1、ELK-ES简介
对于日志来说,最常见的就是收集、存储、查询、展示。对应的有一个开源项目组合:ELKStack。其中包括logstash(日志收集)、elasticsearch(存储+搜索)和kibana(展示)这三个项目。
安装logstash:
# yum install -y java
导入GPG-KEY:
添加yum仓库:
# vim /etc/yum.repos.d/logstash.repo
[logstash-6.x]
name=Elastic repository for 6.x packages
baseurl=https://artifacts.elastic.co/packages/6.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
# yum install -y logstash
# systemctl start logstash
安装ElasticSearch,使用6.x版本的安装包有太多的坑,所以改用2.x版本
————————————————————————————————————————————————————————————————————这是个坑,放弃———————————————————————————————————————————————————————————————————————————————————
tar.gz安装:官网上有现成的压缩包,下载下来解压就完成了。
# tar zxf elasticsearch-6.2.4.tar.gz
然后是配置。配置文件在/etc/elasticsearch/下:
# vim elasticsearch.yml
# ---------------------------------- Cluster -----------------------------------
#
cluster.name: myes //elasticsearch就是分布式的
#
# ------------------------------------ Node ------------------------------------
#
# Use a descriptive name for the node:
#
node.name: linux-node01 //配置节点名称
#
# ----------------------------------- Paths ------------------------------------
#
path.data: /data //配置存储es数据的路径,多个的话可以使用,分隔
#
path.logs: /var/log/elasticsearch/ //日志的路径
#
# ----------------------------------- Memory -----------------------------------
#
bootstrap.memory_lock: true //保证内存不会放入交换分区
#
# ---------------------------------- Network -----------------------------------
#
network.host: 172.16.0.3 //本机IP地址
#
http.port: 9200 //默认端口,不需要修改
#
# --------------------------------- Discovery ----------------------------------
# 这里配置的是集群的各个节点互相发现的方式,有单播或者组播的方式。
然后创建/data目录:
# mkdir /data
接下来启动:
# ./bin/elasticsearch
失败。。。然后查看日志:
# cat /home/es/elasticsearch-6.2.4/logs/myes.log
[2018-05-22T16:03:12,235][ERROR][o.e.b.Bootstrap ] Exception
java.lang.RuntimeException: can not run elasticsearch as root
查看网上解释发现如果是以root权限来执行elasticsearch会有上面的报错。解决方法,创建es用户,然后修改所有相关文件的属主和属组。
# useradd es
# passwd es
# mv ~/elasticsearch-6.2.4 /home/es/
# chown -R es:es /home/es/elasticsearch-6.2.4
# chown -R es:es /data/
然后切换用户启动:
# su - es
$ ./elasticsearch-6.2.4/bin/elasticsearch
接下来又遇到报错:
[2018-05-22T16:32:36,857][WARN ][o.e.b.JNANatives ] Unable to lock JVM Memory: error=12, reason=无法分配内存
[2018-05-22T16:32:36,874][WARN ][o.e.b.JNANatives ] This can result in part of the JVM being swapped out.
[2018-05-22T16:32:36,874][WARN ][o.e.b.JNANatives ] Increase RLIMIT_MEMLOCK, soft limit: 65536, hard limit: 65536
[2018-05-22T16:32:36,875][WARN ][o.e.b.JNANatives ] These can be adjusted by modifying /etc/security/limits.conf, for example:
# allow user ‘elasticsearch‘ mlockall
elasticsearch soft memlock unlimited
elasticsearch hard memlock unlimited
...
[2018-05-22T16:33:28,310][INFO ][o.e.b.BootstrapChecks ] [linux-node1] bound or publishing to a non-loopback address, enforcing bootstrap checks
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65536]
[2]: memory locking requested for elasticsearch process but memory is not locked
[3]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144]
在root用户下修改系统文件:
# vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 131072
* soft memlock unlimited
* hard memlock unlimited
# vim /etc/sysctl.conf
vm.max_map_count=655360
安装kibana和marvel:
由于elasticsearch使用的是6.2.4,这里kibana也应该使用6.2.4版本,同样使用tar包:
$ wget https://artifacts.elastic.co/downloads/kibana/kibana-6.2.4-linux-x86_64.tar.gz
$ tar zxf kibana-6.2.4.linux-x86_64.tar.gz
$ cd /kibana-6.2.4-linux-x86_64/config/kibana.yml //修改IP地址
server.host: "172.16.0.3"
elasticsearch.url: "http://172.16.0.3:9200"
elasticsearch.username: "elastic"
elasticsearch.passsword: "123456” //这个要与后面使用set-password所设置的密码保持一致
logging.dest: /var/log/kibana
# touch /var/log/kibana
# chown -R es:es /var/log/kibana
根据官网的描述,在5.0以后,Marvel插件归入X-Pack,所以这里安装X-Pack:
$ pwd
/home/es
$ ./elasticsearch-6.2.4/bin/elasticsearch-plugin install x-pack
接下来分别启动elasticsearch和kibana
$ ./elasticsearch-6.2.4/bin/elasticsearch -d
