by_link_text()
find_elements_by_partial_link_text()
find_elements_by_xpath()
find_elements_by_css_selector()
原文:https://www.cnblogs.com/dmpang/p/9195919.html