1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
先启动dfs
上传下载的英文小说

创建表world

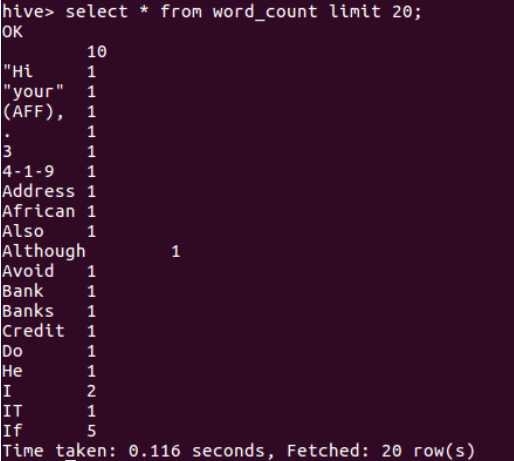
进行HQL词频统计,将结果放到word_count中

查找表的前二十条记录
2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
将csv文件上传到hdfs中的gigdatacase

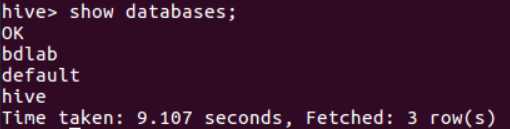
显示数据库
创建初始表

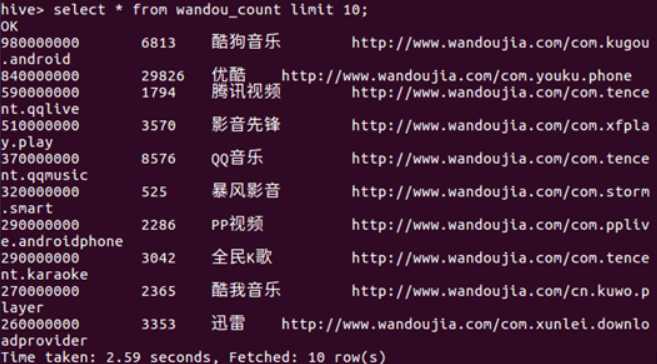
导入数据

显示前十行的数据
原文:https://www.cnblogs.com/wlh0329/p/9085714.html