$ ./kibana-6.2.4-linux-x86_64/bin/kibana
注意,kibana这里用tar包运行,没有像elasticsearch那么方便直接-d就可以后台运行,所以需要如下的方式:
$ nohup /home/es/kibana-6.2.4-linux-x86_64/bin/kibana &
运行完之后可以看到9200正常监听,然后可以用http://172.16.0.3:9200打开网页,但是这个时候需要输入密码。原因在于安装了X-pack。
$ ./elasticsearch-6.2.4/bin/x-pack/set-passwords ineractive
设置密码。完成之后可以正常打开网页。
安装head插件(集群管理插件):
在6.2.3版本中无法直接通过plugin安装head,可以通过git安装:
$ yum install -y git bzip2 nodejs npm
$ cd elasticsearch-head/
$ npm install
$ vim elastisearch-6.2.4/config/elasticsearch.yml
末尾新增:
http.cors.enable: true
http.cors.allow-origin: "*"
$ vim elasticsearch-head/Gruntifile.js
在快要结尾的位置添加hostname:
options:{
hostname: ‘*‘,
port: 9100,
base: ‘.‘,
keepalive: true
}
$ vim elasticsearch-head/_site/app.js
将localhost改成本机IP:
this.base_uri = this.config.base_uri || this.prefs.get("app-base_uri") || "http://172.16.0.3:9300";
后台启动:
$ cd elasticsearch-head/node_modules/grunt/bin/
$ nohup ./grunt server &
$ netstat -lntup
[root@3-linux-node01 elasticsearch-head]# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::9100 :::* LISTEN 21679/grunt
tcp6 0 0 172.16.0.3:9200 :::* LISTEN 3118/java
可以看到9100正在处于监听状态中,而且使用网页打开http://172.16.0.3:9100可以看到正常显示。
———————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————————
rpm安装:
在网站上找到2.4.6的rpm安装包,然后下载下来上传至虚拟机,之后安装
# wget https://download.elastic.co/elasticsearch/release/org/elasticsearch/distribution/rpm/elasticsearch/2.4.6/elasticsearch-2.4.6.rpm
# rpm --install elasticsearch-2.4.6
配置文件还是和上面一样保持不变,但是/data的权限要变化
# chown -R elasticsearch:elasticsearch /data
# /usr/share/elasticsearch/bin/plugin install marvel-agent
# /usr/share/elasticsearch/bin/plugin install license
# /usr/share/elasticsearch/bin/plugin install mobz/elasticsearch-head
# /usr/share/elasticsearch/bin/plugin install lmenezes/elasticsearch-kopf
# /usr/share/elasticsearch/bin/plugin install hlstudio/bigdesk
# systemctl restart elasticsearch
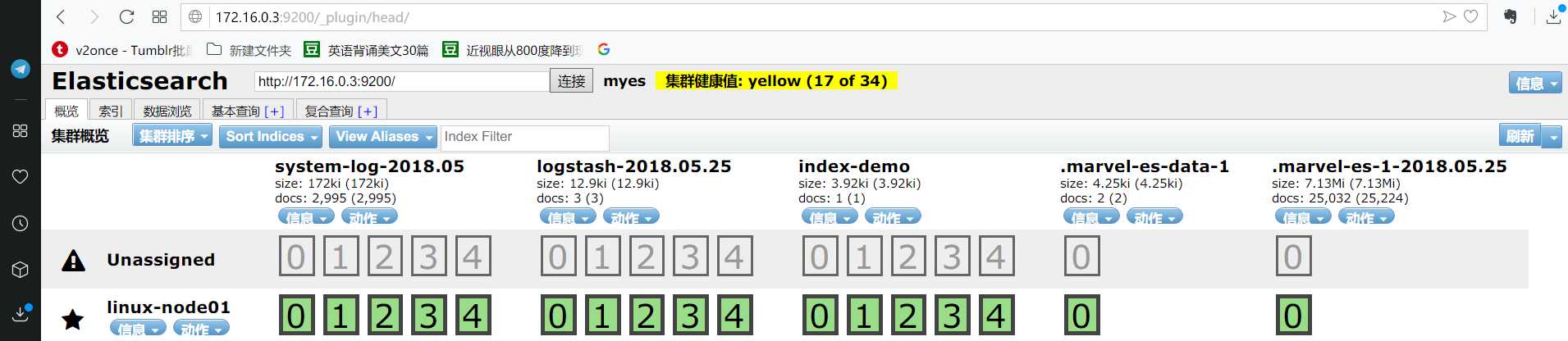
启动完成之后就可以打开网页了:
http://172.16.0.3:9200/_plugin/head/
http://172.16.0.3:9200/_plugin/kopf/#!/cluster
但是日志中有以下错误,先等到6月23日再说吧:
# License will expire on [Saturday, June 23, 2018]. If you have a new license, please update it.
# Otherwise, please reach out to your support contact.
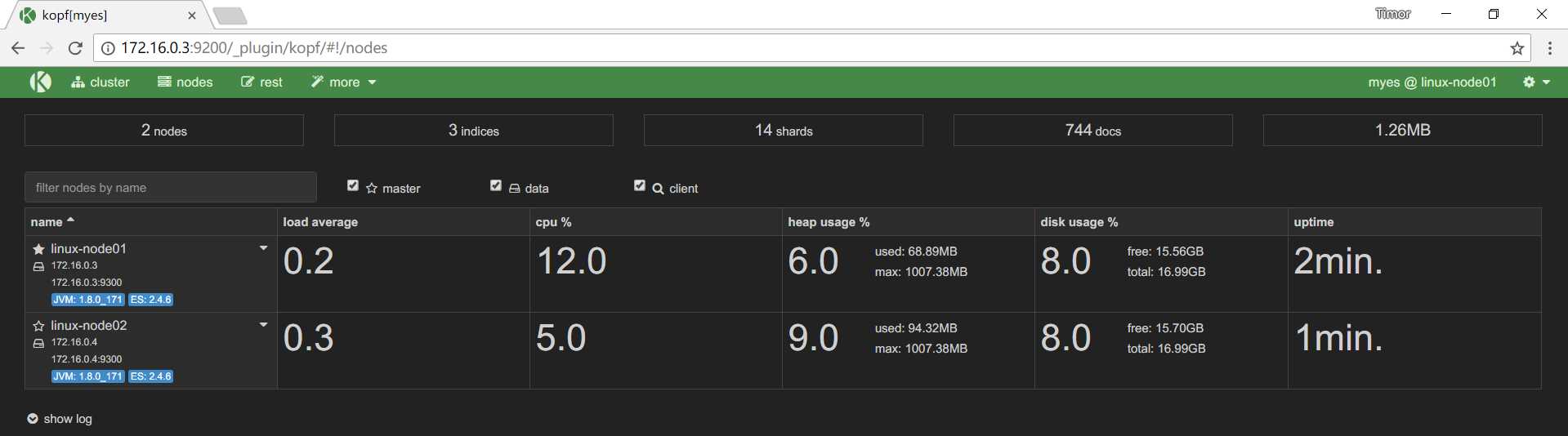
2、ELK-ES集群
启动第二台服务器,地址172.16.0.4。配置文件的集群名称必须一致,主机名则需要不同,IP地址需要修改。
这里不清楚是否是虚拟机故障,集群是靠组播协议发现,所以改成单播发现:
# vim /etc/elasticsearch/elasticsearch.yml
discovery.zen.ping.unicast.hosts: ["172.16.0.3", "172.16.0.4"]
# systemctl restart elasticsearch
之后可以看到两台服务器组成了集群:
所有参与集群的主机都要配置,可以不加自己的地址,但是对方的地址一定是要加的。实心五角星代表着master节点。
安装kibana,这里选择4.6.5版本:
# rpm --install kibana-4.6.5-x86_64.rpm
# vim /opt/kibana/config/kibana.yml
修改配置文件中的url地址为本机地址:
elasticsearch.url: "http://172.16.0.3:9200"
# systemctl start kibana
安装logstash,这里选择5.5.1版本:
# rpm --install logstash-5.5.1.rpm
logstash的实现主要是依赖于插件,核心在于input和output
# /usr/share/logstash/bin/logstash -e ‘input { stdin{} } output { stdout{} }‘
然后遇到一系列问题:
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
WARNING: Could not find logstash.yml which is typically located in $LS_HOME/config or /etc/logstash. You can specify the path using --path.settings. Continuing using the defaults
Could not find log4j2 configuration at path //usr/share/logstash/config/log4j2.properties. Using default config which logs to console
13:37:17.095 [main] INFO logstash.setting.writabledirectory - Creating directory {:setting=>"path.queue", :path=>"/usr/share/logstash/data/queue"}
13:37:17.265 [main] INFO logstash.setting.writabledirectory - Creating directory {:setting=>"path.dead_letter_queue", :path=>"/usr/share/logstash/data/dead_letter_queue"}
13:37:17.840 [LogStash::Runner] INFO logstash.agent - No persistent UUID file found. Generating new UUID {:uuid=>"26451586-698c-48cb-87ca-8a2a80500e9e", :path=>"/usr/share/logstash/data/uuid"}
13:37:22.527 [[main]-pipeline-manager] INFO logstash.pipeline - Starting pipeline {"id"=>"main", "pipeline.workers"=>2, "pipeline.batch.size"=>125, "pipeline.batch.delay"=>5, "pipeline.max_inflight"=>250}
13:37:23.734 [[main]-pipeline-manager] INFO logstash.pipeline - Pipeline main started
The stdin plugin is now waiting for input:
13:37:26.194 [Api Webserver] INFO logstash.agent - Successfully started Logstash API endpoint {:port=>9600}
# ln -s /etc/logstash/ config
# /usr/share/logstash/bin/logstash -e ‘input { stdin{} } output { stdout{} }‘
解决了一部分:
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
Sending Logstash‘s logs to /var/log/logstash which is now configured via log4j2.properties
The stdin plugin is now waiting for input:
3、ELK-Logstash实验
接下来做实验,从标准输入读取,然后输出到es里面去。这里要是用插件elasticsearch,选择版本为v7.3.2:
# /usr/share/logstash/bin/logstash -e ‘input { stdin{} } output { elasticsearch { hosts => [‘172.16.0.3:9200‘] index => "logstash-%{+YYYY.MM.dd}" } }‘
之后输入的内容就可以在elasticsearch上看到了:
将上面的命令写成一个脚本:
# pwd
/usr/share/logstash/config/conf.d
# vim demo.conf
input{
stdin{}
}
filter{
}
output{
stdout{
codec => rubydebug
}
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "logstash-%{+YYYY.MM.dd}"
}
}
之后可以指定启动脚本启动:
# /usr/share/logstash/bin/logstash -f /usr/share/logstash/config/conf.d/demo.conf
这样就可以用启动脚本达成需要的效果了。
启动脚本的写法很简单,包括input、filter和output三个模块,其中filter可以为空。其中的原理需要理解。首先,logstash的读取是按"行"读取,但是大多数情况下我们是希望按"事件"读取,比如一条日志包含若干行,那么我们肯定是希望这一条日志的所有行被显示在一条日志中,而不是有多少行就显示多少条日志。其次,logstash在这个过程中相当于从input得到日志,经过codec编码之后,再经过filter过滤日志,然后经过codec解码之后再由output输出日志。每个模块都有自己的成对的{},数组则使用[],字符串则使用""。
discover_interval:logstash 每隔多久去检查一次被监听的 path 下是否有新文件。默认值是 15 秒。
exclude:不想被监听的文件可以排除出去,这里跟 path 一样支持 glob 展开。
sincedb_path:sincedb文件是用于存储Logstash读取文件的位置,每行表示一个文件,每行有两个数字,第一个表示文件的inode,第二个表示文件读取到的位置(byteoffset),默认为$HOME/.sincedb*(Windows 平台上在 C:\Windows\System32\config\systemprofile\.sincedb),文件名是日志文件路径MD5加密后的结果。sincedb_path只能指定为具体的file文件,不能是path目录。
sincedb_write_interval:logstash 每隔多久写一次 sincedb 文件,默认是 15 秒。
stat_interval:logstash 每隔多久检查一次被监听文件状态(是否有更新),默认是 1 秒。
start_position:logstash 从什么位置开始读取文件数据,默认是结束位置,也就是说 logstash 进程会以类似 tail -F 的形式运行。如果你是要导入原有数据,把这个设定改成 "beginning",logstash 进程就从头开始读取,有点类似 cat,但是读到最后一行不会终止,而是继续变成 tail -F。
接下来再做一个实验,收集系统日志:
# vim file.conf
input{
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
}
}
filter{
}
output{
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "system-log-%{+YYYY.MM}"
}
}
# /usr/share/logstash/bin/logstash -f /usr/share/logstash/config/conf.d/file.conf
可以看到system-log的相关信息已经出来了。
4、ELK-Kibana简单使用
kibana为ELK的一个模块,为用户提供可视化界面。4.6.5版本。
# wget https://download.elastic.co/kibana/kibana/kibana-4.6.5-x86_64.rpm
# rpm --install kibana-4.6.5-x86_64.rpm
# vim /opt/kibana/config/kibana.yml
elasticsearch.url: "http://172.16.0.3:9200"
kibana.index: ".kibana"
# systemctl enable kibana
# systemctl start kibana
# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 63193/node
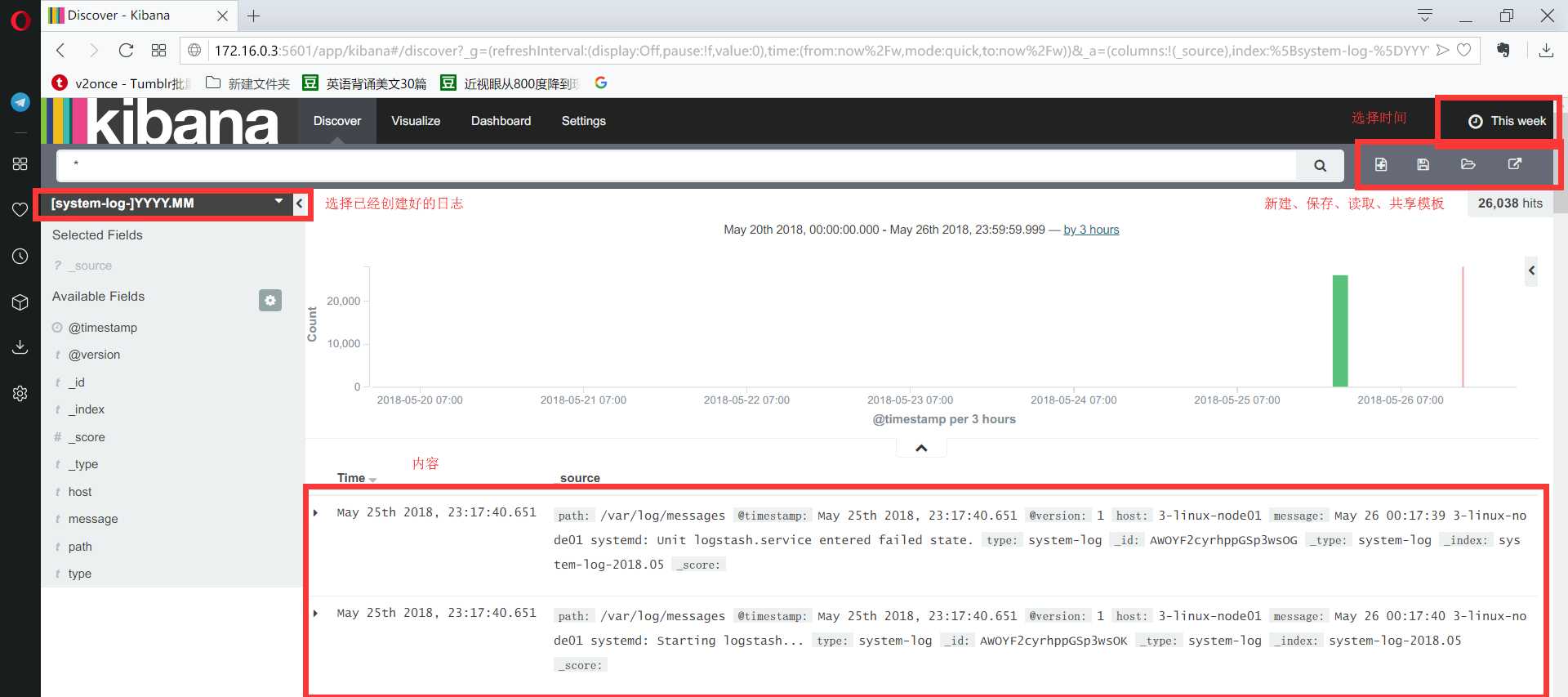
打开网页之后,默认会在setting页面,kibana会引导设置第一个监控页面。通过选择时间戳或者输入名称可以对已经设置了的日志文件进行匹配然后直接读取。之后就可以在discover页面进行搜索了。需要注意的是,kibana不会自己去发现日志,所以必须通过setting进行手动添加才能读出来。同时,也会给被读取的文件记录下一个叫.sincedb的隐藏文件,如果不想使用默认的$HOME/.sincedb,可以自己通过sincedb_path来定义路径。
5、ELK-Logstash-Input-if判断
设计收集elasticsearch的日志myes.log,先按照以前的老方法配置:
[root@3-linux-node01 ~]# vim /usr/share/logstash/config/conf.d/file.conf
input{
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
}
file{
path => "/var/log/elasticsearch/myes.log"
type => "es-log"
start_position => "beginning"
}
}
filter{
}
output{
if [type] == "system-log" {
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "system-log-%{+YYYY.MM}"
}
}
if [type] == "es-log" {
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "es-log-%{+YYYY.MM}"
}
}
}
# /usr/share/logstash/bin/logstash -f /usr/share/logstash/config/conf.d/file.conf
总是会遇到报错:
[2018-05-26T18:34:17,069][FATAL][logstash.runner ] Logstash could not be started because there is already another instance using the configured data directory. If you wish to run multiple instances, you must change the "path.data" setting.
这里是要运行多实例,修改启动命令:
# /usr/share/logstash/bin/logstash -f /usr/share/logstash/config/conf.d/file.conf --path.data /data/
启动之后可以看到已经开始出现日志,但是显示出现了"行"与"事件"的情况:
实际的日志:
[2018-05-26 18:00:06,384][WARN ][transport.netty ] [linux-node01] exception caught on transport layer [[id: 0x9fb06663]], closing connection
at sun.nio.ch.SocketChannelImpl.checkConnect(Native Method)
at sun.nio.ch.SocketChannelImpl.finishConnect(SocketChannelImpl.java:717)
at org.jboss.netty.channel.socket.nio.NioClientBoss.connect(NioClientBoss.java:152)
at org.jboss.netty.channel.socket.nio.NioClientBoss.processSelectedKeys(NioClientBoss.java:105)
at org.jboss.netty.channel.socket.nio.NioClientBoss.process(NioClientBoss.java:79)
at org.jboss.netty.channel.socket.nio.AbstractNioSelector.run(AbstractNioSelector.java:337)
at org.jboss.netty.channel.socket.nio.NioClientBoss.run(NioClientBoss.java:42)
at org.jboss.netty.util.ThreadRenamingRunnable.run(ThreadRenamingRunnable.java:108)
at org.jboss.netty.util.internal.DeadLockProofWorker$1.run(DeadLockProofWorker.java:42)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)
而收集到的日志(从下往上看):
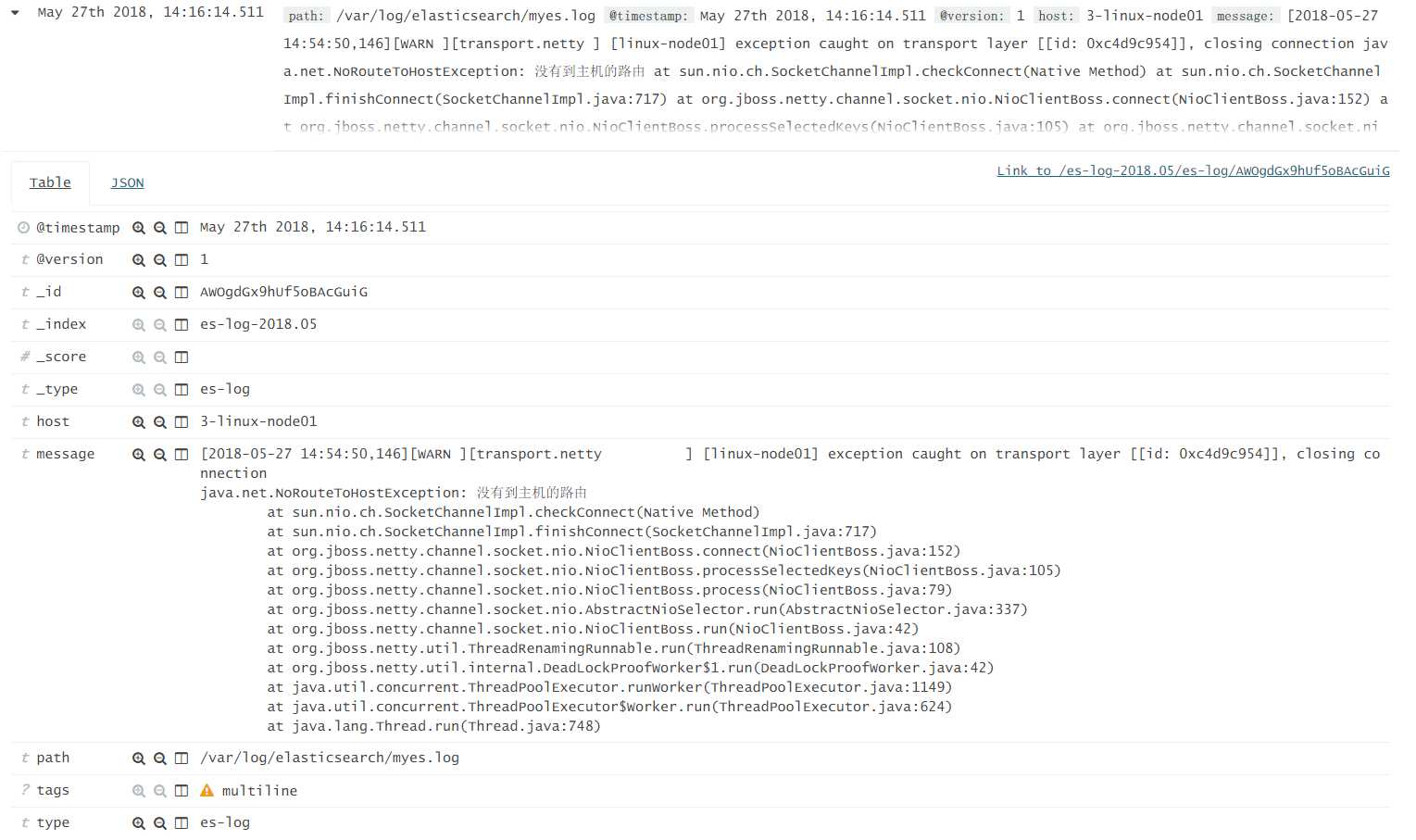
实际上虽然日志没有漏下,但是将一条日志采集成了多条日志,即logstash是按照"行"进行的采集。那么这个不是我所期望的,因此需要将其改成按"事件"进行采集。
6、ELK-Logstash-Codec-multiline
先插一个小知识点,搜索的语法:
接下来解决上面说的按"行"收集日志的问题,这里就需要用到multiline插件了。
filter {
multiline {
pattern => "pattern, a regexp" //可以支持正则表达式
negate => boolean
what => "previous" or "next"
}}
先来演示一下用法:
使用正则表达式匹配以"["开头的行,两个以"["开头的行中间的内容,就会被认为是一个"事件",记录并且输出出来,换行符会以\n记录下来。
# vim odec.conf
input{
stdin{
codec => multiline{
pattern => "^\["
negate => true
what => "previous"
}
}
}
filter{
}
output{
stdout{
codec => rubydebug
}
}
# /usr/share/logstash/bin/logstash -f codec.conf --path.data /data/
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
Sending Logstash‘s logs to /var/log/logstash which is now configured via log4j2.properties
The stdin plugin is now waiting for input:
[hjashfasj
dsajcbajs
dashidhasn
[
{
"@timestamp" => 2018-05-26T18:02:46.631Z,
"@version" => "1",
"host" => "3-linux-node01",
"message" => "[hjashfasj\ndsajcbajs\ndashidhasn",
"tags" => [
[0] "multiline"
]
}
接下来修改正式的启动配置文件:
# vim /usr/share/logstash/config/conf.d/file.conf
input{
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
}
file{
path => "/var/log/elasticsearch/myes.log"
type => "es-log"
start_position => "beginning"
codec => multiline{ //加上这一段
pattern => "^\["
negate => true
what => "previous"
}
}
}
filter{
}
output{
if [type] == "system-log" {
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "system-log-%{+YYYY.MM}"
}
}
if [type] == "es-log" {
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "es-log-%{+YYYY.MM}"
}
}
}
之后启动logstash,发现日志已经按"事件"来进行采集了:
接下来是sincedb的一些实验:
file{
path => ["/var/log/messages","/var/log/secure"]
type => "system-log"
start_position => "beginning"
sincedb_path => "/data/.sincedb_mes_sec"
}
可以看到有文件显示出来:
[root@3-linux-node01 data]# ls -a
. .. dead_letter_queue .lock myes plugins queue .sincedb_ela .sincedb_mes_sec uuid
[root@3-linux-node01 data]# cat .sincedb_ela
17180165 0 64768 47540
[root@3-linux-node01 data]# ll -i /var/log/elasticsearch/myes.log
17180165 -rw-r--r-- 1 elasticsearch elasticsearch 48029 5月 27 17:00 /var/log/elasticsearch/myes.log
7、ELK-Logstash-Codec-json
对于某些日志,如果显示成一团会影响阅读,这个时候就要是用到json插件了。比如Nginx。
方法1、nginx日志改成json输出:
对nginx配置文件的日志格式以及读取方式做如下修改:
log_format access_log_json ‘{"user_ip":"$http_x_real_ip","lan_ip":"$remote_addr","log_time":"$time_iso8601","user_req":"$request","http_code":"$status","body_bytes_sent":"$body_bytes_sent","req_time":"$request_time","user_ua":"$http_user_agent"}‘;
access_log /var/log/nginx/access_log_json.log access_log_json;
之后写配置文件:
input{
file{
path => "/var/log/nginx/access_log_json.log"
codec => "json"
}
}
filter{
}
output{
elasticsearch{
hosts => ["172.16.0.3:9200"]
index => "nginx-access-log-%{+YYYY.MM.dd}"
}
stdout{
codec => rubydebug
}
}
加与不加json的区别在于:
{
"path" => "/var/log/nginx/access_log_json.log",
"@timestamp" => 2018-05-28T07:45:57.070Z,
"@version" => "1",
"host" => "4-linux-node02",
"message" => "{\"user_ip\":\"-\",\"lan_ip\":\"172.16.0.4\",\"log_time\":\"2018-05-28T15:45:56+08:00\",\"user_req\":\"GET / HTTP/1.0\",\"http_code\":\"200\",\"body_bytes_sent\":\"612\",\"req_time\":\"0.000\",\"user_ua\":\"ApacheBench/2.3\"}"
}
和
{
"user_ip" => "-",
"path" => "/var/log/nginx/access_log_json.log",
"@timestamp" => 2018-05-28T07:47:02.448Z,
"http_code" => "200",
"body_bytes_sent" => "612",
"lan_ip" => "172.16.0.4",
"user_req" => "GET / HTTP/1.0",
"@version" => "1",
"host" => "4-linux-node02",
"user_ua" => "ApacheBench/2.3",
"log_time" => "2018-05-28T15:46:44+08:00",
"req_time" => "0.000"
}
可以达成的效果:
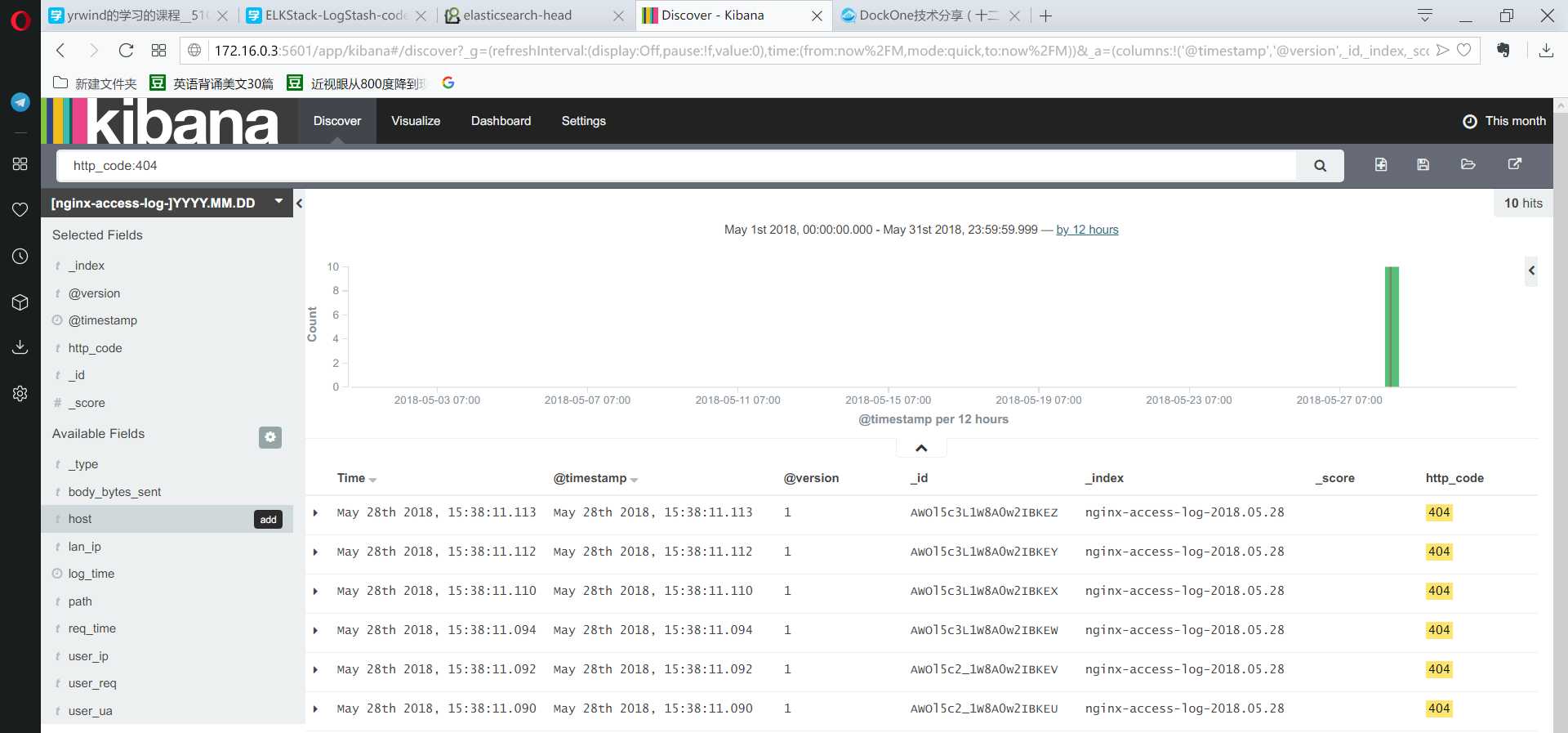
可以在左侧选择需要查看的选项,如果不选择默认则是全部显示成一条,这就是json的应用。对于http请求以及响应,可能只是去搜索其中一个字段,比如http_code,这样可以更加简洁明了的显示出来。
方法2、文件直接收取进redis,然后是用Python脚本读取redis,写成json后写入ES。
十三、ELKStack(下)
1、ELK-kibana图形化
kibana可以支持可视化,用不同的图形和模块来实现:
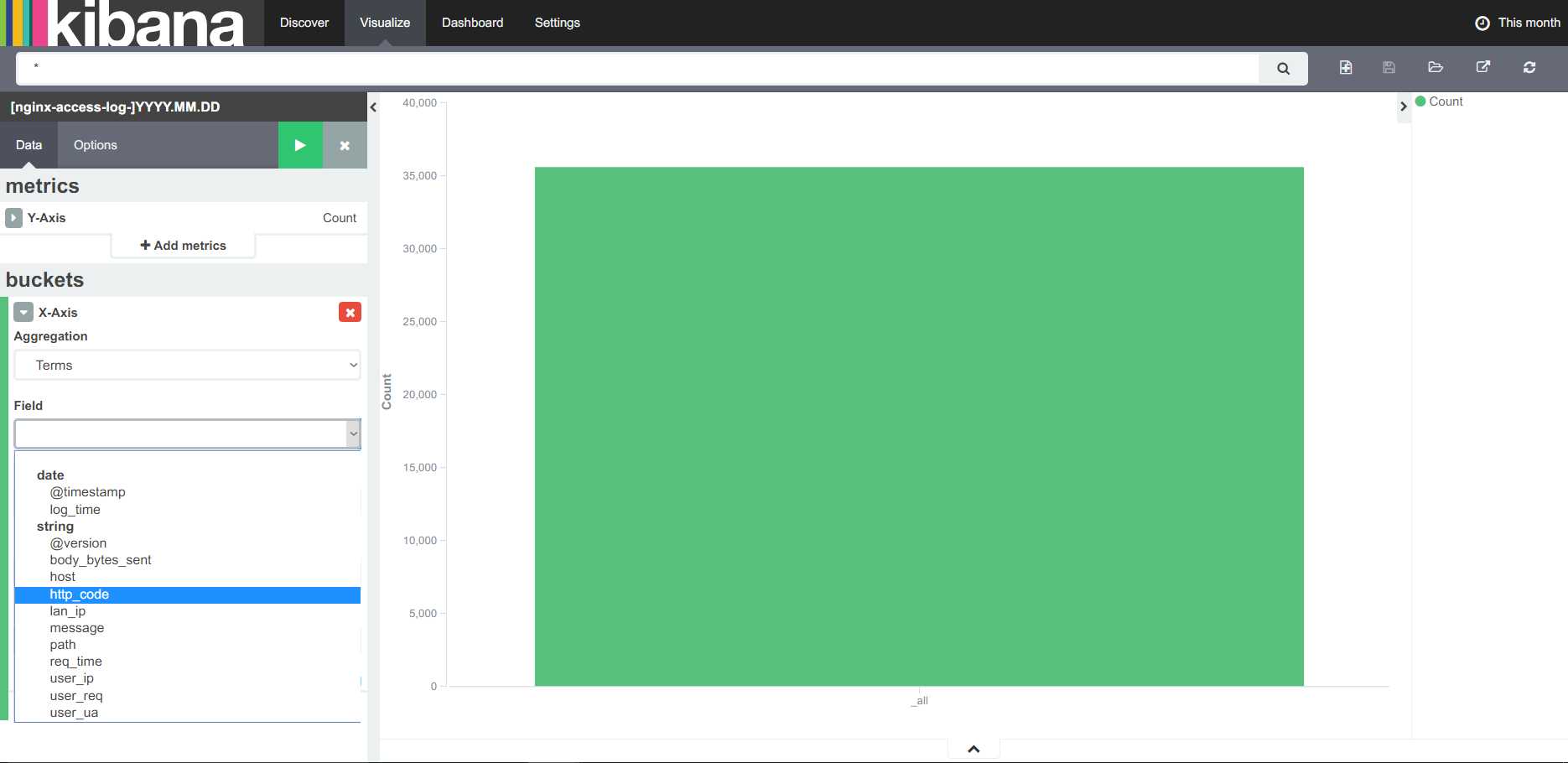
这里使用Markdown,metric和vertical bar还有搜索方案来做一个面板:
选择nginx-access-log作为源,之后可以选择不同的模块进行监控:
之后保存:
之后在面板上添加:
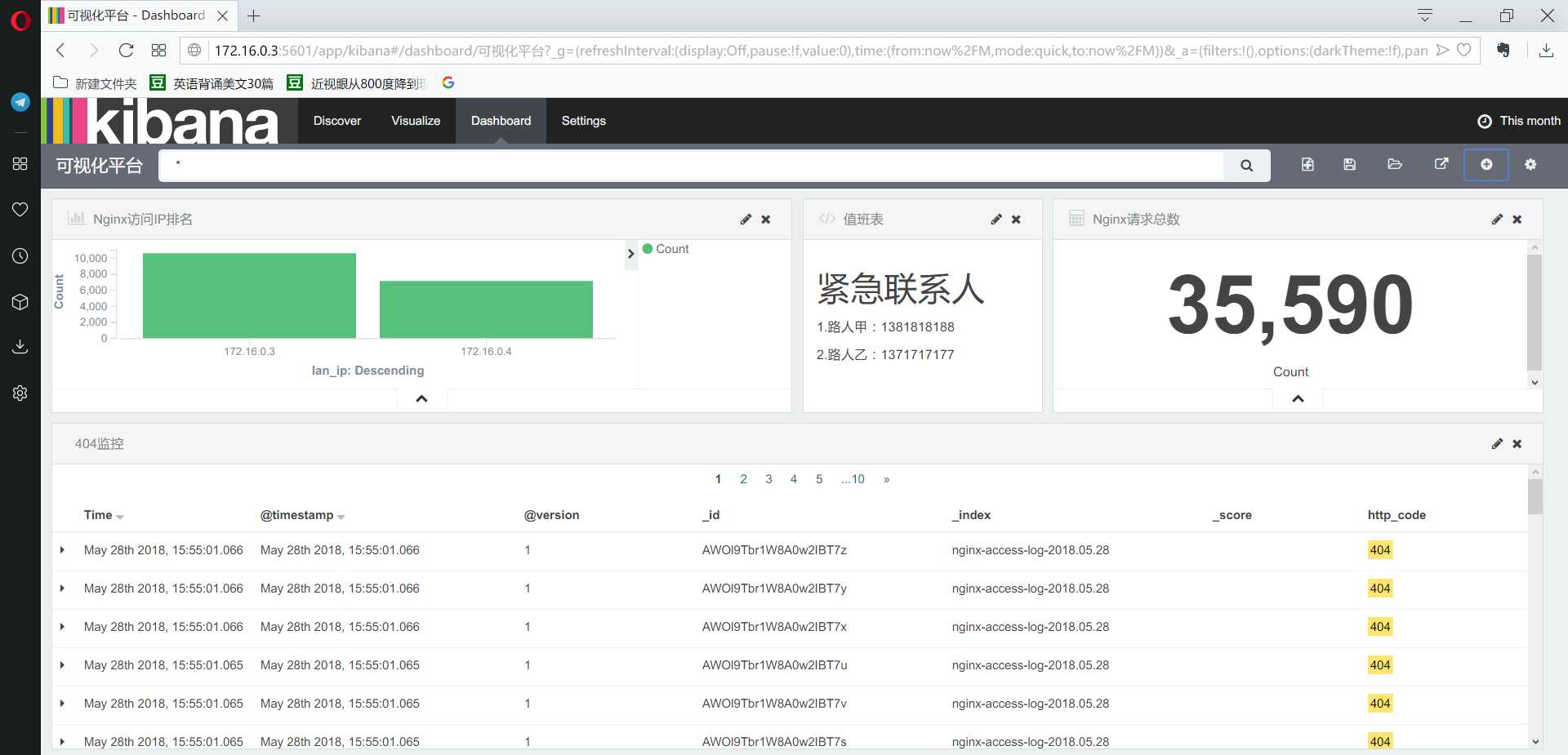
达到最终的效果:
对之前的搜索同样使用,显示的模块为搜索的结果。
2、ELK-LogStash实战-input插件rsyslog
Rsyslog是一个input插件,使用514端口。远端的机器会将日志信息发送至logstash监听的514端口,logstash通过监听514端口来获取对应的日志信息,达到搜集日志的目的。
编辑启动测试脚本:
# vim /etc/logstash/conf.d/syslog.conf
input{
syslog{
type => "system-syslog"
port => "514"
}
}
filter{
}
output{
stdout{
codec => rubydebug
}
}
# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::514 :::* LISTEN 1889/java
udp6 0 0 :::514 :::* 1889/java
修改被采集syslog的主机(172.16.0.3)的rsyslog配置文件:
# vim /etc/rsyslog.conf
# remote host is: name/ip:port, e.g. 192.168.0.1:514, port optional
*.* @@172.16.0.4:514 //改成远端主机的IP地址
小知识点:
# The authpriv file has restricted access.
authpriv.* /var/log/secure
# Log all the mail messages in one place.
mail.* -/var/log/maillog
在路径前面加一个-表示不立即生效。
# systemctl restart rsyslog
重启之后就可以在远端主机(172.16.0.4)上看到有日志更新出来了
接下来修改测试脚本为正式脚本:
# vim syslog.conf
input{
syslog{
type => "system-syslog"
port => "514"
}
}
filter{
}
output{
elasticsearch{
hosts => ["172.16.0.4:9200"]
index => "system-syslog-%{+YYYY.MM}"
}
}
跑起来之后虽然kibana的显示无误,但是始终在报错如下:
[2018-05-28T21:33:18,154][INFO ][logstash.inputs.syslog ] Starting syslog udp listener {:address=>"0.0.0.0:514"}
[2018-05-28T21:33:18,156][WARN ][logstash.inputs.syslog ] syslog listener died {:protocol=>:udp, :address=>"0.0.0.0:514", :exception=>#<Errno::EADDRINUSE: Address already in use - bind - ?°??·2?¨????¨>, :backtrace=>["org/jruby/ext/socket/RubyUDPSocket.java:161:in `bind‘", "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-syslog-3.2.1/lib/logstash/inputs/syslog.rb:141:in `udp_listener‘", "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-syslog-3.2.1/lib/logstash/inputs/syslog.rb:122:in `server‘", "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-syslog-3.2.1/lib/logstash/inputs/syslog.rb:102:in `run‘"]}
[2018-05-28T21:33:18,165][INFO ][logstash.inputs.syslog ] Starting syslog tcp listener {:address=>"0.0.0.0:514"}
[2018-05-28T21:33:18,167][WARN ][logstash.inputs.syslog ] syslog listener died {:protocol=>:tcp, :address=>"0.0.0.0:514", :exception=>#<Errno::EADDRINUSE: Address already in use - bind - ?°??·2?¨????¨>, :backtrace=>["org/jruby/ext/socket/RubyTCPServer.java:118:in `initialize‘", "org/jruby/RubyIO.java:871:in `new‘", "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-syslog-3.2.1/lib/logstash/inputs/syslog.rb:159:in `tcp_listener‘", "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-syslog-3.2.1/lib/logstash/inputs/syslog.rb:122:in `server‘", "/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-input-syslog-3.2.1/lib/logstash/inputs/syslog.rb:106:in `run‘"]}
结合启动日志发现tcp和udp都在监听同一个端口,怀疑可能是由于这个原因引起:
[2018-05-28T21:43:39,451][INFO ][logstash.inputs.syslog ] Starting syslog udp listener {:address=>"0.0.0.0:514"}
[2018-05-28T21:43:39,555][INFO ][logstash.inputs.syslog ] Starting syslog tcp listener {:address=>"0.0.0.0:514"}
3、ELK-LogStash实战-input插件tcp
TCP可以用来实现抓取tcp对应端口的日志文件。
# vim tcp.conf
input{
tcp{
type = "tcp"
port => "6666"
mode => "server"
}
}
filter{
}
output{
stdout{
codec => rubydebug
}
}
# /usr/share/logstash/bin/logstash -f tcp.conf --path.data /data
执行完成后可以看到java监听的6666端口:
# netstat -lntup
Active Internet connections (only servers)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp6 0 0 :::6666 :::* LISTEN 5676/java
测试一下:
# echo "hehe" | nc 172.16.0.4 6666
收到消息:
{
"@timestamp" => 2018-05-30T10:08:17.088Z,
"port" => 40620,
"@version" => "1",
"host" => "172.16.0.3",
"message" => "hehe",
"type" => "tcp"
}
小技巧:
# nc 172.16.0.4 6666 < test.txt
# echo "hehe1" > /dev/tcp/172.16.0.4/6666
4、ELK-LogStash实战-filter插件grok
对于Apache的日志,不能支持json插件,可以使用filter的grok插件完成。
写配置文件:
# cat grok.conf
input{
stdin {}
}
filter{
grok{
match => { "message" => "%{IP:client} %{WORD:method} %{URIPATHPARAM:request} %{NUMBER:bytes} %{NUMBER:duration}" }
}
}
output{
stdout {
codec => rubydebug
}
}
验证效果:
# /usr/share/logstash/bin/logstash -f grok.conf --path.data /data
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
Sending Logstash‘s logs to /var/log/logstash which is now configured via log4j2.properties
The stdin plugin is now waiting for input:
55.3.244.1 GET /index.html 15824 0.043
{
"duration" => "0.043",
"request" => "/index.html",
"@timestamp" => 2018-05-30T13:17:37.564Z,
"method" => "GET",
"bytes" => "15824",
"@version" => "1",
"host" => "3-linux-node01",
"client" => "55.3.244.1",
"message" => "55.3.244.1 GET /index.html 15824 0.043"
}
达到这样的效果之后就可以正常的将结果输出到es中去了。但是需要注意的是,grok很吃性能,如果不是很懂ruby的话,那么grok就不灵活。
5、ELK-LogStash实战-采集Apache日志
一般情况下是不会用到grok去采集的,缺点上面说了。对于传参数量巨大(甚至可能是攻击)grok就不行了,有使用logstash将日志抓去redis,然后使用python脚本将日志过滤之后导入es。
但是学了可以实践一下,grok会自带一些参数可以直接调用,具体路径如下:
# pwd
/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns
# ls
aws exim httpd maven nagios ruby
bacula firewalls java mcollective postgresql squid
bind grok-patterns junos mcollective-patterns rails
bro haproxy linux-syslog mongodb redis
这里需要使用到grok-patterns文件,但是在当前版本中似乎没有apache的日志格式,所以可以手动添加:
# Log formats
SYSLOGBASE %{SYSLOGTIMESTAMP:timestamp} (?:%{SYSLOGFACILITY} )?%{SYSLOGHOST:logsource} %{SYSLOGPROG}:
COMMONAPACHELOG %{IPORHOST:clientip} %{HTTPDUSER:ident} %{USER:auth} \[%{HTTPDATE:timestamp}\] "(?:%{WORD:verb} %{NOTSPACE:request}(?: HTTP/%{NUMBER:httpversion})?|%{DATA:rawrequest})" %{NUMBER:response} (?:%{NUMBER:bytes}|-)
COMBINEDAPACHELOG %{COMMONAPACHELOG} %{QS:referrer} %{QS:agent}
书写启动文件:
# vim apache_log.conf
input{
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter{
grok{
match => { "message" => "%{COMMONAPACHELOG}" }
}
}
output{
stdout{
codec => rubydebug
}
}
可以看到访问结果:
{
"request" => "/",
"auth" => "-",
"ident" => "-",
"verb" => "GET",
"message" => "172.16.0.1 - - [31/May/2018:15:55:14 +0800] \"GET / HTTP/1.1\" 200 13 \"-\" \"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3359.170 Safari/537.36 OPR/53.0.2907.68\"",
"path" => "/var/log/httpd/access_log",
"@timestamp" => 2018-05-31T07:55:15.030Z,
"response" => "200",
"bytes" => "13",
"clientip" => "172.16.0.1",
"@version" => "1",
"host" => "4-linux-node02",
"httpversion" => "1.1",
"timestamp" => "31/May/2018:15:55:14 +0800"
}
之后就可以使用output将日志写去es中
# vim apache_log.conf
input{
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter{
grok{
match => { "message" => "%{COMMONAPACHELOG}" }
}
}
output{
elasticsearch {
hosts => ["172.16.0.4:9200"]
index => "apache-%{+YYYY.MM.dd}"
}
}
看看kibana:
正常显示
6、ELK-使用消息队列扩展
线上环境出了使用插件完成日志收集之外,还可以使用消息队列。logstash进行采集至redis,然后通过消息队列处理之后再发给logstash。这里就学习一下怎么通过插件将日志送入redis。
配置文件:
# vim redis.conf
input{
stdin{
}
}
filter{}
output{
redis{
host => "172.16.0.4"
port => "6379"
db => "6"
data_type => "list"
key => "demo"
}
}
# vim /etc/redis.conf
...
bind 172.16.0.4
...
daemonize yes
...
# /usr/share/logstash/bin/logstash -f /usr/share/logstash/config/conf.d/redis.conf --path.data /data
ERROR StatusLogger No log4j2 configuration file found. Using default configuration: logging only errors to the console.
Sending Logstash‘s logs to /var/log/logstash which is now configured via log4j2.properties
The stdin plugin is now waiting for input:
disahdioashd //随便输入4行
dsaihfashfa
dshiacvash
dssjiadh
然后去172.16.0.4上面看redis:
172.16.0.4:6379> info
# Keyspace
db0:keys=1,expires=0,avg_ttl=0
db6:keys=1,expires=0,avg_ttl=0 //有db6产生
172.16.0.4:6379> select 6
OK
172.16.0.4:6379[6]> KEYS *
1) "demo"
172.16.0.4:6379[6]> LLEN demo
(integer) 4
172.16.0.4:6379[6]> LINDEX demo -1
"{\"@timestamp\":\"2018-06-01T03:26:17.080Z\",\"@version\":\"1\",\"host\":\"3-linux-node01\",\"message\":\"dssjiadh\"}"
可以看到demo里面的值和输入的值相同。
然后写实际应用的脚本:
# vim apache.conf
input{
file {
path => "/var/log/httpd/access_log"
start_position => "beginning"
}
}
filter{
}
output{
redis{
host => "172.16.0.4"
port => "6379"
db => "7"
data_type => "list"
key => "apache-accesslog"
}
}
接下来再从redis中读出来,写入es中去。结合前几章的内容,apache的日志需要经过grok的处理才可以写入es,所以需要些filter了。
# vim index.conf
input{
redis{
host => "172.16.0.4"
port => "6379"
db => "7"
data_type => "list"
key => "apache-accesslog"
}
}
filter{
grok{
match => { "message" => "%{COMMONAPACHELOG}" }
}
}
output{
elasticsearch {
hosts => ["172.16.0.3:9200"]
index => "apache-%{+YYYY.MM.dd}"
}
}
之后同时运行apache.conf和index.conf,就可以看到redis里面没有了,而出现在es中了。
ELK学习笔记
原文:https://www.cnblogs.com/teezzy/p/9121579.html